
目录
Q1.损失函数和目标函数的区别与联系
参考答案
损失函数(Loss Function)是用来衡量模型预测结果和真实结果之间差异的一种函数,通常用于监督学习任务中。损失函数的值越小,表示模型的预测结果越接近真实结果。
目标函数(Objective Function)是在优化模型的过程中所要最小化或最大化的函数。通常情况下,目标函数就是损失函数,因为我们的目标是最小化模型的预测误差。
但是,在某些情况下,目标函数可能不仅仅是损失函数。例如,当我们在训练带有正则化的模型时,目标函数可能包括两部分:损失函数和正则化项。在这种情况下,我们的目标是同时最小化损失函数和正则化项的值。
总之,损失函数和目标函数是机器学习和深度学习中非常重要的概念,它们帮助我们评估和优化模型的性能,提高预测的准确度。
Q2.多分类问题的常见解决方法
参考答案
核心方法包括三种,分别是OvO、OvR和MvM。其中OvO具备性能优势,而MvM则具备判断效力优势。
深度解析:三种多分类问题解决方案
多分类问题描述
当离散型标签拥有两个以上分类水平时,即对多个(两个以上)分类进行类别预测的问题,被称为多分类问题。例如有如下四分类问题简单数据集:
OvO策略
拆分策略
OvO的拆分策略比较简单,基本过程是将每个类别对应数据集单独拆分成一个子数据集,然后令其两两组合,再来进行模型训练。例如,对于上述四分类数据集,根据你签类别可将其拆分成四个数据集,然后再进行两两组合,总共有6种组合,也就是C2种组合。拆分过程如下所示: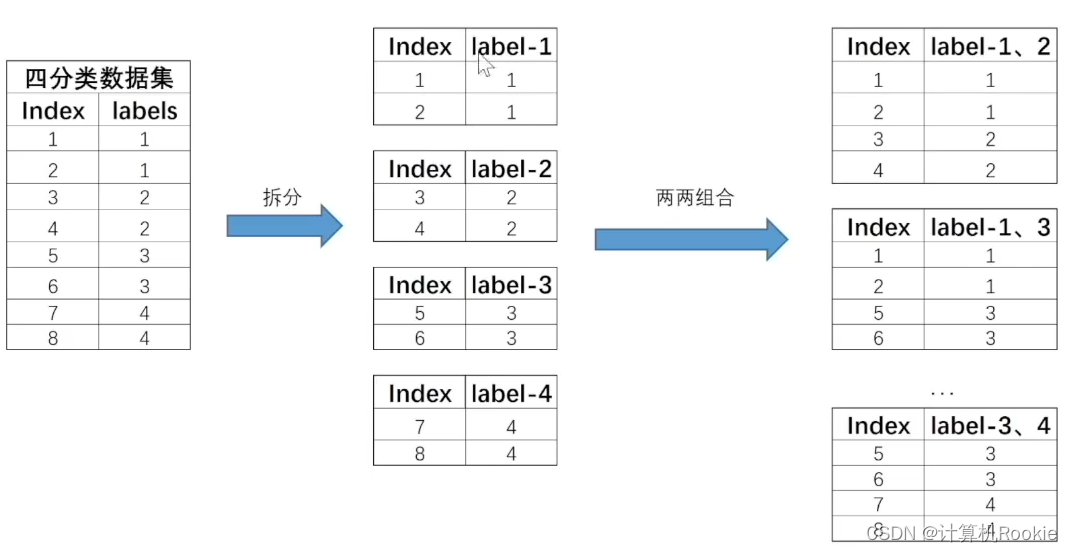
OvR策略
拆分策略:
和Ovo的两两组合不同,OvR策略则是每次将一类的样例作为正例、其他所有数据作为反例来进行数据集拆分。对于上述四分类数据集,OvR策略最终会将其拆分为4个数据集,基本拆分过程如下: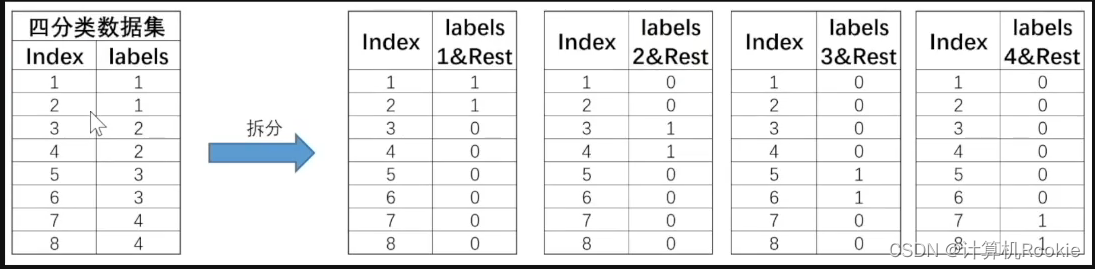
