
经过2023年的发展,大语言模型展示出了非常大的潜力,训练越来越大的模型成为有效性评估的一个关键指标,论文《A Comparative Analysis of Fine-Tuned LLMs and Few-Shot Learning of LLMs for Financial Sentiment Analysis》中,作者全面分析了微调大语言模型(llm)及其在金融情绪分析中的零样本和少样本的能力。
作者通过使用两种方法来探索金融情绪分析背景下的潜力和适用性:
- 在特定的领域(金融领域)的数据集上,使用小语言模型进行微调,作者测试了250M到3B参数各种模型
- 以gpt-3.5 turbo为重点的情境学习
作者还将结果与SOTA(最先进的)模型进行比较以评估其性能,我们看看小模型是否还同样有效。
论文证明了以下观点:
- 微调较小的llm可以达到与SOTA微调llm相当的性能。
- 零样本和少样本学习的的性能与经过微调的小型llm相当。
- 增加上下文学习中的样本数量并不一定会提高情感分析任务的性能。
- 微调较小的llm会降低成本和提高计算效率。
作者专注于使用QLoRa (Quantized low - rank - adaptive)机制对FLAN-T5模型进行微调。使用财务特定数据集,研究了3种尺寸:Flan-T5 base (250M), Flan-T5 large (780M)和Flan-T5-xl (3B参数)。
论文概述
论文首先总结了特定于金融领域的SOTA模型:
- FinBERT:使用总计4.9B Token组的金融通信语料库进行微调的BERT。
- bloomberg ggpt:这是一个包含50B个参数的闭源模型,专门针对各种金融数据进行训练。它在情感分析中表现出良好的性能。
- 使用LLama-7B对FinGPT进行微调。该模型使用更少的计算资源实现了与bloomberg ggpt相当的性能。
- ChatGPT这样的llm也可以使用零样本学习。但是他们在少样本学习中表现并不理想
作者使用了以下模型:
1、没有进行任何微调:Flan-T5 base (250M), Flan-T5 large (780M), Flan-T5-xl (3B参数),ChatGPT (gpt-3.5 turbo)。目标是研究模型的大小对零样本和少样本学习的影响。
2、微调llm:具有3个尺寸的相同型号的Flan-T5已经进行了微调。
数据集
使用了Twitter财经新闻(Twitter Train),包括与金融主题相关的推文,可通过HuggingFace访问。它包含9540个样本。
TFSN: 2390个带有注释的财经相关推文语料库样本。
FPB: 4845篇金融新闻文章样本,由16位领域专家注释。
GPU资源
为了对3个模型进行微调,作者使用了A100 GPU,每个模型的总训练时间如下:基本模型28分钟,大模型54分钟,XL模型65分钟,所以说这个微调是非常节省资源的。
微调小型LLMs
结果显示了经过微调的小型llm优于大型llm的性能:

所有Fine-tuned-FLAN-T5的性能都优于FinBERT;Large (780M)和XL(3B) fine - tuning - flan - t5性能优于directive - lama- 7b;在TFSN数据集中,即使是基础(250M)微调的flan - t5也比使用ChatGPT (gpt-3.5 turbo)的k-shot上下文学习表现更好。
少样本学习
以下是0 -shot和k-shot学习的结果(k= 1,5和10):
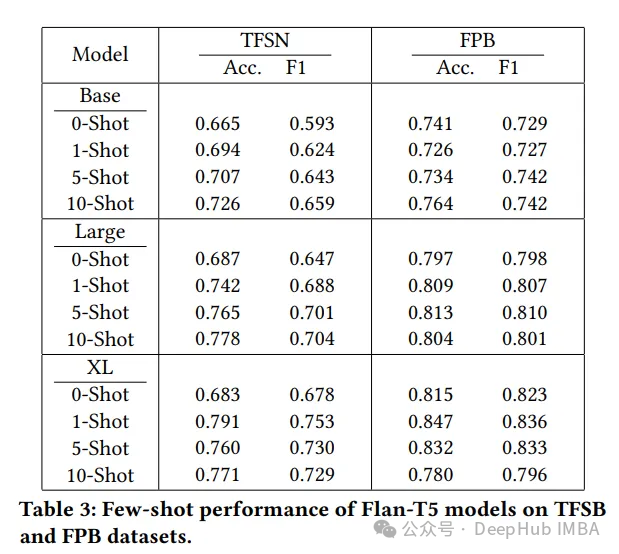
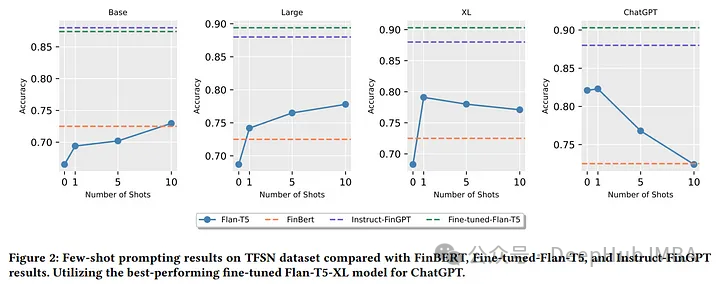
在TFSN数据集上,零样本和少样本学习的表现明显低于所有其他微调模型。(除了XL,表现比FinBert稍好)
但是在FPB数据集中,与ChatGPT相比,Large和XL Flan-T5零样本和少样本学习表现出较强的性能。
样本的增加使得基本型Flan-T5的性能略有提升。但在Large和XL fall - t5中,这导致精度下降。这是因为冗长的上下文窗口可能会导致LLM误入歧途。
所以作者建议,当k-shot增加时可以使用语义相似检索或思维链(CoT)或线索和推理提示(CARP)方法来解决性能下降的问题。
总结
可以看到,针对特定的领域,微调小模型还是能过够得到很好的效果,这在对于我们实际应用是是非常有帮助的,不仅可以节省成本,还可以节省我们的训练时间,可以让我们进行快速的版本迭代。
论文地址:
https://arxiv.org/pdf/2312.08725.pdf
作者:Hanane Dupouy