
一个故事:你已经做了10年的自由职业者了。到目前为止,你的平均年收入约为8万美元。今年,你觉得自己陷入了困境,决定要达到6位数。要做到这一点,你需要先计算这一令人兴奋的成就发生的概率,但你不知道怎么做。
在世界上有许多场景,其中存在某个随机事件的已知概率,企业希望发现该事件在未来发生的概率大于或小于这个概率。例如,已经知道自己平均销售额的零售商所有者会试图猜测他们在黑色星期五或双十一等特殊日子能多赚多少钱。这将帮助他们储存更多的产品,并相应地管理他们的员工。
在这篇文章中,我们将讨论用于模拟上述情况的泊松分布背后的理论,如何理解和使用它的公式,以及如何使用Python代码来模拟它。
离散型概率分布
这篇文章假设你对概率有一个基本的了解。在我们开始真正的文章之前,我们将建立一些对离散概率分布的理解。
首先,让我们定义离散的含义。在描述统计学中,离散数据是通过计数记录或收集的任何数据,即整数。例如考试分数、停车场里的汽车数量、医院里的分娩数量等。
然后,有一些随机实验会产生离散的结果。例如,抛硬币有两种结果:正面和反面(1和0),掷骰子有6种离散结果,以此类推。如果用一个随机变量X来存储离散实验的可能结果,那么它将具有离散概率分布。
概率分布记录了随机实验的所有可能结果。
作为一个简单的例子,让我们来构建一次抛硬币的分布:
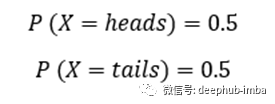
这很容易。如果我们想以编程的方式记录这个分布,它应该是Python列表或Numpy数组的形式:

然而,你可以想象,对于有许多可能结果的大型实验,用这种方法建立分布并找到概率是不可能的。值得庆幸的是,每个概率分布都有自己的公式来计算任何结果的概率。对于离散概率分布,这些函数称为概率质量函数(PMF)。
泊松分布
我们将通过一个案例来开始理解泊松分布。假如你真的很喜欢在医院里看新生儿。根据你的观察和报告,你知道医院平均每小时出生6个新生儿。
你发现你明天要出差,所以在去机场之前,你想最后一次去医院。因为你要离开好几个月,你想看到尽可能多的新生儿,所以你想知道在起飞前一小时是否有机会见到10个或更多的婴儿。
如果我们把观察新生儿作为一个随机实验,结果将遵循经典的泊松分布。原因是它满足泊松分布的所有条件:
有一个已知的事件速率:平均每小时有6个新生儿
事件是独立发生的:1婴儿的出生并不影响下一个婴儿的出生时间
已知的出生率随时间是不变的:平均每小时婴儿的数量不随时间变化
两件事不会在同一时刻发生(每个结果都是离散的)
泊松分布具有许多重要的业务含义。企业通常使用他来预测某一天的销售额或客户数量,因为他们知道每天的平均价格。做出这样的预测有助于企业在生产、调度或人员配备方面做出更好的决策。例如,库存过多意味着销售活动减少,或者没有足够的商品意味着失去商机。
简而言之,泊松分布有助于发现事件在固定时间间隔内发生的概率大于或小于已经记录的速率(通常表示为λ(lambda))。
其概率质量函数为:
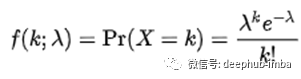
这个公式的字母含义如下:
- k是成功的次数(期望发生的次数)
- λ是给定的速率
- e为欧拉数,e = 2.71828…
- k !是k的阶乘吗
使用这个公式,我们可以求出看到10个新生儿知道平均出生率为6的概率:
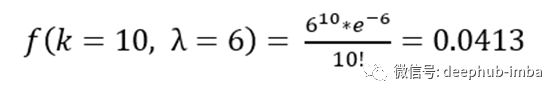
不幸的是,只有大约4%的几率能看到10个孩子。
我们不会详细讲解这个公式是如何推导出来的,但如果你感兴趣,请观看可汗学院的视频。
还有一些要点你必须记住。即使有一个已知的速率,它只是一个平均值,所以事件的时间可能是完全随机的。例如,你可以观察两个背靠背出生的婴儿,或者你可能会为下一个婴儿等待半个小时。
