AI训练,为什么需要GPU?
随着人工智能热潮,GPU成为了AI大模型训练平台的基石,决定了算力能力。为什么GPU能力压CPU,成为炙手可热的主角呢?首先我们要先了解一下GPU的分类。提到分类,就得提及到芯片。半导体芯片分为和。其中,数字芯片的市场规模占比较大,达到70%左右。。由上图可以看到,。现在特别火爆的AI,用到的所谓“
政安晨【零基础玩转各类开源AI项目】:解析开源项目:Champ 利用三维参数指导制作可控且一致的人体图像动画
介绍了一种人体图像动画制作方法,该方法利用潜在扩散框架中的三维人体参数模型,来增强 curernt 人体生成技术中的形状排列和运动引导。该方法利用 SMPL(Skinned Multi-Person Linear)模型作为三维人体参数模型,建立统一的身体形状和姿势表示。这有助于从源视频中准确捕捉复杂
AI论文速读 | 2024[IJCAI]时空解耦掩码预训练的时空预测
时空预测技术对于交通、能源和天气等各个领域都具有重要意义。由于复杂的时空异质性,时空序列的准确预测仍然具有挑战性。特别是,当前的端到端模型受到输入长度的限制,因此经常陷入时空幻觉),即相似的输入时间序列后面跟着不同的未来值,反之亦然。为了解决这些问题,本文提出了一种新颖的自监督预训练框架时空解耦掩码
开源模型应用落地-LangSmith试炼-入门初体验-监控和自动化(五)
学习Monitoring and automations功能,帮助开发者更好地管理和优化LangChain应用程序,提高其性能、可靠性和用户体验。
Hadoop序列化:高效数据交换的秘诀
Hadoop序列化:高效数据交换的秘诀1.背景介绍在大数据时代,数据的存储和处理已经成为一个巨大的挑战。Apache Hadoop作为一个分布式系统基础架构,为海量数据的存储和处理提供了可靠、高效的解决方案。然而,在分布式环境中,数据需要在不同的节点之间进行传输和交换,这就需要对数
AI+新能源充电桩数据集
7+细分充电桩数据集;新能源充电桩;充电站负荷预测
HiveQL在生物信息学中的应用
HiveQL在生物信息学中的应用1. 背景介绍1.1 生物信息学的兴起生物信息学是一门融合生物学、计算机科学和信息技术的新兴学科。随着基因组测序技术的飞速发展,生物数据的产生量呈指数级增长,传统的数据处理方式已无法满足需求。因此,生
SparkStreaming的数据源与接口
SparkStreaming的数据源与接口1. 背景介绍1.1 大数据实时处理的重要性在当今大数据时代,海量数据以前所未有的速度不断产生。企业需要对这些实时数据进行快速分析和处理,以便及时洞察业务趋势,优化决策过程。
AI系统HBase原理与代码实战案例讲解
AI系统HBase原理与代码实战案例讲解1. 背景介绍1.1 大数据时代的数据存储挑战在当前大数据时代,海量数据的存储和管理面临着前所未有的挑战。传统的关系型数据库已经无法满足高并发、高吞吐量的数据访问需求。为了应对
Hive UDF自定义函数原理与代码实例讲解
Hive UDF自定义函数原理与代码实例讲解1.背景介绍在大数据时代,海量数据的存储和处理成为了一个巨大的挑战。Apache Hive作为构建在Hadoop之上的数据仓库工具,为结构化数据的存储和分析提供了强大的SQL查询能力。然而,有时Hive内置的函数并不能满足特定的业务
AI人工智能代理工作流AI Agent WorkFlow:智能代理在智能家居中的实践