此4个数据集就将训练4个分类器。注意,在OvR的划分策略种,是将rest无差别全都划分为负类。当然,如果数据集总共有N个类别,则在进行数据集划分时总共将拆分成N个数据集。
OvO和OvR的比较
对于这两种策略来说,尽管OvO需要训练更多的基础分类器,但由于OvO中的每个切分出来的数据集都更小,因此基础分类器训练时间也将更短。因此,综合来看在训练时间开销上,OvO往往要小于OvR。而在性能方面,大多数情况下二者性能类似。
MvM策略
相比于OvO和OvR,MM是一种更加复杂的策略。MvM要求同时将若干类化为正类、其他类化为负类,并且要求多次划分,再进行集成。一般来说,通常会采用一种名为“纠错输入码”(Error Correcting Output Codes,简称ECOC)的技术来实现MvM过程。
拆分策略
此时对于上述4分类数据集,拆分过程就会变得更加复杂,我们可以任选其中一类作为正类、其余作为负类,也可以任选其中两类作为正类、其余作为负数,以此类推。由此则诞生出了非常多种子数据集,对应也将训练非常多个基础分类器。例如对于以上数据集,有如下的划分方式: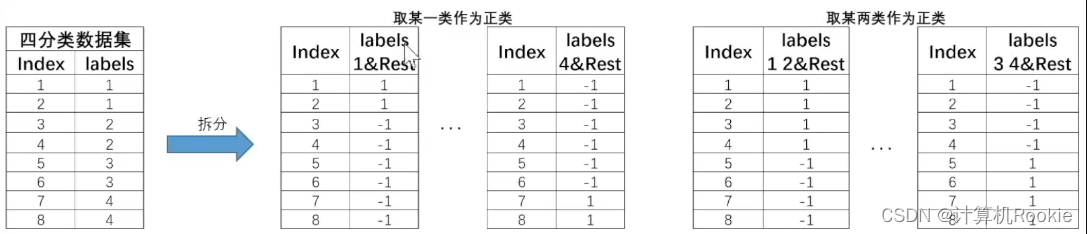
Q3 解释KL散度基本概念及在损失函数构建过程中的作用
参考答案
相对嫡也被称为Kullback-Leibler散度(KL散度)或者信息散度(information divergence)。通常用来衡量两个随机变量分布的差异性,在模型训练中,KL散度可以用来衡量模型输出分布与真实分布之间的差异; 在深度学习中,KL散度常常被用于衡量两个概率分布之间的差异,例如在变分自编码器(Variational Autoencoder,VAE)和生成对抗网络(Generative Adversarial Networks,GAN)中。
深度解析:通过KL散度构建二分类交叉嫡损失函数
假设对同一个随机变量x,有两个单独的概率分布P(x)和Q(x),当X是离散变量时,我们可以通过如下相对嫡计算公式来衡量二者差异: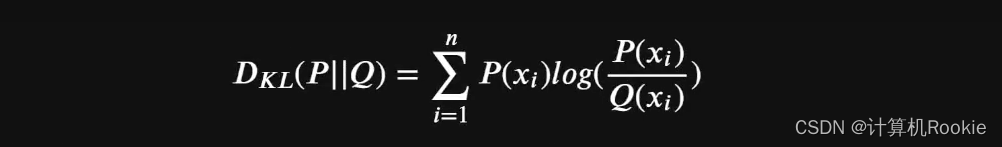


