
图神经网络在信息检索重排序中的应用:原理、架构与Python代码解析
基于图的重排序是信息检索和图机器学习交叉领域一个令人兴奋的发展。通过明确表示检索到的文档以及外部知识之间的关系,这些方法解决了传统检索器孤立地考虑每个文档的局限性。

CUDA重大更新:原生Python可直接编写高性能GPU程序
NVIDIA CUDA架构师Stephen Jones在GTC 2025主题演讲中明确表示:"我们致力于将加速计算与Python进行深度集成,使Python成为CUDA生态系统中具有一等公民地位的编程语言。
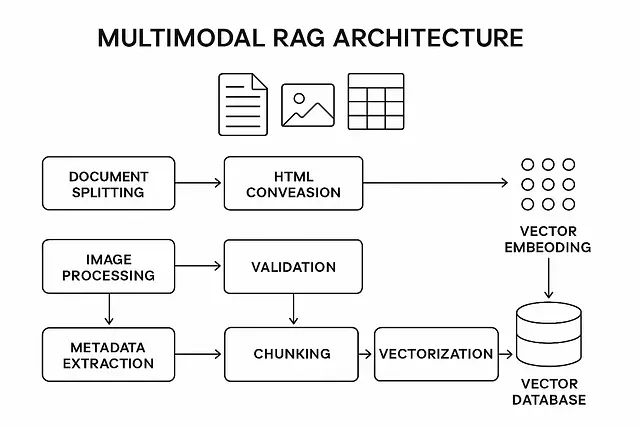
多模态RAG实战指南:完整Python代码实现AI同时理解图片、表格和文本
本文提出的多模态RAG方法采用模态特定处理、后期融合和关系保留的技术架构,在性能表现、准确性指标和实现复杂度之间实现了最佳平衡。通过遵循该技术路线,能够构建一个有效处理复杂文档中全部信息的RAG系统。
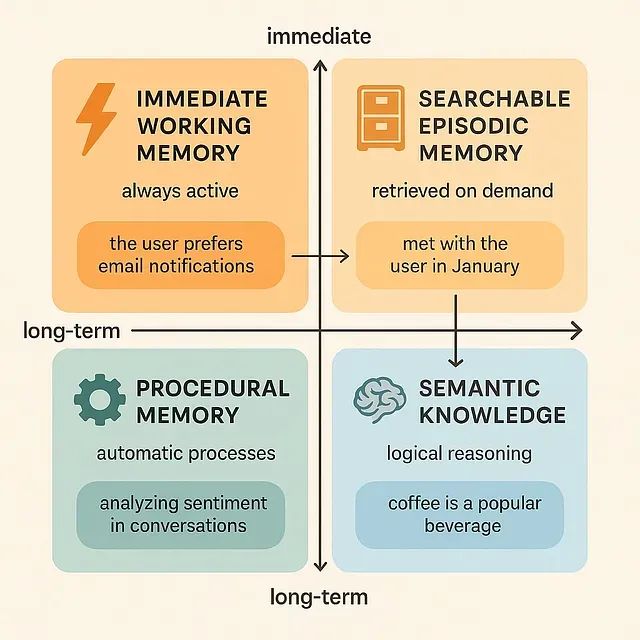
构建智能AI记忆系统:多智能体系统记忆机制的设计与技术实现