AI人工智能代理工作流AI Agent WorkFlow:智能代理在智能家居中的实践1. 背景介绍1.1 人工智能在智能家居中的应用现状随着人工智能技术的快速发展,智
使用seq2seq架构实现英译法
将它们拼接成一个中间语义张量c, 接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言。
Vanna-ai 大模型开源项目 基于RAG的TextToSql框架 安装和使用教程
您还可以将 SQL 查询添加到训练数据中。如果您已经有一些查询,这将很有用。您只需从编辑器中复制并粘贴这些内容即可开始生成新的 SQL。根据您的用例,您可能需要也可能不需要运行这些命令。有关详细信息,请参阅。根据您的用例,您可能需要也可能不需要运行这些命令。DDL 语句包含有关数据库中的表名、列、数
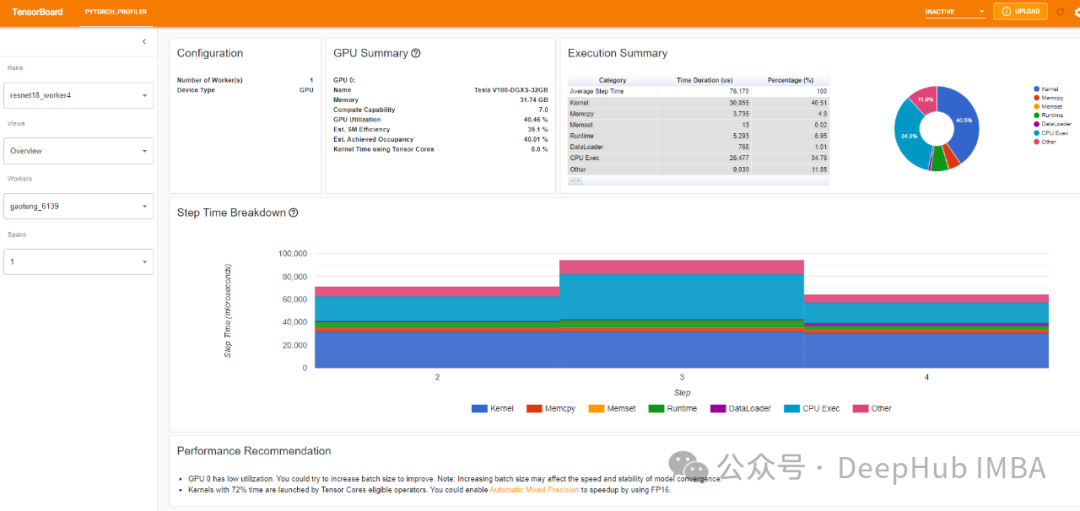
使用PyTorch Profiler进行模型性能分析,改善并加速PyTorch训练
加速机器学习模型训练是所有机器学习工程师想要的一件事。更快的训练等于更快的实验,更快的产品迭代,还有最重要的一点需要更少的资源,也就是更省钱。
机器学习、深度学习、AI工程师、人工智能面试热点问题(一)
混淆矩阵(Confusion matrix)计算过程混淆矩阵作为分类模型结果的更加细致精确的可视化展示,有时也被称为误差矩阵或者可能性表格,通常混淆矩阵会应用于二分类问题中,对此首先有如下关键定义:Actual condition:样本真实标签;·Predicated condition:模型预测标
【AI】人工智能(AI)的崛起与未来展望
本文将探讨AI的基本概念、发展历程、应用场景,并通过一些Python代码示例来展示AI的实际应用,最后对AI的未来进行展望。人机协同将成为未来AI发展的重要方向。随着技术的不断进步和应用场景的不断拓展,AI将在未来发挥更加重要的作用,为人类创造更加美好的未来。AI的发展经历了符号主义、连接主义和深度
Kafka Connect原理与代码实例讲解
Kafka Connect原理与代码实例讲解1.背景介绍1.1 Kafka的发展历程Apache Kafka最初由LinkedIn公司开发,用作LinkedIn的活动流和运营数据处理管道的基础。Kafka于2011年初
基于hadoop的协同过滤算法电影推荐系统的设计与实现
在当今信息时代,互联网上的数据量呈爆炸式增长,用户面临着信息过载的困扰。电影作为一种重要的娱乐媒体,其数量也在不断增加,给用户带来了选择的困难。因此,一个高效、智能的电影推荐系统就显得尤为重要。我们将使用MovieLens 100K数据集,它包含了100,000条电影评分记录,由943位匿名用户对1
数据科学与大数据专业毕业设计(论文)选题推荐
数据科学与大数据专业毕业设计(论文)选题合集涵盖了管理系统、小程序、深度学习、机器学习、算法、人工智能、大数据、网络安全、嵌入式、推荐系统、目标检测等多个热门领域。对于计算机专业、软件工程专业、人工智能专业、通信工程专业的毕业生而言,选择一个合适的毕业设计选题至关重要。在这个毕业设计选题合集中,我们
Tiny Time Mixers (TTM)轻量级时间序列基础模型:无需注意力机制,并且在零样本预测方面表现出色
TTM是一个轻量级的,基于mlp的基础TS模型(≤1M参数),在零样本预测方面表现出色,甚至优于较大的SOTA模型。



