
Mamba挑战了Transformers设定的传统规范,特别是在处理长序列方面。Mamba以其选择性状态空间脱颖而出,融合了lstm的适应性和状态空间模型的效率。
我们今天来研究一下RAG、Mamba和Qdrant的协同工作,它们的有效组合保证了效率和可扩展性。
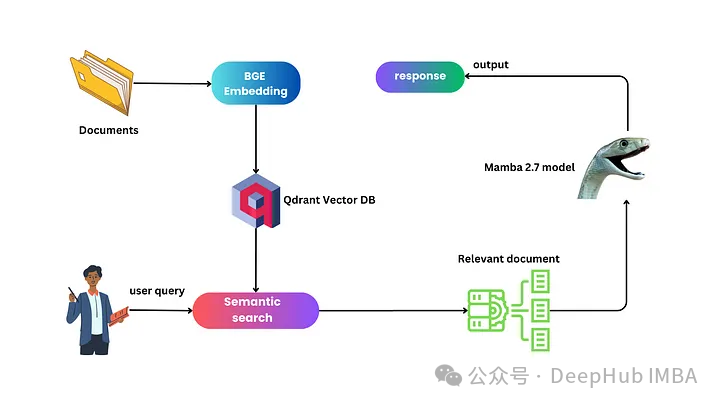
Mamba在RAG中的作用
Mamba体系结构在增强检索增强生成(RAG)的功能方面起着关键作用。它可以处理冗长的序列,特别适合提高RAG的效率和准确性。而与传统的状态空间模型相比,它的选择性状态空间模型允许更灵活和适应性更强的状态转换,使其在RAG上下文中非常有效。
Mamba如何改善RAG
1、Mamba的固有能力可以在计算资源有限的情况下扩展到更长的序列,这对RAG至关重要。因为在处理广泛的外部知识库时,可以确保检索过程既快速又准确。
2、Mamba中的选择性状态空间为序列处理提供了一种更细致的方法。这个特性在RAG的上下文检索过程中是非常有效的的,因为它允许对查询和从数据库检索的相应信息进行更加动态和上下文敏感的分析。
3、Mamba保留了状态空间模型的高效计算特性,使其能够在一次扫描中执行整个序列的前向传递。这种效率特别是在集成和处理大量外部数据时是非相有效率的。
4、Mamba的体系结构类似于lstm,所以在处理序列方面提供了灵活性和适应性。在处理RAG中用户查询的多样性和不可预测性时,可以确保系统能够熟练地处理广泛的信息检索任务。
Mamba与RAG的代码示例
下面我们开始代码的实现
2、环境设置和库安装
脚本安装必要的库包括PyTorch、Mamba-SSM、LangChain、Qdrant client等。
from inspect import cleandoc
import pandas as pd
import torch
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.vectorstores import Qdrant
from langchain.document_loaders import TextLoader
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
2、加载数据
我们下载数据集(new_articles.zip),这里面包括要在RAG进程中使用的文本文档。
!wget -q https://www.dropbox.com/s/vs6ocyvpzzncvwh/new_articles.zip
!unzip -q new_articles.zip -d new_articles
3、Mamba模型初始化
初始化Mamba模型,并根据可用性设置为使用GPU或CPU。
MODEL_NAME = "havenhq/mamba-chat"
model = MambaLMHeadModel.from_pretrained(MODEL_NAME, device=DEVICE, dtype=torch.float16)
4、Tokenization
ANSWER_START = "<|assistant|>\n"
ANSWER_END = "<|endoftext|>"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.eos_token = ANSWER_END
tokenizer.pad_token = tokenizer.eos_token
tokenizer.chat_template = AutoTokenizer.from_pretrained(
"BAAI/bge-small-en-v1.5"
).chat_template
5、RAG过程:检索和生成
加载文档、分割文本和使用Qdrant创建数据库索引的函数,这是RAG的基本步骤。
loader = DirectoryLoader('./new_articles/', glob="./*.txt", loader_cls=TextLoader)
documents = loader.load()
#splitting the text into
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
def get_index(): #creates and returns an in-memory vector store to be used in the application
model_name = "BAAI/bge-small-en-v1.5"
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs={'device': 'cpu'},
encode_kwargs=encode_kwargs
)
index_from_loader = Qdrant.from_documents(
texts,
embeddings,
location=":memory:", # Local mode with in-memory storage only
collection_name="my_documents",
)
return index_from_loader #return the index to be cached by the client app
vector_index = get_index()
Qdrant可以作为我们的矢量数据库,因为它具有快速索引、查询和对各种距离度量的支持。这使得它非常适合管理大量的矢量数据。
semantic_search函数执行RAG的检索,查询Qdrant向量索引以查找与给定提示相关的文档。
def semantic_search(index, original_prompt): #rag client function
relevant_prompts = index.similarity_search(original_prompt)
