
ProRL:基于长期强化学习让1.5B小模型推理能力超越7B大模型
这个研究挑战了强化学习仅能放大现有模型输出能力的传统观点,通过实验证明长期强化学习训练(ProRL)能够使基础模型发现全新的推理策略。

SnapViewer:解决PyTorch官方内存工具卡死问题,实现高效可视化
SnapViewer项目通过重新设计数据处理流水线和渲染架构,成功解决了PyTorch官方内存可视化工具的性能瓶颈问题。
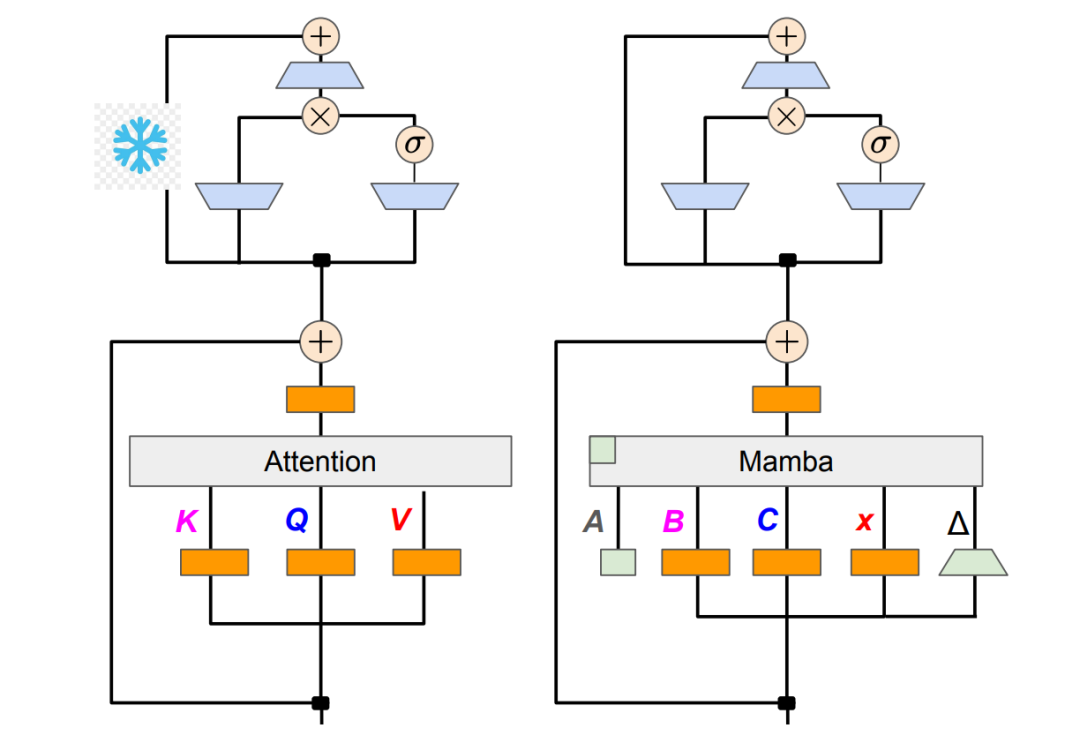
提升长序列建模效率:Mamba+交叉注意力架构完整指南
本文将深入分析Mamba架构中交叉注意力机制的集成方法与技术实现。
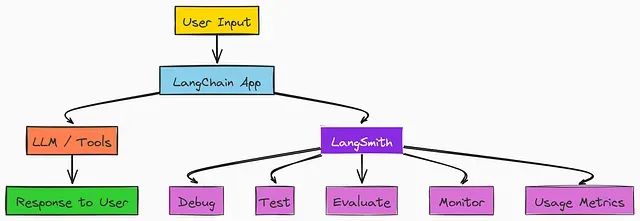
LangGraph实战教程:构建会思考、能记忆、可人工干预的多智能体AI系统
在本文中,我们将使用监督者方法构建一个多智能体系统。在此过程中,我们将介绍基础知识、在创建复杂的 AI 智能体架构时可能面临的挑战,以及如何评估和改进它们。
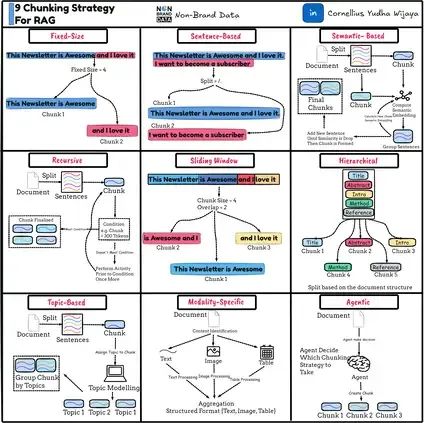
RAG系统文本分块优化指南:9种实用策略让检索精度翻倍
本文将深入分析九种主要的文本分块策略及其具体实现方法。下图概括了我们将要讨论的内容。