而且,在实践中,λ的速率可能不总是恒定的。这甚至适用于我们的新生儿实验。即使这个条件不成立,我们仍然可以认为分布是泊松分布,因为泊松分布足够接近,可以模拟情况的行为。
模拟泊松分布
利用numpy从泊松分布中模拟或抽取样本非常容易。我们首先导入它,并使用它的随机模块进行模拟:
import numpy as np
从泊松分布中提取样本,我们只需要速率参数λ。我们把它插入np,随机的。泊松函数,并指定样本个数:
poisson = np.random.poisson(lam=10, size=10000)
这里,我们模拟了一个速率为10的分布,有10k个数据点。为了看到这个分布,我们将绘制其PMF的结果。虽然我们可以手工完成,但已经有一个非常好的包叫empiricaldist,由艾伦·b·唐尼(Allen B. Downey)撰写,他是《ThinkPython》(ThinkPython)和《ThinkStats》(ThinkStats)等著名著作的作者。我们将安装并导入其Pmf函数到我们的环境中:
from empiricaldist import Pmf # pip install empiricaldist
Pmf有一个名为from_seq的函数,它接受任何分布并计算Pmf:
poisson = np.random.poisson(lam=10, size=10000)
pmf_poisson = Pmf.from_seq(poisson)
pmf_poisson

回想一下,PMF显示了每个唯一结果的概率,所以在上面的结果中,结果被作为指数和概率下的概率给出。让我们使用matplotlib来绘制它:
# Create figure and axes objects
fig, ax = plt.subplots(figsize=(20, 10))
# Plot the PMF
ax.plot(pmf_poisson, marker='.') # label each data point with a dot
# Labelling
ax.set(title='Probability Mass Function of Poisson Distribution',
ylabel='P (X = x)', xlabel='Number of events')
plt.show();
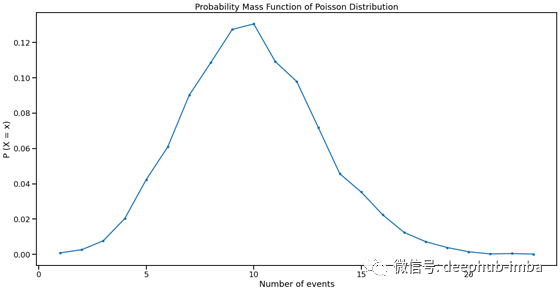
正如预期的那样,最高的概率是均值(速率参数,λ)。
现在,让我们假设我们忘记了泊松分布的PMF公式。如果我们做观察新生儿的实验,我们如何求出看到10个新生儿而比率为6的概率呢?
首先,我们用给定的速率作为参数来模拟完美泊松分布。同时,为了获得更好的精度,我们会绘制大量的样本:
child_births = np.random.poisson(lam=6, size=1000000)
我们对一个速率为6,长度为100万的分布进行抽样。接下来,我们看看他们中有多少人有10个孩子:
births_10 = np.sum(child_births == 10)
>>> births_10
41114
所以,我们在41114个试验中观察了10个婴儿(每个小时可以考虑有一个试验)。然后,我们用这个数除以样本总数:
>>> births_10 / 1e6
0.041114
如果您回想一下,使用PMF公式,结果是0.0413,我们可以看到我们手工编写的解决方案非常接近。
结论
关于泊松分布仍有许多值得探讨的地方。我们讨论了这个词的基本用法及其在商业世界中的含义。泊松分布还有一些有趣的地方比如它和二项分布的关系。
作者:Bex T.
deephub翻译组