
UPerNet:《Unified Perceptual Parsing for Scene Understanding》
发布于2018ECCV。
引文
人类在识别物体上往往是通过多角度多层次的观察来得出物体类别的,包括物体的形状、纹理、位于什么环境背景中、其中包含了什么等等。比如,一扇窗,材质是玻璃,位于墙上,形状为矩形,综合这一堆结论,我们得出:哦!这是一扇窗。
在CV界,有做场景分析的、做材质识别的、做目标检测的、做语义分割的等等,但是很少有将这些任务集成在一个model上的研究,也就是Multi-task任务。
而Multi-task learning的数据集较少,同时制作也较为困难,因为对于不同任务的数据标签是异质的。比如,对于场景分析的ADE20K数据集来说,所有注释都是像素级别的对象,而对于描述纹理信息的数据集DTD(Describe Texture Dataset),标注都是图像级别的。这成为了数据集建立的瓶颈所在。
文章亮点
数据集创建
为了解决缺乏Multi-task 数据集的问题,作者使用Broadly and Densely Labeled Dataset (Broden)来统一了ADE20K、Pascal-Context、Pascal-Part、OpenSurfaces、和Describable Textures Dataset (DTD)这几个数据集。这些数据集中包含了各种场景、对象、对象的部分组成件和材料。接着,作者对类别不均衡问题做了进一步处理,包括删除出现次数少于50张图像的类别、删除像素数少于50000的类别。总之,作者构建了一个十分宏大的Multi-task数据集,总共62,262张图像。
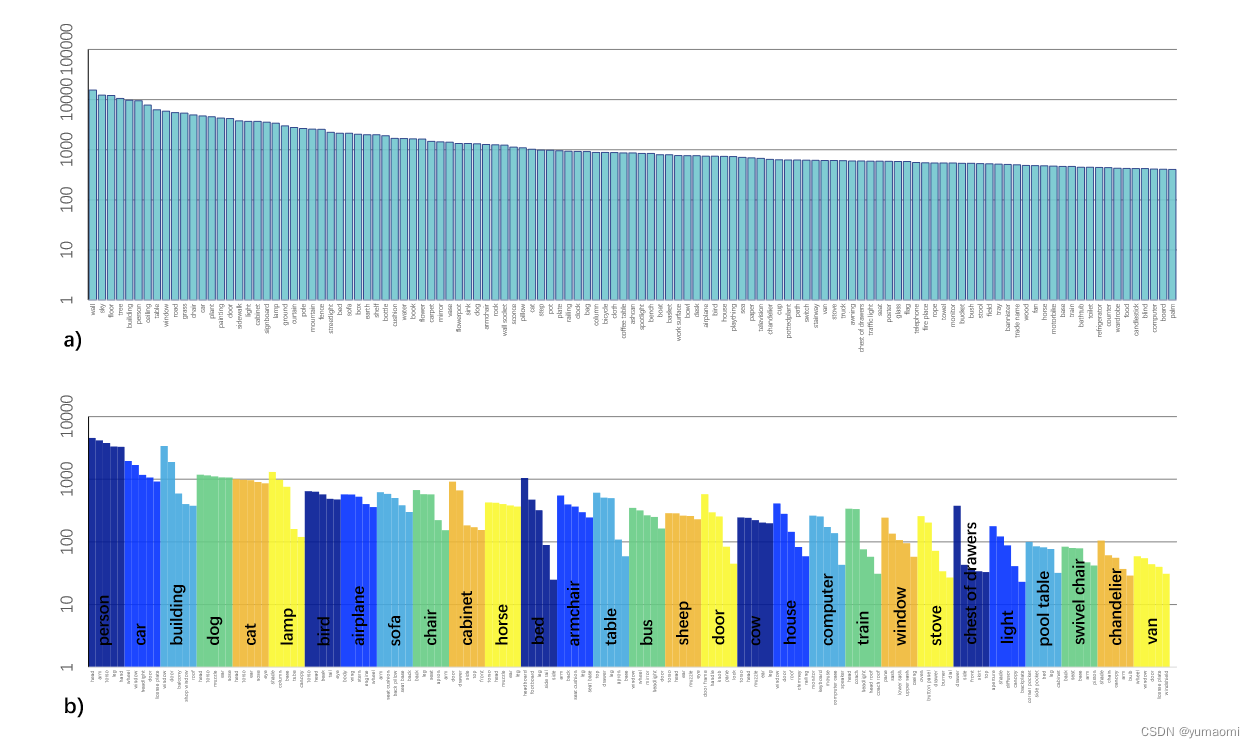
图1 Multi-task Dataset
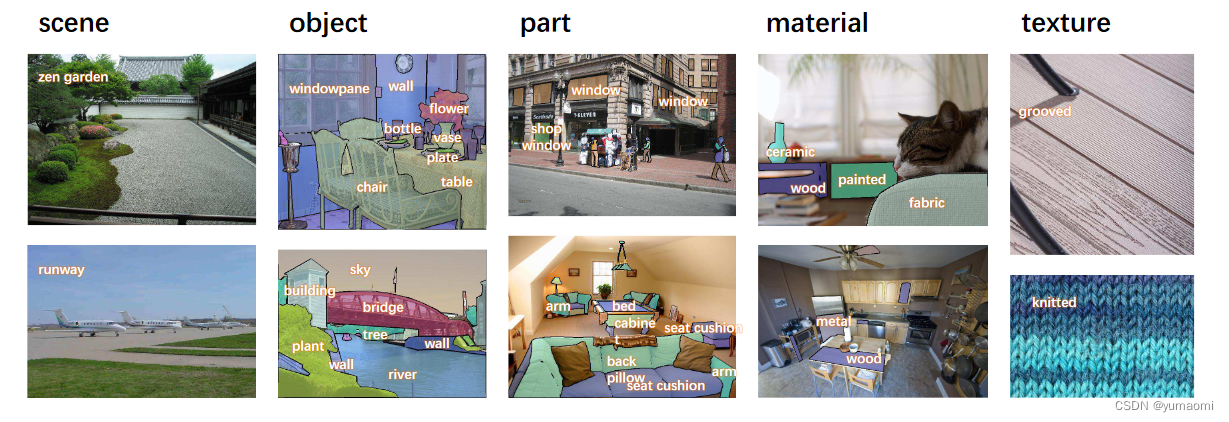
图2 数据集中的一些样本
模型设计
UPerNet的模型设计总体基于FPN(Feature Pyramid Network)和PPM(Pyramid Pooling Module),如下图。
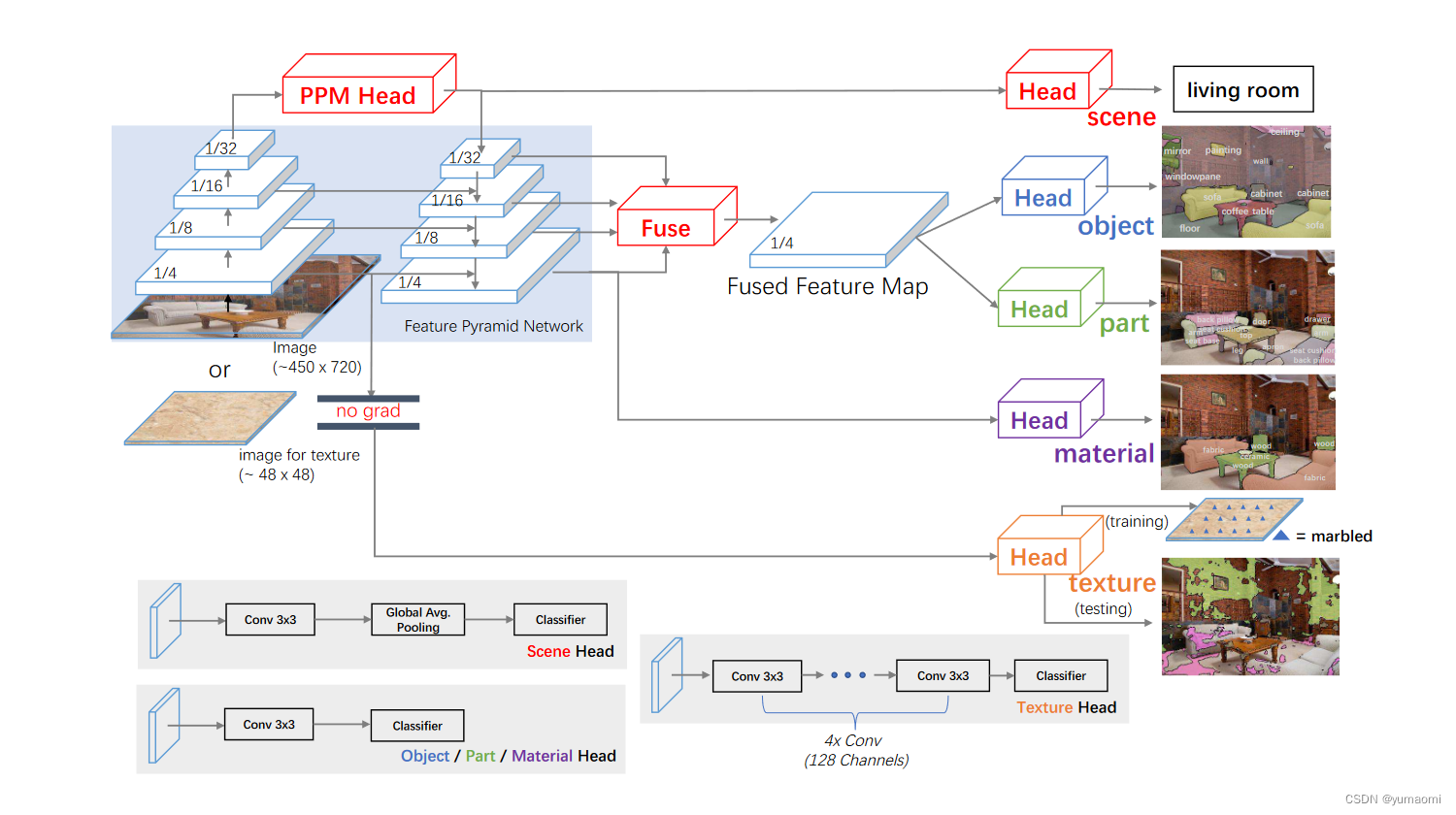
图3 UPerNet模型设计
作者为每一个task设计了不同的检测头。
- 对于Scene parse任务,由于场景类别的注释是图像级别的,所有并不需要做上采样操作,直接在PPM Head的输出后,连接一个卷积、池化和线性分类器即可。
- 对于Object和Object part segmentation任务,也就是语义分割任务,UPerNet在FPN的每一层做了一个特征融合,将融合后的特征输入两个结构等同的检测头中,完成物体或物体部分的分割。