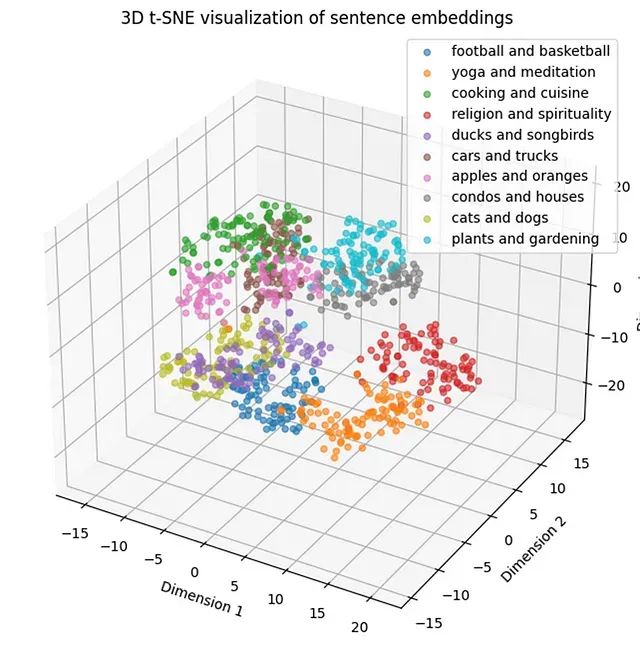
文本聚类效果差?5种主流算法性能测试帮你找到最佳方案
本文讨论的算法代表了工业界最广泛应用且具有实际应用价值的聚类方法,除了谱聚类在句子嵌入领域的应用价值有限之外。

BayesFlow:基于神经网络的摊销贝叶斯推断框架
**BayesFlow** 是一个开源 Python 库,专门设计用于通过**摊销(Amortization)神经网络**来**加速和扩展贝叶斯推断**的能力。该框架通过训练神经网络来学习逆问题(从观测数据推断模型参数)或正向模型(从参数生成观测数据)的映射关系,
基于内存高效算法的 LLM Token 优化:一个有效降低 API 成本的技术方案
该方法的核心原理基于一个关键洞察:LLM 并非需要对每次用户输入都生成回复,而应当区分用户的信息陈述和实际查询请求,仅在后者情况下生成响应。
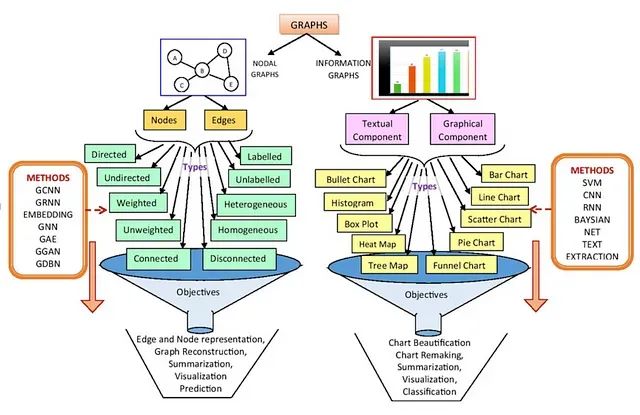
基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