KL散度 = 交叉熵 - 信息熵
Q4.详细介绍F1-Score和ROC-AUC指标计算过程
混淆矩阵(Confusion matrix)计算过程
混淆矩阵作为分类模型结果的更加细致精确的可视化展示,有时也被称为误差矩阵或者可能性表格,通常混淆矩阵会应用于二分类问题中,对此首先有如下关键定义:
Actual condition:样本真实标签;
·Predicated condition:模型预测标签;
例如,有如下数据集,第一列为真实标签,即Actual condition,第二列为模型预测结果,即Predicated condition
Actual condition positive (P)∶样本中阳性样本总数,一般也就是真实标签为1的样本总数;
Actual condition negative (N)︰样本中阴性样本总数,一般也就是真实标签为0的样本总数;
Predicted condition positive (PP)︰预测中阳性样本总数,一般也就是预测标签为1的样本总数;
Predicted condition negative (PN):预测中阴性样本总数,一般也就是预测标签为0的样本总数;
True positive (TP)∶样本属于阳性((类别1)、并且被正确识别为阳性(类别1)的样本总数;TP发生时也被称为正确命中(hit) ;
True negative (TN)∶样本属于阴性(类别0)、并且被正确识别为阴性(类别O的样本总数;TN发生时也被称为正确拒绝(correct rejection) ;
· False positive (FP)︰样本属于阴性(类别0),但被错误判别为阳性(类别1)
的样本总数;FP发生时也被称为发生l类了错误(Type l error),或者假警报(Falsealarm)、低估(underestimation)等;
False negative (FN)∶样本属于阳性((类别1),但被错误判别为阴性(类别0的样本总数;FN发生时也被称为发生了I类错误(Type ll error),或者称为错过目标(miss)、高估(overestimation)等;
精确率(Precision)
精确率是指模型预测为正例的样本中,实际上为正例的比例。换句话说,精确率衡量了模型预测为正例的准确性。
精确率的计算公式如下:
Recall = TP / (TP + FN)
在实际应用中,精确率适用于需要高准确性的情况,比如肿瘤检测。在这种情况下,我们更关心的是模型预测为正例的样本中,有多少是真正的正例。
召回率(Recall)
召回率是指实际为正例的样本中,被模型正确预测为正例的比例。召回率衡量了模型捕捉到的正例的数量。
召回率的计算公式如下:
Recall = TP / (TP + FN)
在某些情况下,高召回率更为重要,比如安全检测系统。在这种情况下,我们希望尽可能多地捕捉到真正的正例,即使会带来一些误报。
F1 分数(F1-score)
F1 分数是精确率和召回率的调和平均值,用于综合考虑模型的准确性和捕捉能力。
F1 分数的计算公式如下:
F1-score = 2 * (Precision * Recall) / (Precision + Recall)
F1 分数在模型评估中很常见,因为它平衡了精确率和召回率。当我们需要综合考虑准确性和捕捉能力时,F1 分数是一个有用的指标。
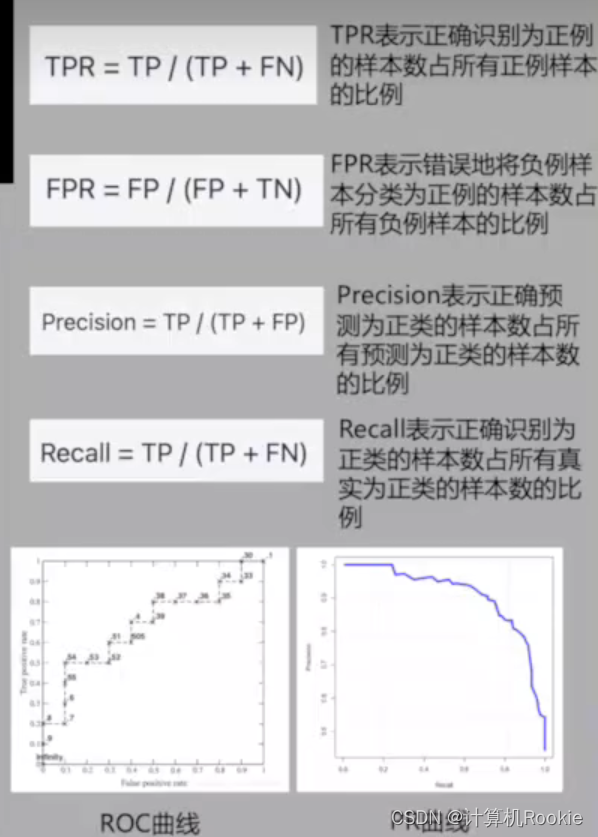
ROC和PR曲线