- 对于Material任务,也就是材质检测任务,需要FPN最后一次的输出结果进行预测,因为对于这些材料,上下文的信息也是十分重要的,比如玻璃材质的杯子,那么在先验上,我们会认为玻璃杯子一般会在桌子上,根据图像中的上下文信息——玻璃杯子在桌子上,相比于没有上下文语义信息的模型来说,拥有更多上下文信息的模型可以更好的去检测这个玻璃杯子。
- 对于Texture task,纹理检测任务,它的检测头是经过特别设计的,而且,额外叠加其它层的信息并与其他检测任务融合的话,对于纹理检测是有害的。因此,在这里,直接将FPN第一层的语义结果作为texture检测头的输入,同时,在检测头Head中额外添加了4个卷积层,每一个卷积层拥有128个通道,同时,该部分的梯度是不允许反向传播的,以避免对其他任务进行干扰。这样设计有几个原因,一是纹理是最低级别的语义信息,也就是纯粹一眼就能看出来的,根本不需要融合高级语义。二是对其他任务进行训练时,模型在无形中就得到了纹理的结果,毕竟同一类物体的纹理往往是同质的,或者说每一个物体都有其对应的纹理。
语义分割部分
当然,本文题名为语义分割系列,作者对于UPerNet的使用也主要局限在语义分割部分,因此,可以对UPerNet的其他分支进行剪枝,删去其他分支的检测头,只保留语义分割部分的检测头即可。也就是下图这样: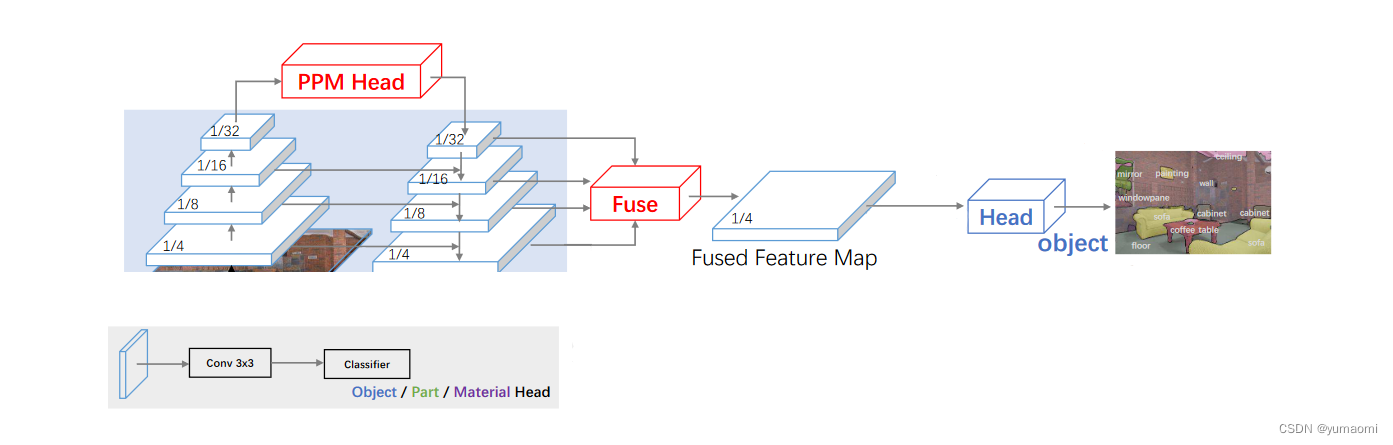
图4 UPerNet语义分割任务部分
论文中的一些结果
Multi-task Learning的分割、分类结果:

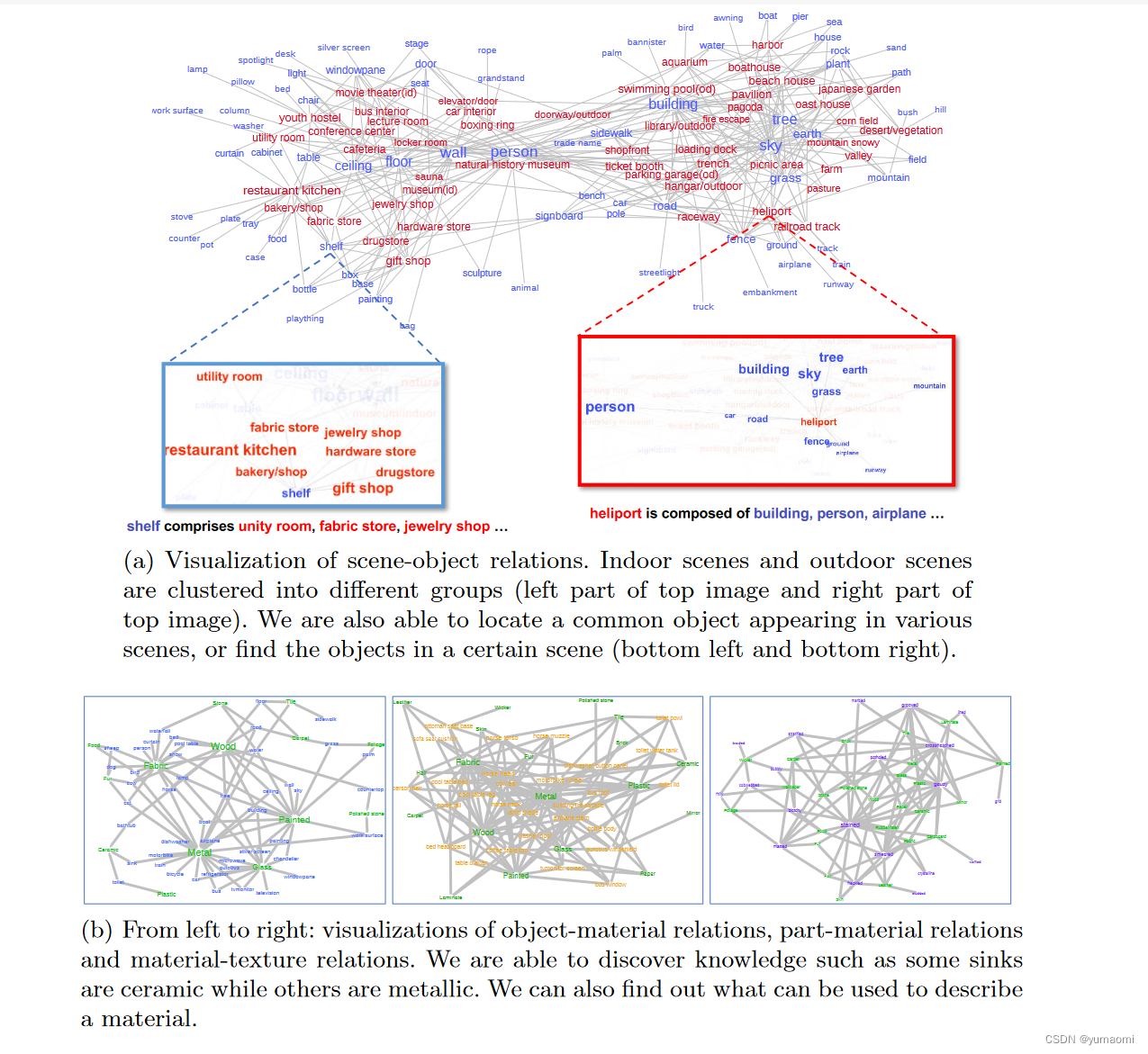
场景中内容物的关系可视化结果:
总结
UPerNet做了一个Multi-task learning的任务示范,创建了一个多任务的数据集。合理设计了UPerNet的主干部分和检测头部分用于不同任务的分类。
模型复现
backbone-ResNet50
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion: int = 4
def __init__(self, inplanes, planes, stride = 1, downsample = None, groups = 1,
base_width = 64, dilation = 1, norm_layer = None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = nn.Conv2d(inplanes, planes ,kernel_size=3, stride=stride,
padding=dilation,groups=groups, bias=False,dilation=dilation)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes ,kernel_size=3, stride=stride,