大型概念模型(Large Concept Models, LCMs)与图神经网络的融合为这一挑战提供了创新解决方案,通过构建基于LangGraph的混合符号-语义处理管道,实现了更精准的情感分析、实体识别和主题建模能力。
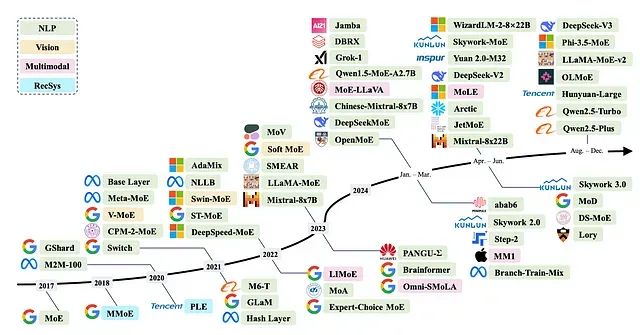
为什么混合专家模型(MoE)如此高效:从架构原理到技术实现全解析
本文将深入分析MoE架构的技术原理,探讨其在大型语言模型中被视为未来发展方向的原因,并详细介绍该架构在当前主要模型中的具体应用实现。
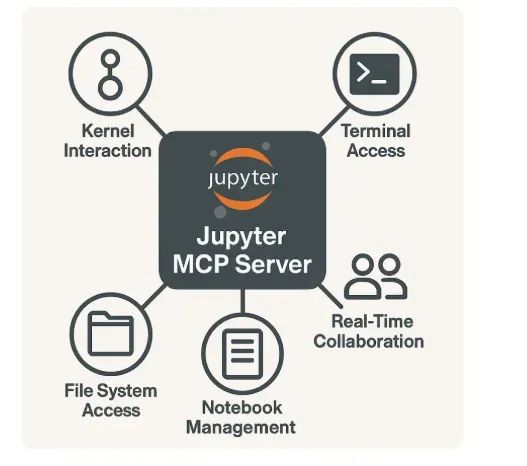
Jupyter MCP服务器部署实战:AI模型与Python环境无缝集成教程
Jupyter MCP 服务器作为模型上下文协议在 Jupyter 生态系统中的具体实现,充当了大型语言模型与用户 Jupyter 工作环境之间的技术桥梁。

图神经网络在信息检索重排序中的应用:原理、架构与Python代码解析
基于图的重排序是信息检索和图机器学习交叉领域一个令人兴奋的发展。通过明确表示检索到的文档以及外部知识之间的关系,这些方法解决了传统检索器孤立地考虑每个文档的局限性。

CUDA重大更新:原生Python可直接编写高性能GPU程序
