
随着人工智能热潮,GPU成为了AI大模型训练平台的基石,决定了算力能力。为什么GPU能力压CPU,成为炙手可热的主角呢?首先我们要先了解一下GPU的分类。提到分类,就得提及到芯片。
半导体芯片分为数字芯片和模拟芯片。其中,数字芯片的市场规模占比较大,达到70%左右。数字芯片,还可以进一步细分,分为:逻辑芯片、存储芯片以及微控制单元(MCU)。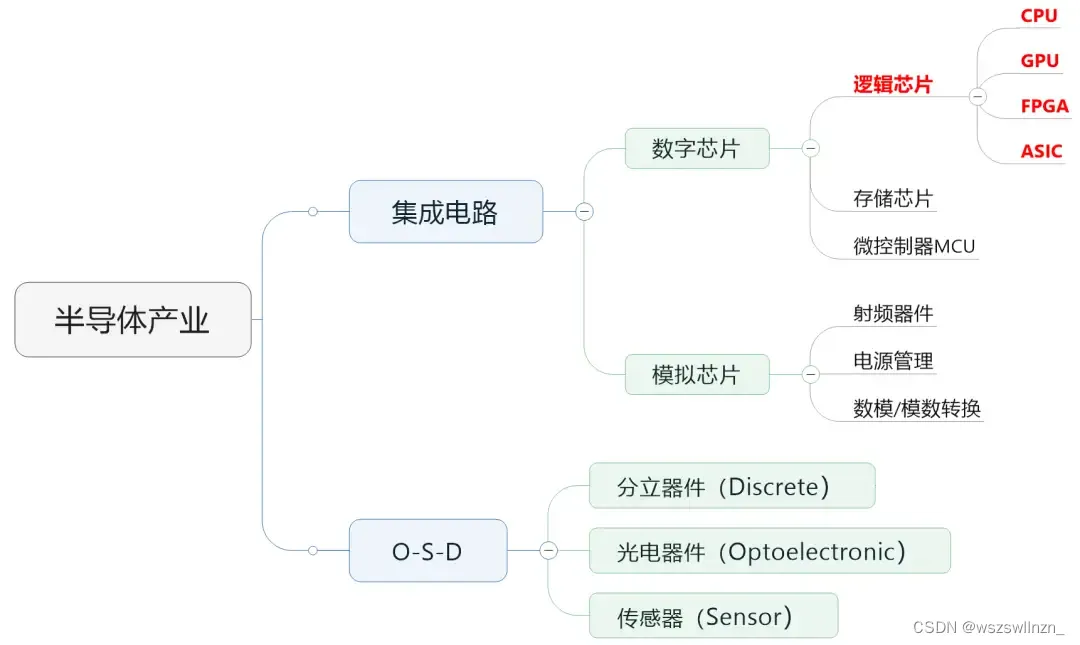
由上图可以看到,大家经常听说的CPU、GPU、FPGA、ASIC,全部都属于逻辑芯片。现在特别火爆的AI,用到的所谓“AI芯片”,也主要是指它们。
下面先了解下人工智能技术。
一、人工智能
人工智能在早期叫做“人工神经网络”。人脑是由数以亿计的神经元组成。这些神经元彼此连接,形成了庞大而复杂的神经网络。参考人脑神经元,人工神经元模型就被设计了出来。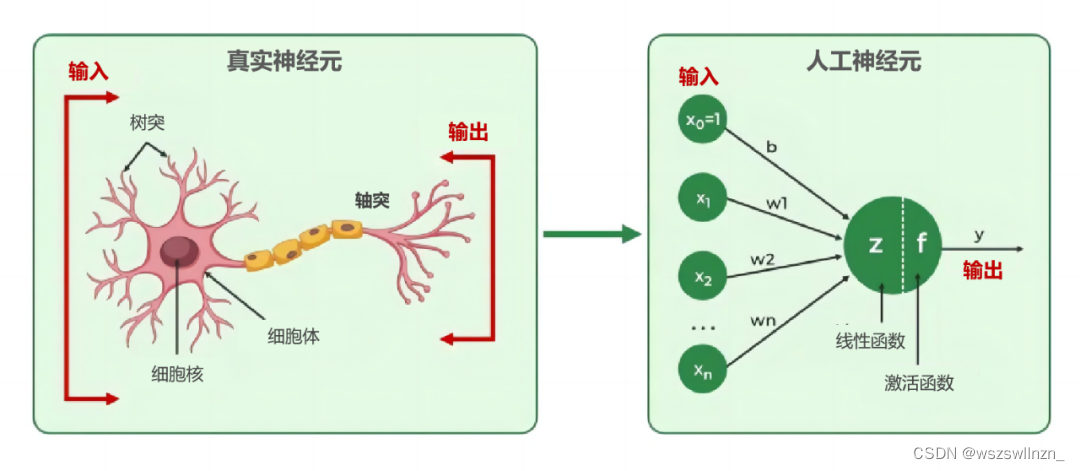