padding=dilation,groups=groups, bias=False,dilation=dilation)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample= None,
groups = 1, base_width = 64, dilation = 1, norm_layer = None,):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = nn.Conv2d(inplanes, width, kernel_size=1, stride=1, bias=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride, bias=False, padding=dilation, dilation=dilation)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2d(width, planes * self.expansion, kernel_size=1, stride=1, bias=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(
self,block, layers,num_classes = 1000, zero_init_residual = False, groups = 1,
width_per_group = 64, replace_stride_with_dilation = None, norm_layer = None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(
self,
block,
planes,
blocks,
stride = 1,
dilate = False,
):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = stride
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
norm_layer(planes * block.expansion))
layers = []
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
return nn.Sequential(*layers)
def _forward_impl(self, x):
out = []
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
out.append(x)
x = self.layer2(x)
out.append(x)
x = self.layer3(x)
out.append(x)
x = self.layer4(x)
out.append(x)
return out
def forward(self, x) :
return self._forward_impl(x)
def _resnet(block, layers, pretrained_path = None, **kwargs,):
model = ResNet(block, layers, **kwargs)
if pretrained_path is not None:
model.load_state_dict(torch.load(pretrained_path), strict=False)
return model
def resnet50(pretrained_path=None, **kwargs):
return ResNet._resnet(Bottleneck, [3, 4, 6, 3],pretrained_path,**kwargs)
def resnet101(pretrained_path=None, **kwargs):
return ResNet._resnet(Bottleneck, [3, 4, 23, 3],pretrained_path,**kwargs)
Decoder = FPN+PPM
class PPM(nn.ModuleList):
def __init__(self, pool_sizes, in_channels, out_channels):
super(PPM, self).__init__()
self.pool_sizes = pool_sizes
self.in_channels = in_channels
self.out_channels = out_channels
for pool_size in pool_sizes:
self.append(
nn.Sequential(
nn.AdaptiveMaxPool2d(pool_size),
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1),
)
)
def forward(self, x):
out_puts = []
for ppm in self:
ppm_out = nn.functional.interpolate(ppm(x), size=(x.size(2), x.size(3)), mode='bilinear', align_corners=True)
out_puts.append(ppm_out)
return out_puts
class PPMHEAD(nn.Module):
def __init__(self, in_channels, out_channels, pool_sizes = [1, 2, 3, 6],num_classes=31):