NVIDIA CUDA架构师Stephen Jones在GTC 2025主题演讲中明确表示:"我们致力于将加速计算与Python进行深度集成,使Python成为CUDA生态系统中具有一等公民地位的编程语言。
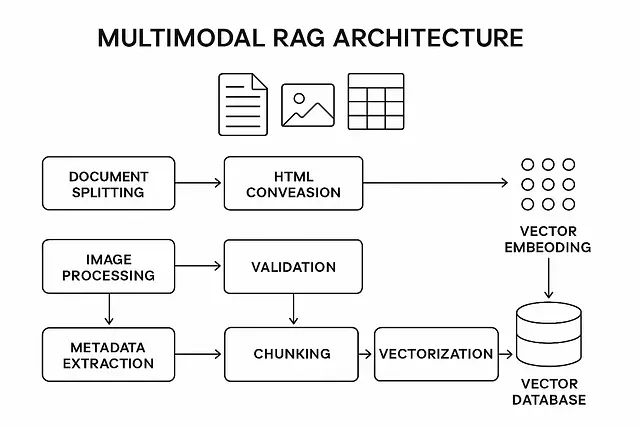
多模态RAG实战指南:完整Python代码实现AI同时理解图片、表格和文本
本文提出的多模态RAG方法采用模态特定处理、后期融合和关系保留的技术架构,在性能表现、准确性指标和实现复杂度之间实现了最佳平衡。通过遵循该技术路线,能够构建一个有效处理复杂文档中全部信息的RAG系统。
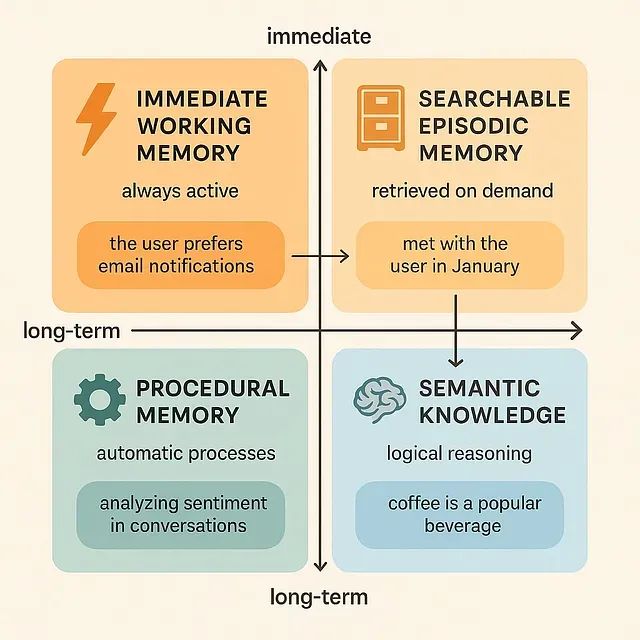
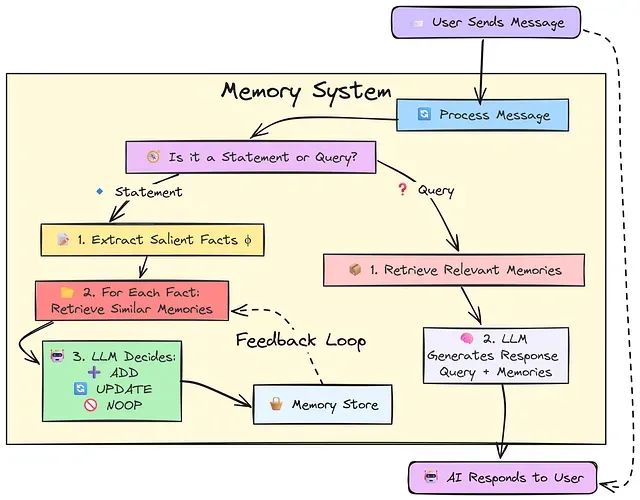
构建智能AI记忆系统:多智能体系统记忆机制的设计与技术实现
本文描述的技术实现方案代表了通过更加复杂的信息管理策略来实现全新类别智能体能力的重要步骤。随着这些记忆系统技术的不断成熟和完善,预期将观察到更多的涌现行为现象,这些行为将解锁智能体系统中意想不到的新能力领域,为人工智能系统的发展开辟新的技术路径。
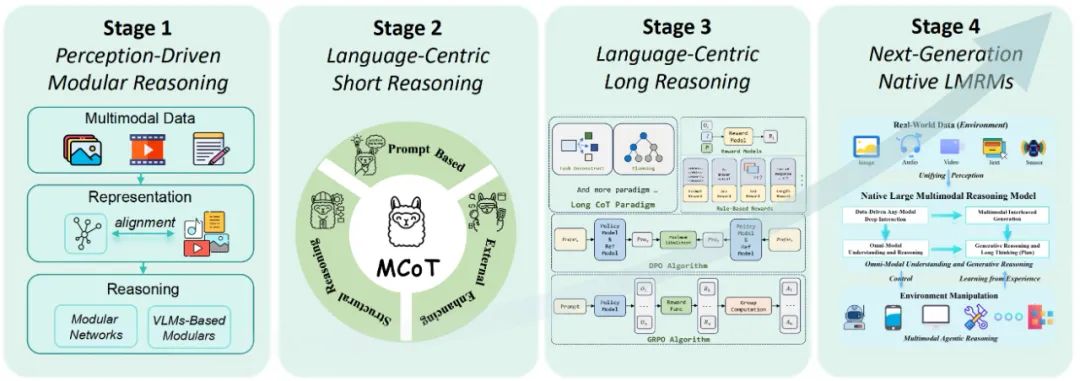
大型多模态推理模型技术演进综述:从模块化架构到原生推理能力的综合分析