本文描述的技术实现方案代表了通过更加复杂的信息管理策略来实现全新类别智能体能力的重要步骤。随着这些记忆系统技术的不断成熟和完善,预期将观察到更多的涌现行为现象,这些行为将解锁智能体系统中意想不到的新能力领域,为人工智能系统的发展开辟新的技术路径。
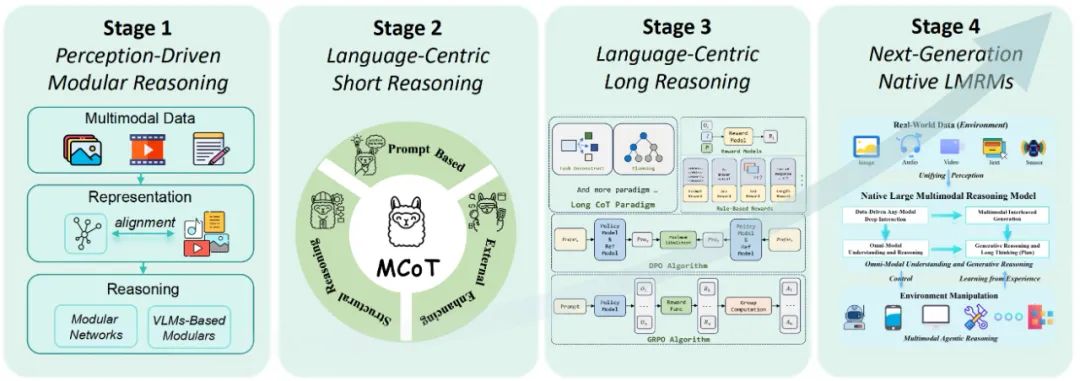
大型多模态推理模型技术演进综述:从模块化架构到原生推理能力的综合分析
该研究对多模态推理研究领域进行了全面而结构化的技术回顾,其组织框架围绕一个反映领域设计理念和新兴能力的四阶段发展路线图展开。这项研究综述涵盖了超过40篇相关学术文献,深入分析了当前模型中存在的关键推理局限性,并提出了一个多阶段的技术发展路线图。
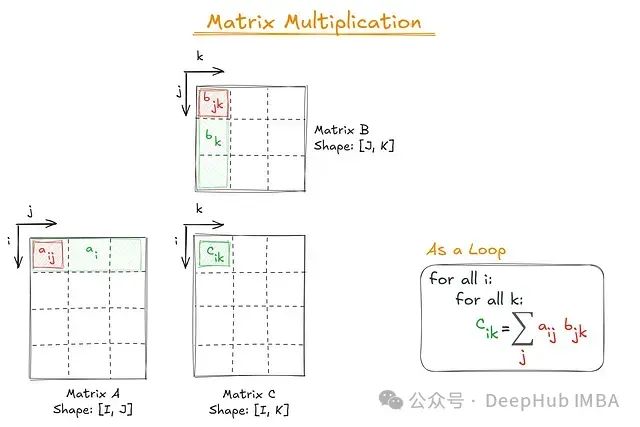
高效处理多维数组:einsum()函数从入门到精通
本文将全面介绍 ``` einsum() ``` 函数——其数学基础、实现原理以及实际应用场景。我们将深入剖析其符号系统,通过实用示例展示其功能,探讨性能优化策略,并提供一个完整的参考速查表辅助实际应用。

5个开源MCP服务器:扩展AI助手能力,高效处理日常工作
本文基于实际部署和使用经验,精选了五种开源MCP服务器实现,从配置到应用场景进行全面剖析,助您快速构建具备环境交互能力的AI系统。
