
介绍
我们每天处理的数据最多的类型可能是时间序列数据。基本上,使用日期,时间或两者同时索引的任何内容都可以视为时间序列数据集。在我们工作中,可能经常需要使用日期和时间本身来过滤时间序列数据。根据任何其他形式的索引过滤dataframe是一件相当麻烦的任务。尤其是当日期和时间在不同的列中时。
幸运的是,我们有Pandas和Streamlit在这方面为我们提供帮助,并且可以方便的创建和可视化交互式日期时间过滤器。我认为我们大多数人对Pandas应该有所了解,并且可能会在我们的数据生活中例行使用它,但是我觉得许多人都不熟悉Streamlit,下面我们从Pandas的简单介绍开始
在处理Python中的数据时,Pandas可以说是最敏捷,高效,灵活,健壮,有弹性工具。这个强大的工具包使您能够而只需几行代码即可操纵,转换以及尤其是可视化dataframe中的数据。在此应用程序中,我们将使用Pandas从CSV文件读取/写入数据,并根据选定的开始和结束日期/时间调整数据框的大小。流光
Streamlit是一个纯粹的Python API,它允许你创建机器学习应用程序。其实远不止这些。Streamlit是一个web框架,他将一个准端口转发代理服务器和一个前端UI库混合在一起。简单地说,你可以为了各种目的开发和部署无数的web应用程序(或本地应用程序)。对于我们的应用程序,我们将使用Streamlit为我们的时间序列数据渲染一个交互式滑动过滤器,该数据也将即时可视化。
python包
import pandas as pd
import streamlit as st
import datetime
import re
import base64
如果你需要安装上面的任何一个包,请使用“pip install”,例如以下命令
pip install streamlit
数据集
我们将使用随机生成的数据集,它有一个日期、时间和值的列,如下所示。
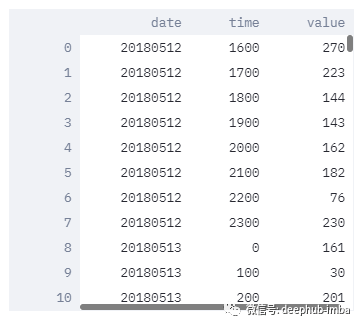
日期格式如下:
YYYYMMDD
而时间格式为:
HHMM
可以使用任何其他格式来格式化日期时间,但是您必须确保按照后续部分中的说明在脚本中声明它。
日期时间过滤器
为了实现我们的过滤器,我们将使用以下函数作为参数— message和df,它们与滑块小部件显示的消息以及需要过滤的原始dataframe相对应。
def df_filter(message,df):
slider_1, slider_2 = st.slider('%s' % (message),0,len(df)-1,[0,len(df)-1],1)
while len(str(df.iloc[slider_1][1]).replace('.0','')) < 4:
df.iloc[slider_1,1] = '0' + str(df.iloc[slider_1][1]).replace('.0','')
while len(str(df.iloc[slider_2][1]).replace('.0','')) < 4:
df.iloc[slider_2,1] = '0' + str(df.iloc[slider_1][1]).replace('.0','')
start_date = datetime.datetime.strptime(str(df.iloc[slider_1][0]).replace('.0','') + str(df.iloc[slider_1][1]).replace('.0',''),'%Y%m%d%H%M%S')
start_date = start_date.strftime('%d %b %Y, %I:%M%p')
end_date = datetime.datetime.strptime(str(df.iloc[slider_2][0]).replace('.0','') + str(df.iloc[slider_2][1]).replace('.0',''),'%Y%m%d%H%M%S')
end_date = end_date.strftime('%d %b %Y, %I:%M%p')
st.info('Start: **%s** End: **%s**' % (start_date,end_date))
filtered_df = df.iloc[slider_1:slider_2+1][:].reset_index(drop=True)
return filtered_df
首先,我们将调用Streamlit slider小部件,文档如下所示。
streamlit.slider(label, min_value, max_value, value, step)
参数如下
label (str或None) -一个短标签,向用户解释这个滑块的用途。
min_value(支持的类型或无)—最小允许值。如果值是一个int型,默认为0,如果是float型,默认为0.0,如果是date/datetime, time. value - timedelta(days=14)。最小时间
max_value(支持的类型或None) -最大允许值。如果值是int类型,默认值为100,如果是float类型,默认值为1.0,如果是date/datetime, time,则value + timedelta(days=14)。max if a time