在上图右侧的人工神经元里,通过调整每个输入的权重,经由神经元计算处理之后,便可得出相应的输出。这里面的每个权重,就被称作一个参数。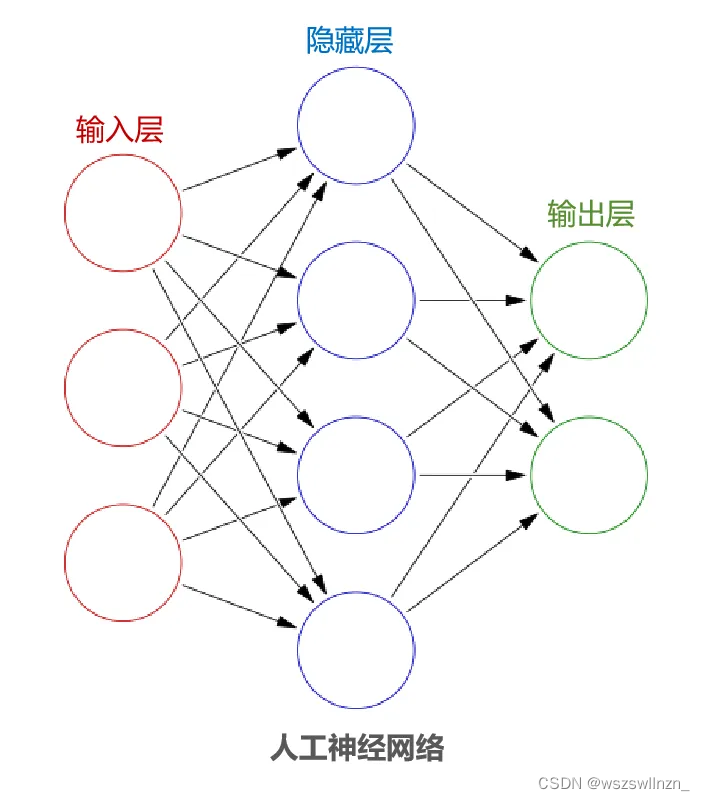
把这样的多个神经元相互连接形成网络,就是人工神经网络了。人工神经网络一般由输入层、中间的多个隐藏层以及输出层组成。通过投喂大量的数据,训练出一个复杂的神经网络模型。这个过程就叫做“深度学习”,属于“机器学习”的子集。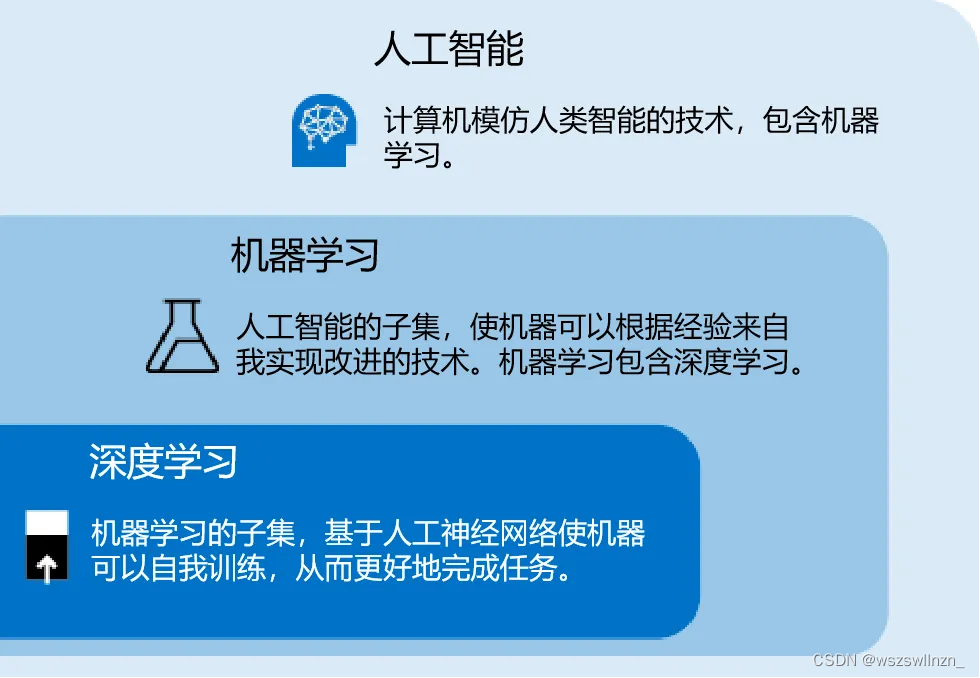
深度学习是目前最主流的人工智能算法。从过程来看,包括训练(training)和推理(infe
rence)两个环节。
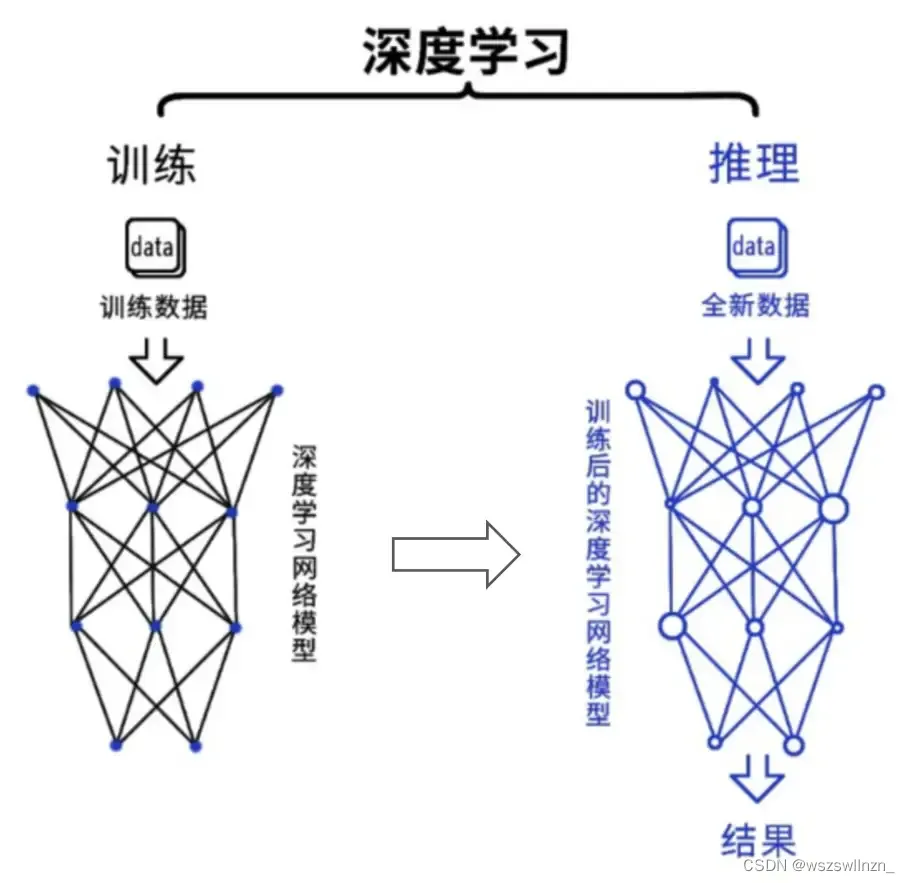