super(PPMHEAD, self).__init__()
self.pool_sizes = pool_sizes
self.num_classes = num_classes
self.in_channels = in_channels
self.out_channels = out_channels
self.psp_modules = PPM(self.pool_sizes, self.in_channels, self.out_channels)
self.final = nn.Sequential(
nn.Conv2d(self.in_channels + len(self.pool_sizes)*self.out_channels, 4*self.out_channels, kernel_size=1),
nn.BatchNorm2d(4*self.out_channels),
nn.ReLU(),
)
def forward(self, x):
out = self.psp_modules(x)
out.append(x)
out = torch.cat(out, 1)
out = self.final(out)
return out
class FPNHEAD(nn.Module):
def __init__(self, channels=2048):
super(FPNHEAD, self).__init__()
self.PPMHead = PPMHEAD(in_channels=2048, out_channels=512)
self.Conv_fuse1 = nn.Sequential(
nn.Conv2d(channels//2, channels//2, 1),
nn.BatchNorm2d(channels//2),
nn.ReLU()
)
self.Conv_fuse1_ = nn.Sequential(
nn.Conv2d(channels//2 + channels, channels//2, 1),
nn.BatchNorm2d(channels//2),
nn.ReLU()
)
self.Conv_fuse2 = nn.Sequential(
nn.Conv2d(channels//4, channels//4, 1),
nn.BatchNorm2d(channels//4),
nn.ReLU()
)
self.Conv_fuse2_ = nn.Sequential(
nn.Conv2d(channels//2 + channels//4, channels//4, 1),
nn.BatchNorm2d(channels//4),
nn.ReLU()
)
self.Conv_fuse3 = nn.Sequential(
nn.Conv2d(channels//8, channels//8, 1),