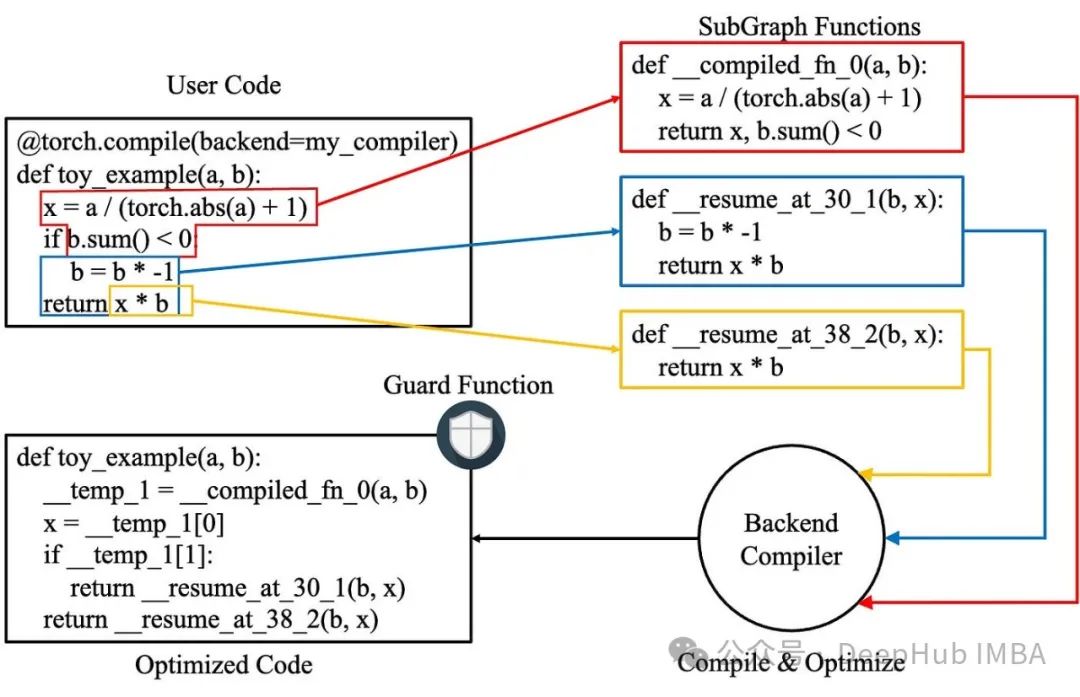
深入解析torch.compile:提升PyTorch模型性能、高效解决常见问题
torch.compile为PyTorch用户提供了强大的性能优化工具,但在实际应用中仍需谨慎处理各种潜在问题。通过系统化的调试策略、深入的组件分析和针对性的优化措施,用户可以有效提升模型性能并解决常见问题。
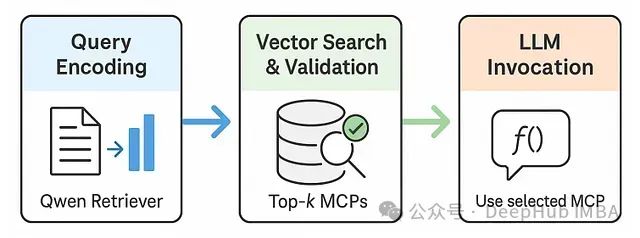
RAG-MCP:基于检索增强生成的大模型工具选择优化框架
RAG-MCP框架不仅具有学术价值,更解决了AI助手和自主代理发展面临的核心瓶颈。随着我们期望LLM在动态环境中执行日益复杂的任务,其高效利用多样化外部工具的能力变得尤为关键。
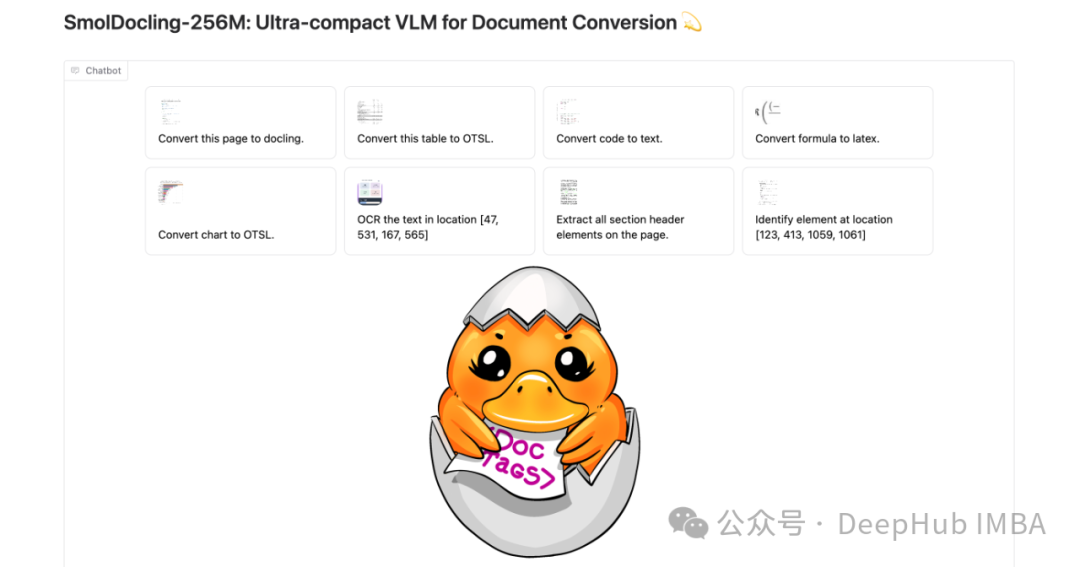
SmolDocling技术解析:2.56亿参数胜过70亿参数的轻量级文档处理模型
SmolDocling基于Hugging Face SmolVLM-256M模型开发而来,是一款体积显著小于同类产品的紧凑型模型。与主流视觉模型相比,其体积减小了5-10倍,仅包含2.56亿个参数。尽管规模较小,其性能水平却足以与参数量为其27倍的大型视觉模型相媲美。