在训练环节,通过投喂大量的数据,训练出一个复杂的神经网络模型。在推理环节,利用训练好的模型,使用大量数据推理出各种结论。
训练环节由于涉及海量的训练数据,以及复杂的深度神经网络结构,所以需要的计算规模非常庞大,对芯片的算力性能要求比较高。而推理环节,对简单指定的重复计算和低延迟的要求很高。它们所采用的具体算法,包括矩阵相乘、卷积、循环层、梯度运算等,分解为大量并行任务,可以有效缩短任务完成的时间。
二、CPU
CPU(Central Processing Unit)是电脑的大脑,CPU内部主要包含运算器(也叫逻辑运算单元,ALU)和控制器(CU),以及一些寄存器和缓存。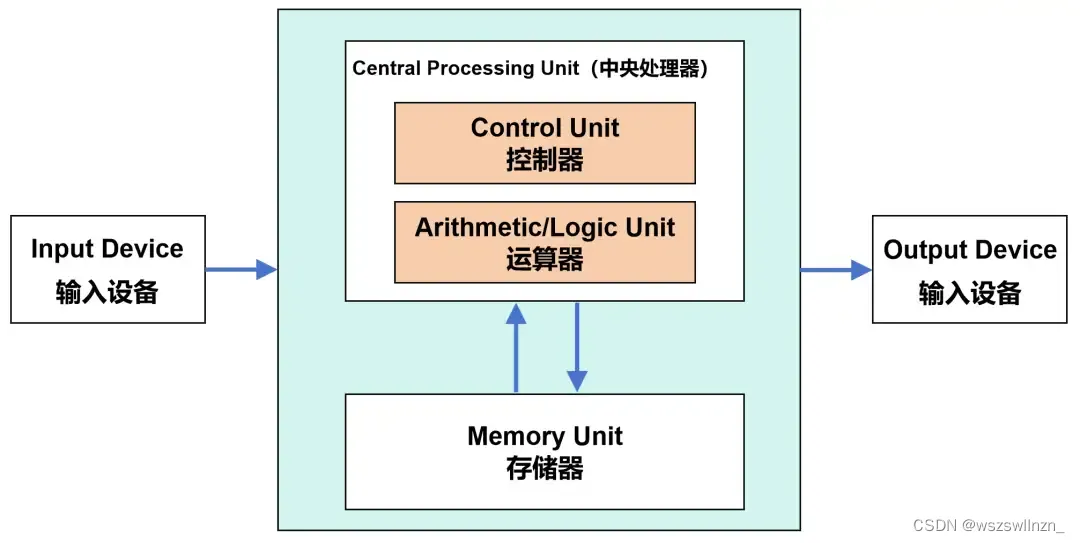
数据来了,会先放到存储器。然后,控制器会从存储器拿到相应数据,再交给运算器进行运算,运算完成后,再把结果返回到存储器。
人们把多套运算器、控制器和缓存集成在同一块芯片上,就组成了多核CPU。多核CPU拥有真正意义上的并行处理能力。