nn.BatchNorm2d(channels//8),
nn.ReLU()
)
self.Conv_fuse3_ = nn.Sequential(
nn.Conv2d(channels//4 + channels//8, channels//8, 1),
nn.BatchNorm2d(channels//8),
nn.ReLU()
)
self.fuse_all = nn.Sequential(
nn.Conv2d(channels*2 - channels//8, channels//4, 1),
nn.BatchNorm2d(channels//4),
nn.ReLU()
)
def forward(self, input_fpn):
x1 = self.PPMHead(input_fpn[-1])
x = nn.functional.interpolate(x1, size=(x1.size(2)*2, x1.size(3)*2),mode='bilinear', align_corners=True)
x = torch.cat([x, self.Conv_fuse1(input_fpn[-2])], dim = 1)
x2 = self.Conv_fuse1_(x)
x = nn.functional.interpolate(x2, size=(x2.size(2)*2, x2.size(3)*2),mode='bilinear', align_corners=True)
x = torch.cat([x, self.Conv_fuse2(input_fpn[-3])], dim = 1)
x3 = self.Conv_fuse2_(x)
x = nn.functional.interpolate(x3, size=(x3.size(2)*2, x3.size(3)*2),mode='bilinear', align_corners=True)
x = torch.cat([x, self.Conv_fuse3(input_fpn[-4])], dim = 1)
x4 = self.Conv_fuse3_(x)
x1 = F.interpolate(x1, x4.size()[-2:],mode='bilinear', align_corners=True)
x2 = F.interpolate(x2, x4.size()[-2:],mode='bilinear', align_corners=True)
x3 = F.interpolate(x3, x4.size()[-2:],mode='bilinear', align_corners=True)
x = self.fuse_all(torch.cat([x1, x2, x3, x4], 1))
return x
model
class UPerNet(nn.Module):