value(一个支持的类型或一个元组/支持的类型列表或None) -滑块第一次呈现时的值。如果在这里传递一个包含两个值的元组/列表,则会呈现一个带有上下边界的范围滑块。例如,如果设置为(1,10),滑块将在1到10之间有一个可选择的范围。默认为min_value。
step (int/float/timedelta或None)—步进间隔。默认值为1,如果是浮点数则为0.01,如果是date/datetime则为timedelta(days=1),如果是time(或者max_value - min_value < 1 day)则为timedelta(minutes=15)
请注意,我们的滑块将返回两个值,即开始日期时间和结束日期时间值。因此,我们必须使用数组声明滑块的初始值为:
[0,len(df)-1]
我们必须将小部件等同于如下所示的两个变量,即用于过滤dataframe的开始和结束日期时间索引:
slider_1, slider_2 = st.slider('%s' % (message),0,len(df)-1,[0,len(df)-1,1)
还需要从我们的开始/结束时间列中删除任何后面的小数点位,并在时间少于一个小时的情况下添加前面的零,即12:00AM引用为0,如下所示:
while len(str(df.iloc[slider_1][1]).replace('.0','')) < 4:
df.iloc[slider_1,1] = '0' + str(df.iloc[slider_1][1]).replace('.0','')
然后,我们需要将日期添加到时间中,并以使用datetime可以理解的格式解析我们的datetime。Python中的strptime绑定如下所示:
start_date = datetime.datetime.strptime(str(df.iloc[slider_1][0]).replace('.0','') + str(df.iloc[slider_1][1]).replace('.0',''),'%Y%m%d%H%M%S')
为了显示我们选择的日期时间,我们可以使用strftime函数来重新格式化开始/结束,如下所示:
start_date = start_date.strftime('%d %b %Y, %I:%M%p')
最后,我们将显示选定的日期时间,并将过滤后的索引应用到我们的数据集,如下所示:
st.info('Start: **%s** End: **%s**' % (start_date,end_date)) filtered_df = df.iloc[slider_1:slider_2+1][:].reset_index(drop=True)
Streamlit应用
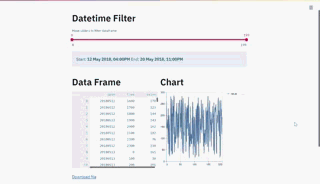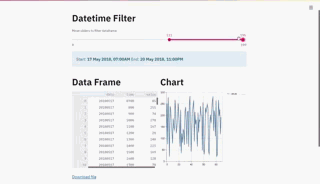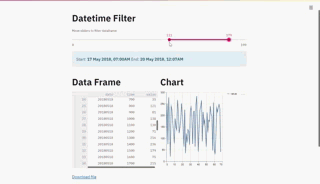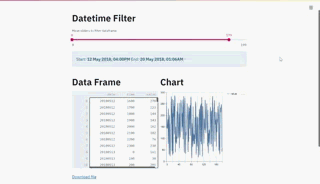
最后,我们可以将所有内容绑定在一个Streamlit 应用程序的形式中,该应用程序将渲染datetime过滤器、dataframe和折线图,当我们移动滑块时,这些都将即时更新。
if __name__ == '__main__':
df = pd.read_csv('file_path')
st.title('Datetime Filter')
filtered_df = df_filter('Move sliders to filter dataframe',df)
column_1, column_2 = st.beta_columns(2)
with column_1:
st.title('Data Frame')
st.write(filtered_df)
with column_2:
st.title('Chart')
st.line_chart(filtered_df['value'])
st.markdown(download_csv('Filtered Data Frame',filtered_df),unsafe_allow_html=True)
您可能会发现将过滤后的dataframe下载为CSV文件非常方便。如果是这样,请使用以下函数在您的Streamlit应用程序中创建一个可下载的文件。
def download_csv(name,df):
csv = df.to_csv(index=False)
base = base64.b64encode(csv.encode()).decode()
file = (f'<a href="data:file/csv;base64,{base}" download="%s.csv">Download file</a>' % (name))
return file
这个函数的参数- name和df分别对应于需要转换为CSV文件的可下载文件和dataframe的名称。
最后,运行我们的程序
streamlit run file_name.py
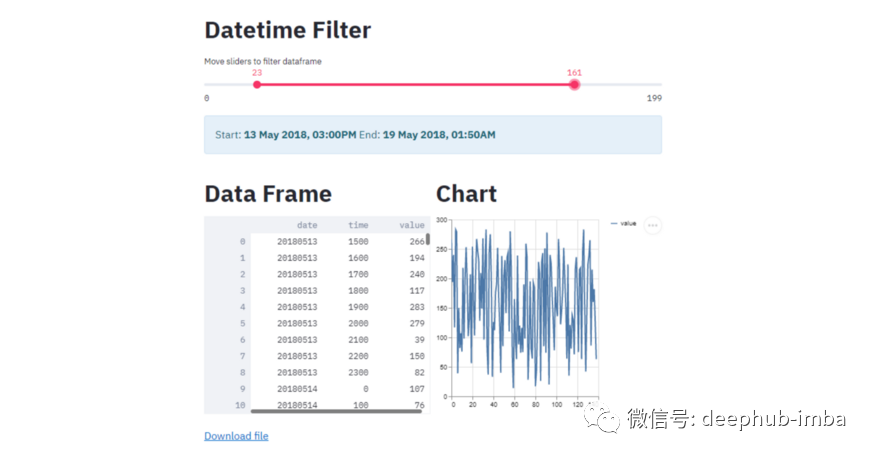
结果
一个交互式仪表板,允许你可视化地过滤你的时间序列数据,并在同一时间可视化它!
本文代码:https://github.com/mkhorasani/interactive_datetime_filter
作者:M Khorasani
deephub翻译组