
这篇论文总结了现有LLM在金融领域的应用现状,推荐和金融相关或者有兴趣的朋友都看看
论文分为2大部分:
1、作者概述了使用llm的现有方法
包括使用零样本或少样本的预训练模型,对特定于领域的数据进行微调,还有从头开始训练定制llm,并给出了关键模型的总结与评价。
2、根据给定的用例、数据约束、计算和性能需求,提出决策框架,指导选择合适的LLM解决方案,这是这篇论文可以好好阅读的地方,因为论文还对在金融领域使用LLM的局限性和挑战提出了一些见解。
论文从总结语言模型架构经历了重大的演变开始:
1、从n-gram模型中,下一个单词的概率完全取决于前面的(n-1)个单词
2、以RNN为基础的模型,如LSTM或GRU,神经网络架构,捕获序列数据中的长期依赖关系。
3、2017年,Transformer架构标志着语言模型的革命,在翻译等任务中表现优于rnn,并且梳理了一些著名模型:
GPT(Generative Pretrained Transformer):一个仅用于编码器的框架,以其在生成连贯文本方面的有效性而闻名。
BERT(Bidirectional Encoder Representations from Transformers):一个仅用于解码器的框架,擅长从文本的两个方向理解上下文。
T5 (Text-to-Text Transfer Transformer):采用编码器和解码器两种结构,拓宽了应用范围,最著名的就是翻译任务。
在金融领域的应用概述
论文整理了各种人工智能应用:如交易和投资组合管理、金融风险建模、金融文本挖掘、咨询和客户服务。
1、交易和投资组合管理:
基于进化优化技术分析参数的深度神经网络股票交易系统。https://doi.org/10.1016/j.procs.2017.09.031
时间序列中的Transformers :https://arxiv.org/abs/2202.07125
采用强化学习的动态投资组合管理。https://arxiv.org/abs/1911.11880
2、金融风险建模:
金融欺诈检测、信用评分和破产预测,比如肯锡公司基于深度学习的欺诈检测解决方案。
3、金融文本挖掘:
从大规模非结构化数据中提取有价值的信息,用于交易和风险建模中的知情决策。
利用新闻文章中的金融市场情绪分析进行股票市场预测。https://doi.org/10.3390/math10132156
4、财务谘询及客户服务:
人工智能聊天机器人为电子商务和电子服务提供了大量支持。摩根大通正在开发一种类似chatgpt的人工智能服务,可以提供投资建议。
基于LLM的金融解决方案
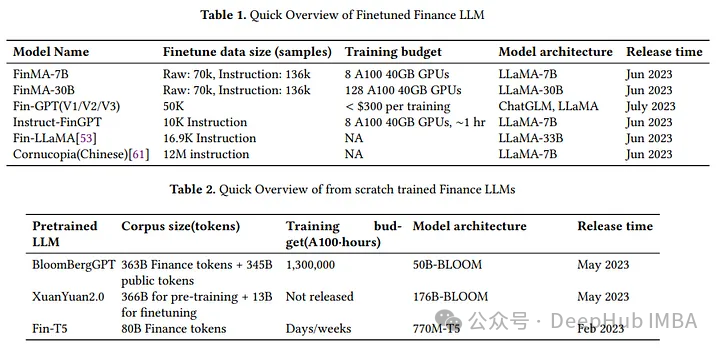
1、使用开源/专有模型的零/少样本学习:
微调llm: PIXIU (FinMA), LLama, FinGPT, directive -FinGPT
与原始基础开源llm相比微调llm在所有金融领域任务上表现出比原始基础llm更好的性能,尤其是分类。
与bloomberg ggpt相比:微调LLMs在大多数金融任务上的表现优于bloomberg ggpt。
与ChatGPT和GPT-4相比:微调llm在大多数分类任务中表现出优越的性能,但是在生成任务中,性能略差
主要评估微调LLM的任务如下:
金融分类任务:情绪分析,新闻标题分类
金融生成任务:问答、新闻摘要、命名实体识别。
2、从头开始预训练
从头开始训练目标是创建更好地适应金融领域的模型。
主要包括bloomberg ggpt和Fin-T5。
与BLOOM和T5相比,bloomberg ggpt和Fin-T5表现出良好的性能。
它们在预训练阶段,将公共数据集与金融特定数据集合并。这种方法可以创建更适合金融特定语言和细微差别的模型。
BloombergGPT的训练语料库包括一般和金融相关文本的平衡组合,它的训练数据中有很大一部分来自彭博社的特定子集,虽然只占总语料库的0.7%,但对模型在金融基准测试中的表现有很大贡献。
与BLOOM176B和T5等通用模型相比,bloomggpt和Fin-T5在市场情绪分类、多类别和多标签分类等任务上,或者在问答、命名实体识别、总结等生成任务上,都表现出了卓越的性能。这种优越的性能在特定领域的任务和一般生成任务中都很明显,这表明模型在生成与金融相关的内容方面是有效的。
虽然这些金融专用LLM可能不如一些闭源模型(如GPT-3或PaLM)强大,但它们在与金融相关的任务中的能力有所提高,并且一般的能力也近似于通用模型。
局限性和挑战
主要挑战:
虚假信息和偏见:LLM可以产生虚假信息和明显的偏见,如种族、性别和宗教偏见。
信息的准确性和公平性:对健全的财务决策至关重要,也是金融服务的基本要求。
缓解策略:
RAG看以确保准确性和减少幻觉。
通过内容审查和输出限制控制生成的内容,并通过将输出限制为预定义的答案来减少偏差。
最后论文地址: