OpenCV与AI深度学习 | 实战 | 基于YoloV5和Mask RCNN实现汽车表面划痕检测(步骤 + 代码)
该项目专注于汽车划痕检测,与不同类型产品的自主质量检测系统的开发同步。例如,在停车场,这种检测为客户提供了汽车安全无虞的保证;此外,如果发生什么情况,检测系统将有助于仔细处理这种情况。
C++人工智能框架:实现深度学习与神经网络应用
1. 背景介绍1.1 人工智能的崛起人工智能(AI)已经成为当今科技领域最热门的话题之一。随着计算能力的提升和大量数据的可用性,AI技术在各个领域取得了显著的进展。深度学习和神经网络作为AI的核心技术,已经在图像识别、自然语言处理、推荐系统等领域取得了重要的突破。1.2 C++在人工智能领域的应用C

为什么你的RAG不起作用?失败的主要原因和解决方案
本文的目标是揭示普通RAG失败的主要原因,并提供具体策略和方法,使您的RAG更接近生产阶段。
毕业设计:基于深度学习的摄像头人脸识别系统 人工智能
毕业设计:基于深度学习的摄像头人脸识别系统利用深度学习技术和计算机视觉方法,实现对人脸图像的自动识别和分类。通过深入研究人脸特征提取、卷积神经网络模型构建等关键技术,我们的系统能够在不同的环境和条件下,准确识别和分类人脸。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提供了一个
深度学习VGG16网络构建(Pytorch代码从零到一精讲,帮助理解网络的参数定义)
很多时候,对于一些网络结构,我们总是会看到其对应的图片,但是代码部分,讲的人不是很多。比如,下面这两张图片,就是讲解VGG16的博客或者视频中经常能够看到的。下面这张图片的D类型是VGG16架构,E类型是VGG19初次见到这种图片,其实不是特别清楚,就导致很多人对网络结构其实不是那么清楚。比如,co
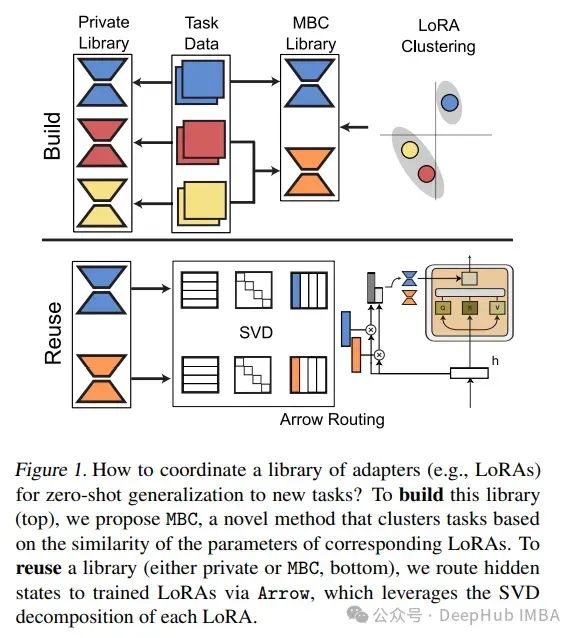
2024年5月第四周LLM重要论文总结
本文总结了2024年5月第四周发表的一些最重要的LLM论文。这些论文的主题包括模型优化和缩放到推理、基准测试和增强性能。
YOLOv8改进 | 图像去噪篇 | 单阶段盲真实图像去噪网络RIDNet辅助YOLOv8图像去噪(全网独家首发)
本文给大家带来的改进机制是单阶段盲真实图像去噪网络RIDNet,RIDNet(Real Image Denoising with Feature Attention)是一个用于真实图像去噪的卷积神经网络(CNN),旨在解决现有去噪方法在处理真实噪声图像时性能受限的问题。通过单阶段结构和特征注意机制,
C++与人工智能:深度学习与C++实践
1.背景介绍C++与人工智能:深度学习与C++实践1. 背景介绍随着计算机技术的不断发展,人工智能(AI)已经成为了现代科技的重要领域之一。深度学习(Deep Learning)是人工智能的一个重要分支,它通过模拟人类大脑中的神经网络来学习和解决复杂问题。C++是一种高性能、高效的编程语言,在计算机
YoloV5、ShuffleNetV2、YoloV5-Lite网络概述