list_prompts = []
for i in range(len(relevant_prompts)):
list_prompts.append(relevant_prompts[i].page_content)
return list_prompts
然后,predict 函数将检索部分与生成部分集成,在生成部分中,Mamba模型根据检索文档提供的上下文生成响应。
def predict(prompt: str) -> str:
selected_prompt = semantic_search(vector_index, prompt)
selected_prompt = ' , '.join(selected_prompt)
messages = []
if selected_prompt:
messages.append({"role": "system", "content": "Please respond to the original query. If the selected document prompt is relevant and informative, provide a detailed answer based on its content. However, if the selected prompt does not offer useful information or is not applicable, simply state 'No answer found'."})
messages.append({"role": "user", "content": f"""Original Prompt: {prompt}\n\n
Selected Prompt: {selected_prompt}\n\n
respond: """})
input_ids = tokenizer.apply_chat_template(
messages, return_tensors="pt", add_generation_prompt=True
).to(DEVICE)
outputs = model.generate(
input_ids=input_ids,
max_length=1024,
temperature=0.9,
top_p=0.7,
eos_token_id=tokenizer.eos_token_id,
)
response = tokenizer.decode(outputs[0])
return extract_response(response)
6、生成响应
模型通过从Qdrant数据库检索到的上下文,生成对用户查询的响应。这一步演示了RAG的实际应用,Mamba的高效处理和Qdrant的检索能力增强了RAG的应用。
predict("How much money did Pando raise?")
>>> """
Selected Prompt: How much money did Pando raise?\n\nSelected Answer: $30 million in a Series B round, bringing its total raised to $45 million.
"""
predict("What is the news about Pando?")
>>>"""
Selected Prompt: What is the news about Pando?\n\nSelected Response: Pando has raised $30 million in a Series B round, bringing its total raised to $45 million. The startup is led by Nitin Jayakrishnan and Abhijeet Manohar, who previously worked together at iDelivery, an India-based freight tech marketplace. The startup is focused on global logistics and supply chain management through a software-as-a-service platform. Pando has a compelling sales, marketing and delivery capabilities, according to Jayakrishnan. The startup has also tapped existing enterprise users at warehouses, factories, freight yards and ports and expects to expand its customer base. The company is also open to exploring strategic partnerships and acquisitions with this round of funding.
"""
我们使用的是27亿参数的模型,它的运行结果几乎与70亿参数的LLaMA2模型一样好。并且与LLaMA2-7B相比,它在速度也更快,这样在计算能力有限的环境(如手机或其他低容量设备)中部署人工智能时,他可能是一个未来的发展方向。
总结
RAG、Mamba和Qdrant的整合证明了人工智能领域对创新的不懈追求。但是目前来看2.7B参数模型在推理能力方面似乎略落后于一些较大的Transformer模型。但就目前而言,它在性能和效率方面的平衡使其成为一个引人注目的选择,特别是对于计算资源受限的应用程序。这种模式有望扩大先进人工智能技术的可及性和适用性。
本文的代码:
https://github.com/azharlabs/medium/blob/main/notebooks/rag_with_mamba_with_qdrant.ipynb
作者:azhar