以下是一个示例代码,展示如何在 Python 中计算精确率、召回率和 F1 分数:
defcalculate_metrics(TP, FP, FN):
precision = TP /(TP + FP)
recall = TP /(TP + FN)
f1_score =2*(precision * recall)/(precision + recall)return precision, recall, f1_score
# 示例数据
true_positive =150
false_positive =30
false_negative =20
precision, recall, f1_score = calculate_metrics(true_positive, false_positive, false_negative)print("精确率:", precision)print("召回率:", recall)print("F1 分数:", f1_score)
如何解决正负样本不均衡:

Focal loss
将高置信度的降本权重降低,重点关注置信度低的样本。(因为是平方关系,置信度高的样本对损失的传播减小,使得模型更关注于置信度低的样本)
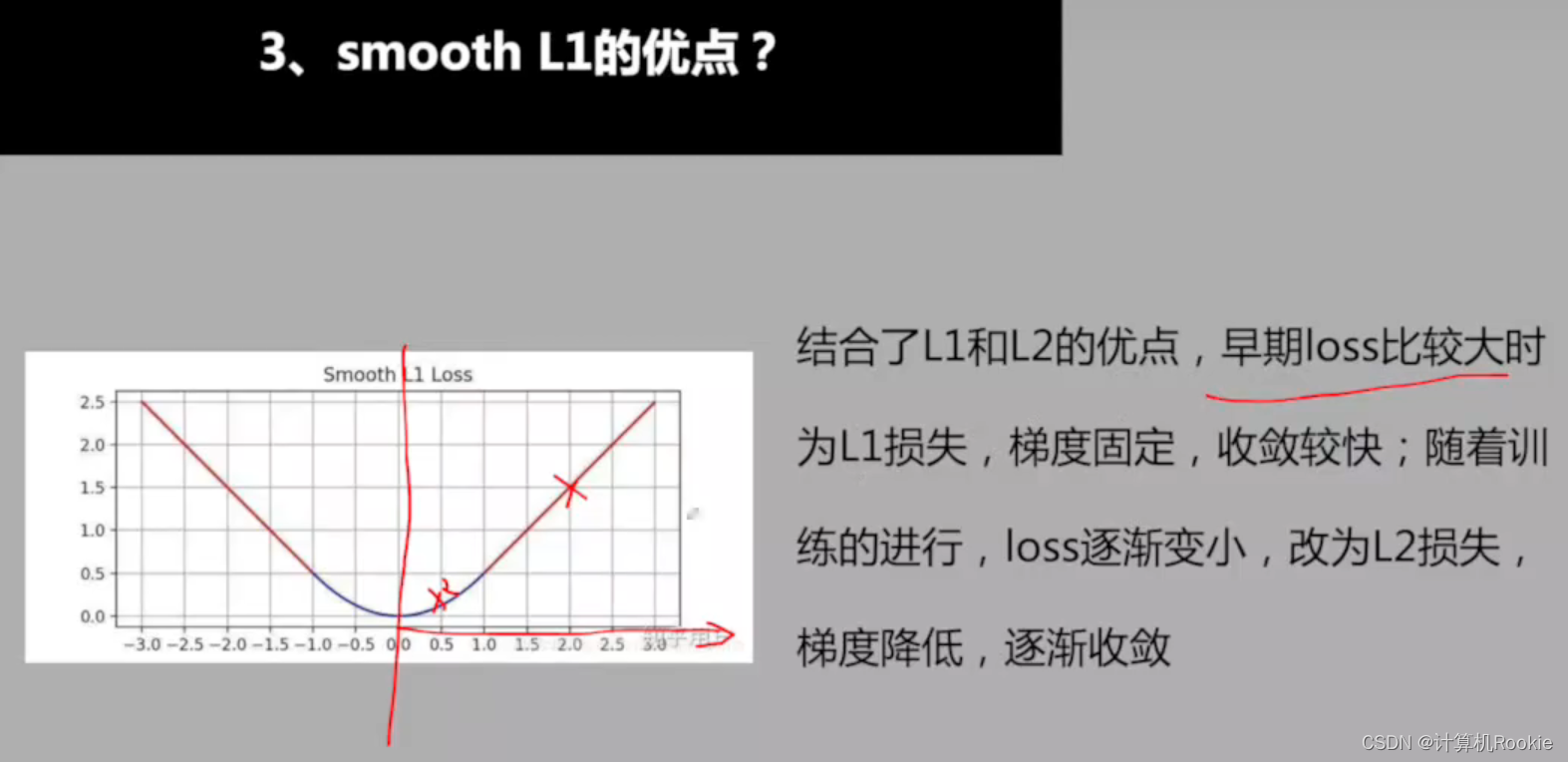
smooth L1的优点
卷积有什么特点?

BN是怎么计算的?

BN解决的问题


batch size大小对训练过程的影响?

激活函数的作用:

激活函数有哪些?
为什么使用relu而不是sigmoid
Momentum优化算法原理及作用?

池化层如何反向传播

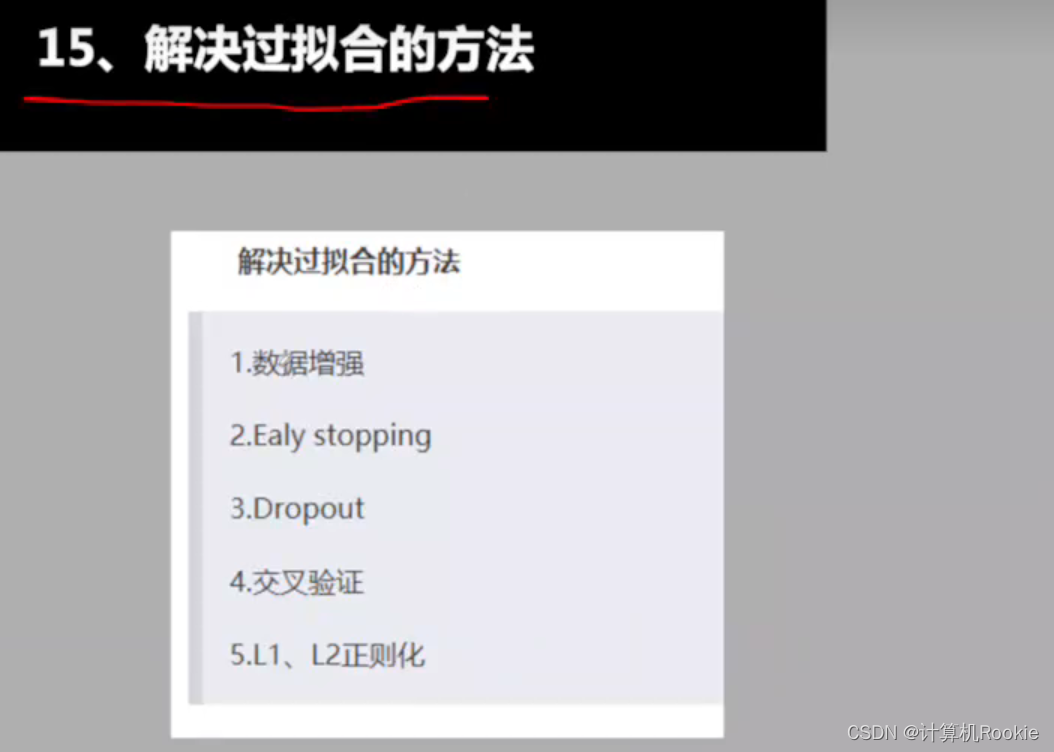
解决过拟合的方法
图像感受野如何计算

增大感受野的方法
1*1卷积核的作用

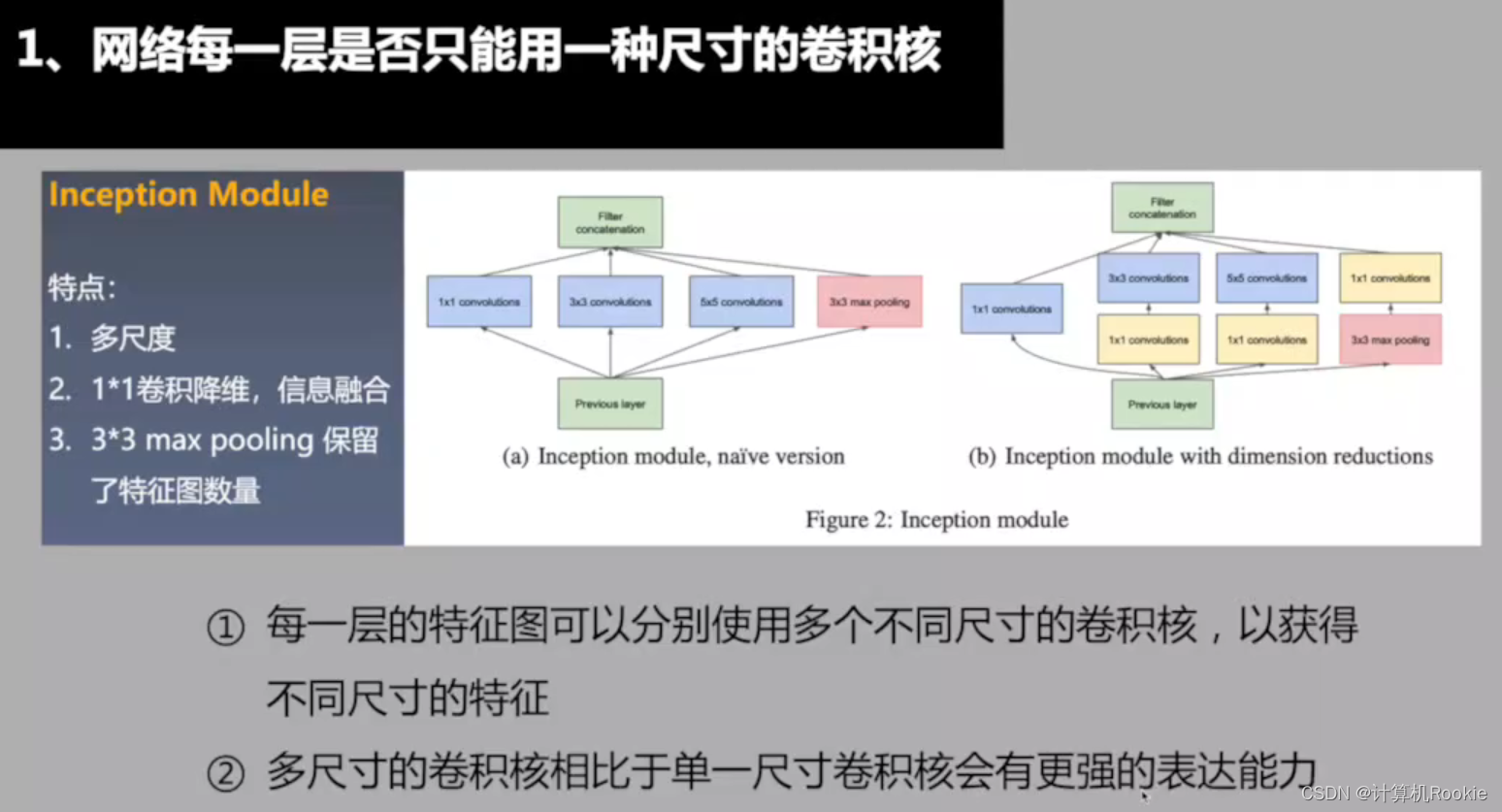
网络每一层是否只能用一种尺寸的卷积核?
SGD、Momentum、Adam的区别