本文主要讲解了yolov5、ShuffleNetV2以及yolov5-Lite的网络结构相关知识
一文搞懂人工智能、机器学习、深度学习和大模型
当我们谈论人工智能(AI),机器学习(Machine Learning),深度学习(Deep Learning),以及大模型(Large Models)时,实际上是在讨论人类如何让计算机学会像我们一样思考、学习和做出决策的技术。但是很多人都分不清他们之间的区别,今天我来给大家讲一下。想象一下,你正在
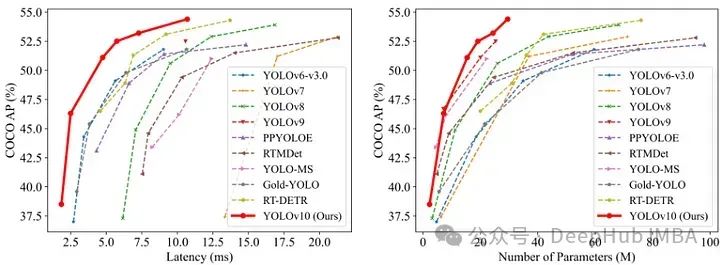
【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
本文首先介绍视觉模型在人工智能领域的位置,其次对原理概念初步进行说明,之后对推理与训练过程进行详细阐述,最后通过一个实战例子,用极少的代码行数将笔记本电脑的摄像头改装为实时视频监控,目标是让读者通过读完此文,快速上手YOLOv10技术进行物体目标检测,
基于深度学习神经网络的AI图像PSD去雾系统源码
基于深度学习神经网络的AI图像PSD去雾系统源码
Vision Mamba 代码调试---Pycharm+AutoDL
本文介绍如何使用AutoDL和Pycharm对Vision mamba进行调试
大数据下的精准营销策略研究
大数据下的精准营销策略研究1.背景介绍1.1 精准营销的重要性在当今竞争激烈的商业环境中,精准营销已成为企业获取更多客户、提高销售业绩和增强品牌知名度的关键策略。传统的大规模营销方式已经难以满足现代消费者个性化和定制化的需求。相比之下,精准
HNU_AI_实验4--深度学习算法及应用
人工智能-实验4第五关可以通过,把img先转换为float32类型,再进行除法即可
从简单逻辑到复杂计算:感知机的进化与其在现代深度学习和人工智能中的应用(上)
本文详细探讨了感知机——一种简单形式的人工神经网络,首次由Frank Rosenblatt在1957年提出。文章从感知机的基本原理和结构开始,解释了其如何处理输入和产生输出。通过实例,展示了感知机在模拟基本逻辑门(如与门、或门和与非门)中的应用,并讨论了其在处理更复杂的逻辑函数时的局限性,特别是在尝
强烈推荐!分享4款论文AI检测工具官网
AIPaperPass是AI原创论文写作平台,10分钟产出3万字,提供真实网络数据、图、表、公式、代码,不限次2000字3级大纲,附带ppt、开题报告、任务书、40篇真实参考文献。请注意,以上排名和推荐仅基于个人和市场的普遍评价,具体使用效果可能因个人需求和偏好而有所不同。在使用这些工具时,请确保遵
Ubuntu20.04配置深度学习环境(全网最细最全)
Ubuntu20.04配置深度学习环境
AI在地理信息系统领域的应用
"AI在地理信息系统领域的应用"1.背景介绍1.1 地理信息系统概述地理信息系统(Geographic Information System, GIS)是一种将地理数据与其他描述性信息相结合,对地理数据进行采集、存储、