但CPU的核心越多,核心之间的互联通讯压力就越来越大,会降低单个核心的性能表现。并且,核心多了还会使功耗增加,如果忙闲不均,整体性能还可能不升反降。
三、GPU,并行计算
GPU(Graphics Processing Unit)叫做图形处理单元,GPU一词从1999年Nvidia推出其GeForce256时开始流行。GPU主要负责图形处理任务,所以,它的内部架构和CPU存在很大的不同。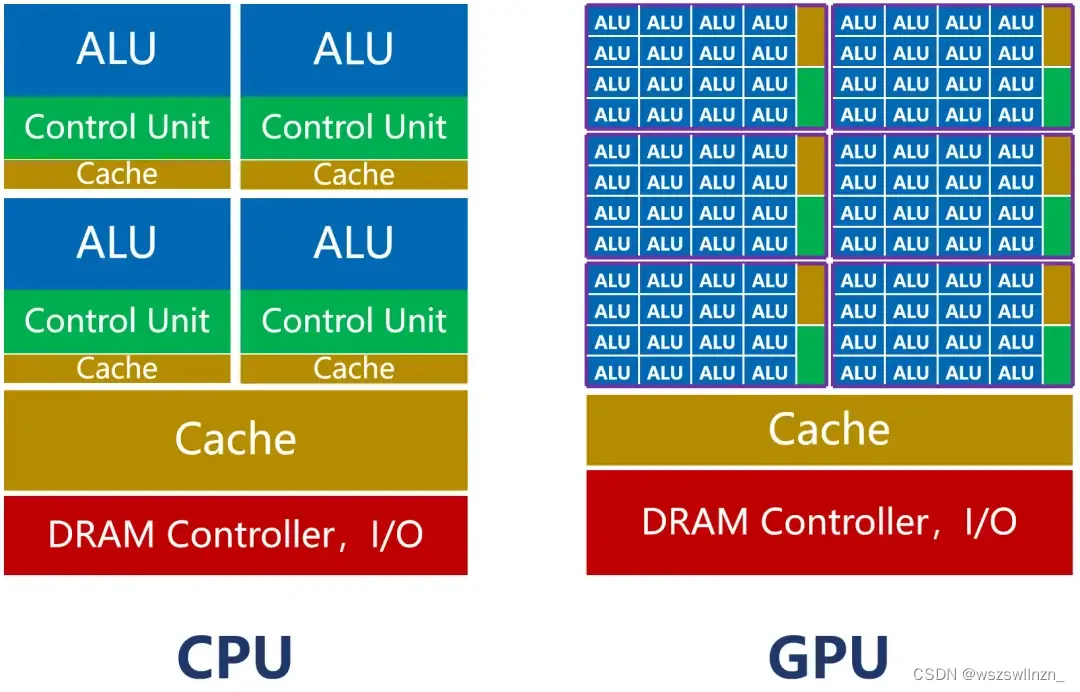
如上图所示,CPU的内核(包括了ALU)数量比较少,最多只有几十个。但是,CPU有大量的缓存(Cache)和复杂的控制器(CU)。
CPU的核数少,单个核心有足够多的缓存和足够强的运算能力,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件,适合处理复杂的任务。
相比之下GPU就简单粗暴多了,每个核心的运算能力都不强,缓存也不大,就靠增加核心数量来提升整体能力。核心数量多了,就可以多管齐下,处理大量简单的并行计算工作。它的工作也就不局限于图像显示渲染了,还允许其他开发者用来加速高性能计算、深度学习等其他工作负载。
由于赶上了人工智能这样并行计算需求暴增的机遇,将AI训练这种并行性自然地映射到GPU,与仅使用 CPU 的训练相比,速度明显提升,并使它们成为训练大型、复杂的基于神经网络的系统的首选平台。
GPU凭借自身强悍的并行计算能力以及内存带宽,可以很好地应对训练和推理任务,已经成为业界在深度学习领域的首选解决方案。
目前,大部分企业的AI训练,采用的是英伟达的GPU集群。如果进行合理优化,一块GPU卡,可以提供相当于数十其至上百台CPU服务器的算力。
版权归原作者 wszswllnzn_ 所有, 如有侵权,请联系我们删除。