R-CNN、SPPNet、SSD的区别

卷积神经网络的平移不变性

转置卷积和空洞卷积的区别

转置卷积的棋盘效应

深度可分离卷积
一般来说,深度可分离卷积最后的参数量是普通卷积的1/9。
PCA分析(主成分分析法):
数据降维算法,高维->低维。
Resnet 网络为什么有效?
跳跃连接,主要原因是解决了梯度消失和爆炸(保留了先前几个层次的特征,相当于将不同层次(不同深度)的特征都考虑了)
而ResXNet网络中加入了多个卷积分支来提取特征,并且有更多的数据增强策略。
Dropout和权重剪枝的区别
Dropout是随机使得神经元失活;
而权重剪枝是对网络权重的重要性进行排序,设置权重阈值,去掉一定比例的权重。
全连接层和全局池化的区别

全局池化是否可以替代全连接层:

L2权重衰减和L2正则化的区别:
L2正则式在损失函数中的添加正则项,而L2权重衰减是在权重更新回传时添加惩罚项。
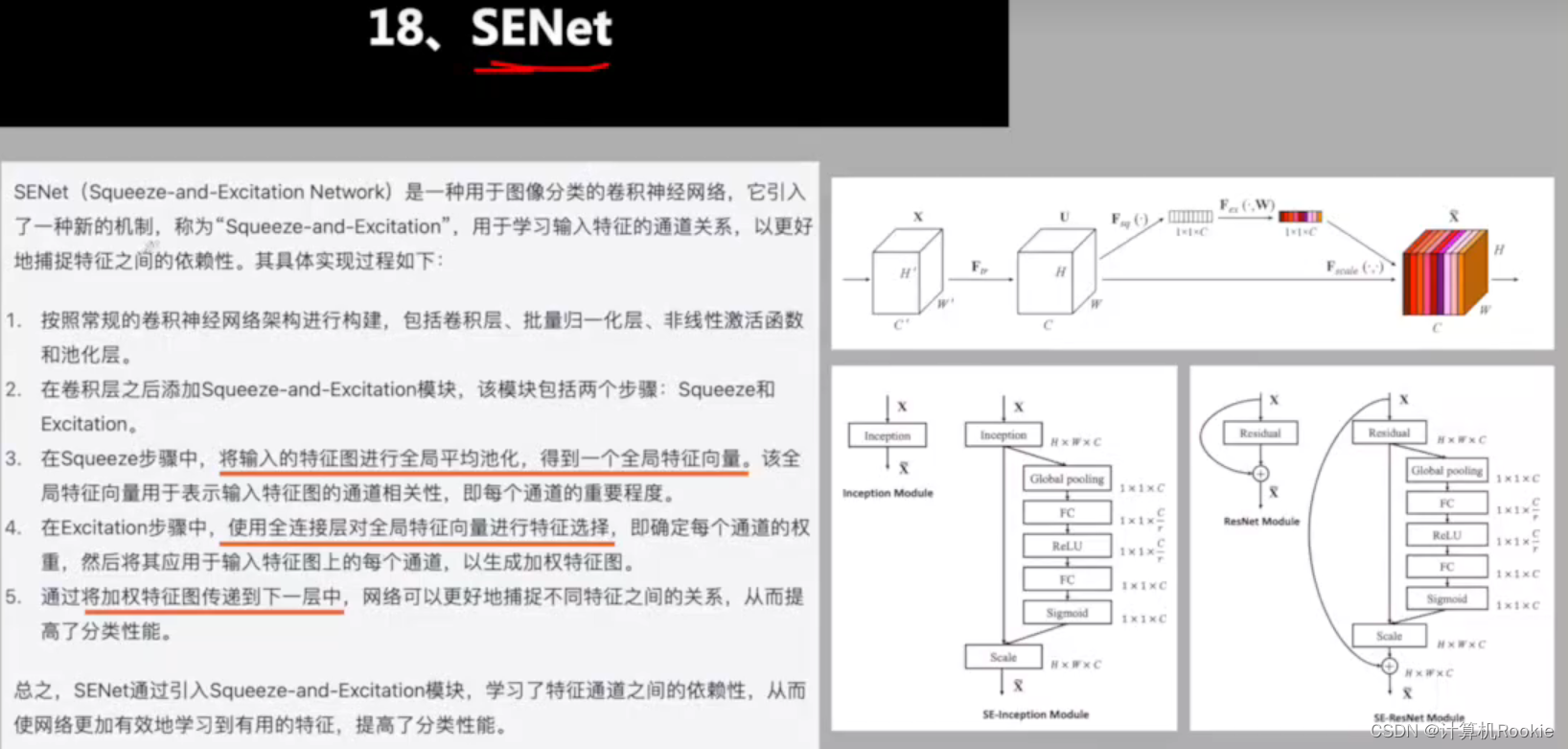
SENet
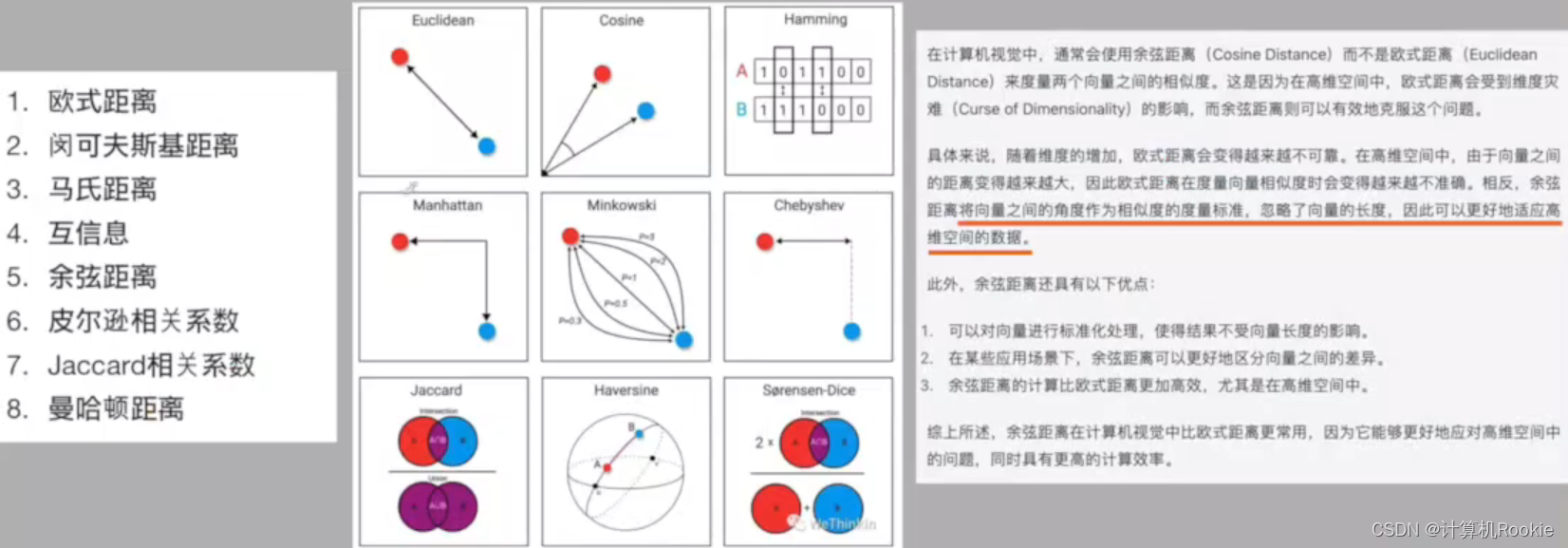
常见的距离度量
欧氏距离:度量距离长度,随着维度的增加会越来越不可靠。
余弦距离:将向量之间的角度作为相似度的度量,忽略向量的长度,以适应高维空间的数据。
版权归原作者 计算机Rookie 所有, 如有侵权,请联系我们删除。