def __init__(self, num_classes):
super(UPerNet, self).__init__()
self.num_classes = num_classes
self.backbone = ResNet.resnet50(replace_stride_with_dilation=[1,2,4])
self.in_channels = 2048
self.channels = 512
self.decoder = FPNHEAD()
self.cls_seg = nn.Sequential(
nn.Conv2d(512, self.num_classes, kernel_size=3, padding=1),
)
def forward(self, x):
x = self.backbone(x)
x = self.decoder(x)
x = nn.functional.interpolate(x, size=(x.size(2)*4, x.size(3)*4),mode='bilinear', align_corners=True)
x = self.cls_seg(x)
return x
Dataset-Camvid
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'dataset\camvid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True,drop_last=True)
model = UPerNet(num_classes=33).cuda()
#model.load_state_dict(torch.load(r"checkpoints/resnet101-5d3b4d8f.pth"), strict=False)
Train
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5, last_epoch=-1)
#训练50轮
epochs_num = 100
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
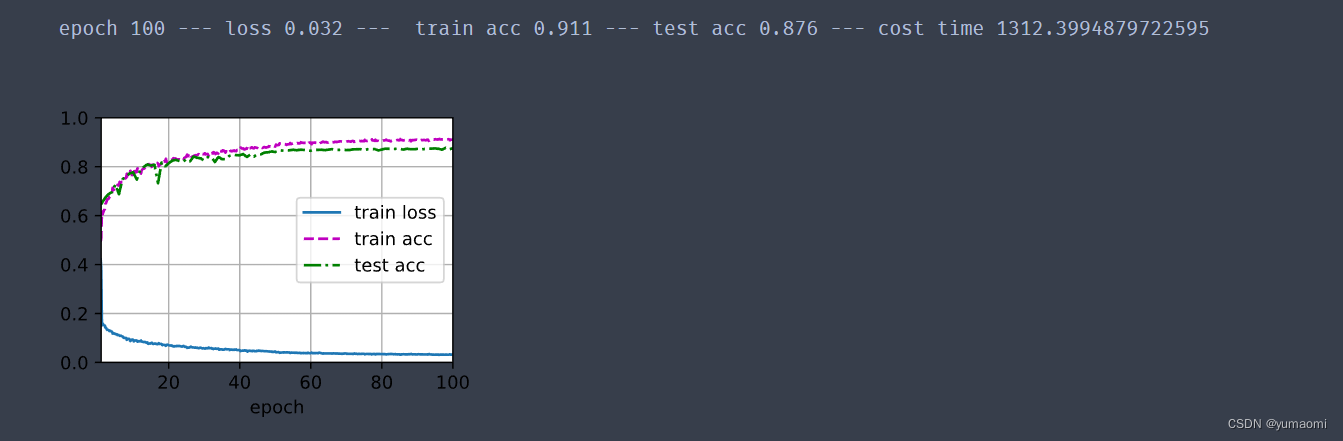
print(f"epoch {epoch+1} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/UPerNet_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/UPerNet_{epoch+1}.pth')
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)
Training curve
版权归原作者 yumaomi 所有, 如有侵权,请联系我们删除。