该研究对多模态推理研究领域进行了全面而结构化的技术回顾,其组织框架围绕一个反映领域设计理念和新兴能力的四阶段发展路线图展开。这项研究综述涵盖了超过40篇相关学术文献,深入分析了当前模型中存在的关键推理局限性,并提出了一个多阶段的技术发展路线图。
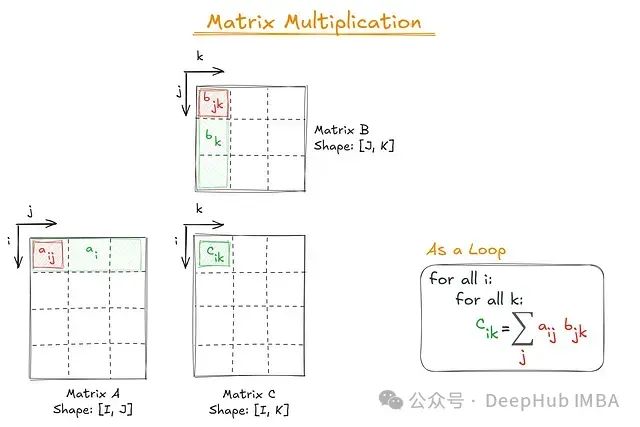
高效处理多维数组:einsum()函数从入门到精通
本文将全面介绍 ``` einsum() ``` 函数——其数学基础、实现原理以及实际应用场景。我们将深入剖析其符号系统,通过实用示例展示其功能,探讨性能优化策略,并提供一个完整的参考速查表辅助实际应用。

5个开源MCP服务器:扩展AI助手能力,高效处理日常工作
本文基于实际部署和使用经验,精选了五种开源MCP服务器实现,从配置到应用场景进行全面剖析,助您快速构建具备环境交互能力的AI系统。
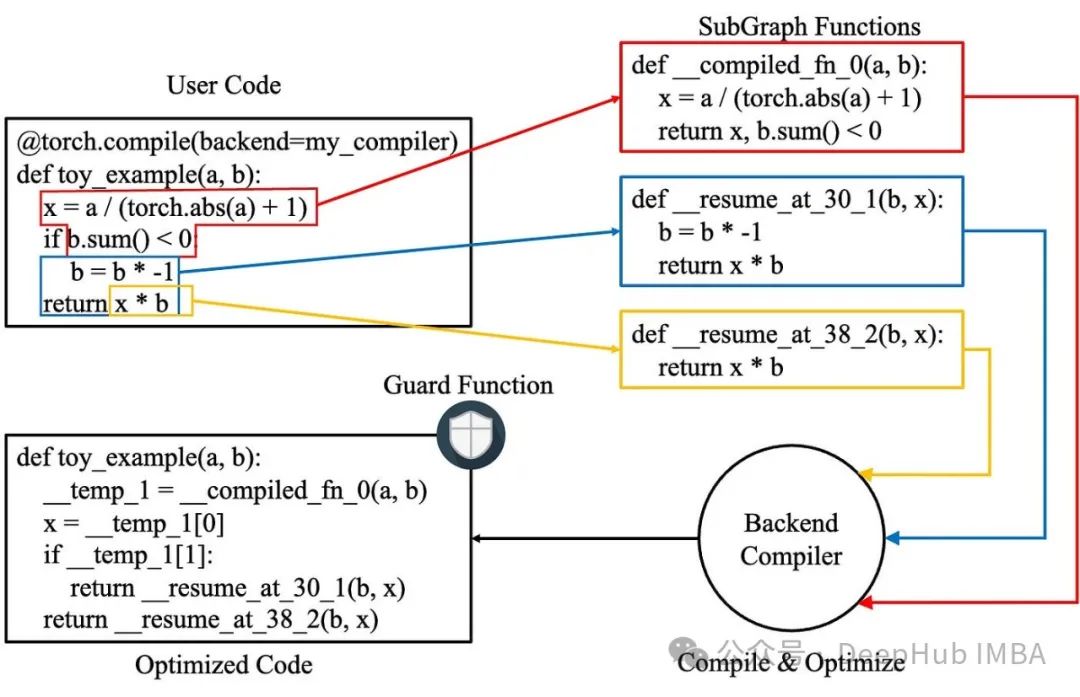
深入解析torch.compile:提升PyTorch模型性能、高效解决常见问题
torch.compile为PyTorch用户提供了强大的性能优化工具,但在实际应用中仍需谨慎处理各种潜在问题。通过系统化的调试策略、深入的组件分析和针对性的优化措施,用户可以有效提升模型性能并解决常见问题。