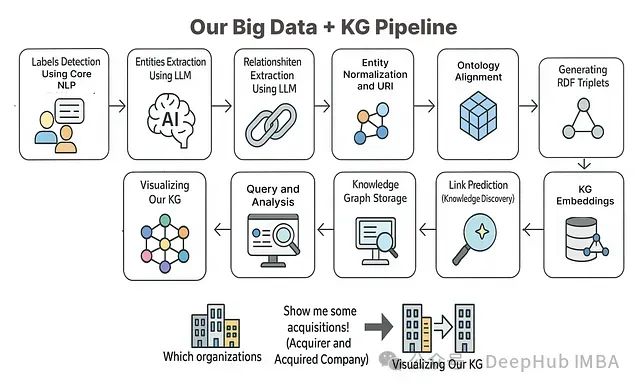
从零构建知识图谱:使用大语言模型处理复杂数据的11步实践指南
本文将基于相关理论知识和方法构建一个完整的端到端项目,系统展示如何利用知识图谱方法对大规模数据进行处理和分析。
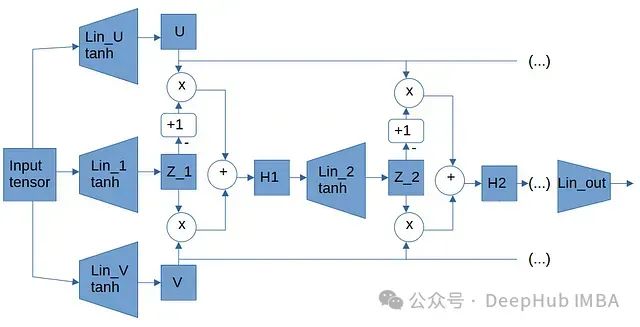
PINN应用案例:神经网络求解热扩散方程高质量近似解
PINN框架的关键组成是一个特殊设计的损失函数,其中包含微分方程残差项。该残差项量化了神经网络解与PDE描述的物理定律之间的偏离程度。
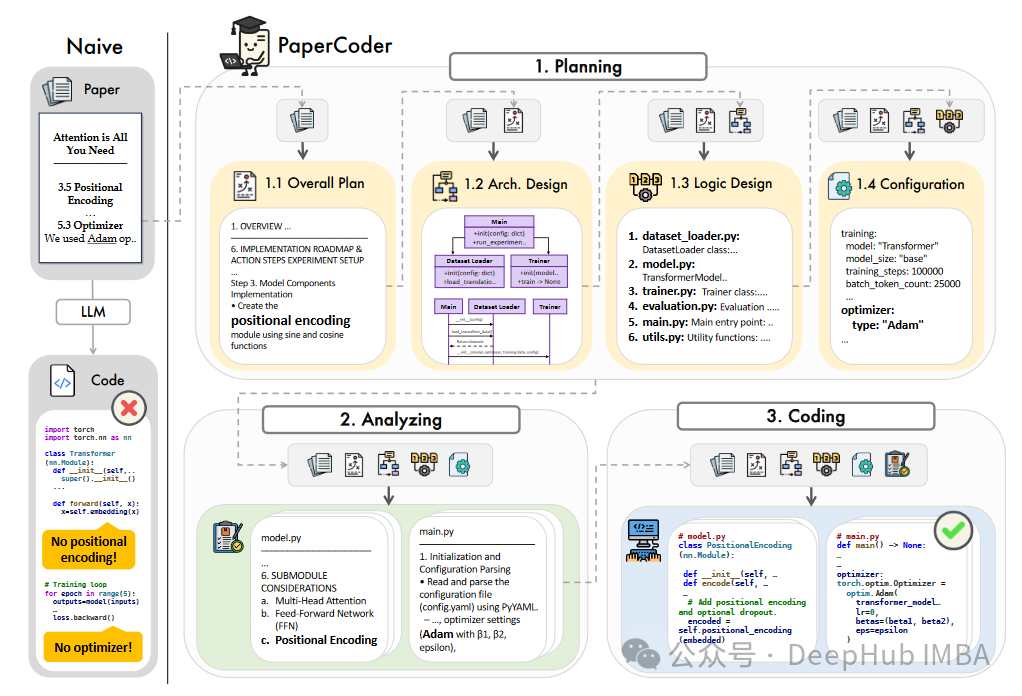
PaperCoder:一种利用大型语言模型自动生成机器学习论文代码的框架
本文介绍了一种名为PaperCoder的新型多智能体LLM框架,旨在自动生成机器学习研究论文的代码库。
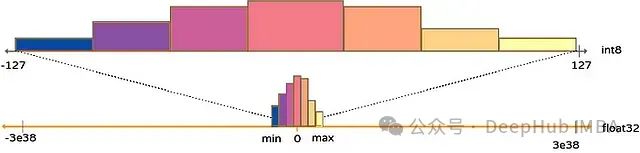
PyTorch量化感知训练技术:模型压缩与高精度边缘部署实践
本文将深入探讨模型量化的原理、主要量化技术类型以及如何使用PyTorch实现这些技术。
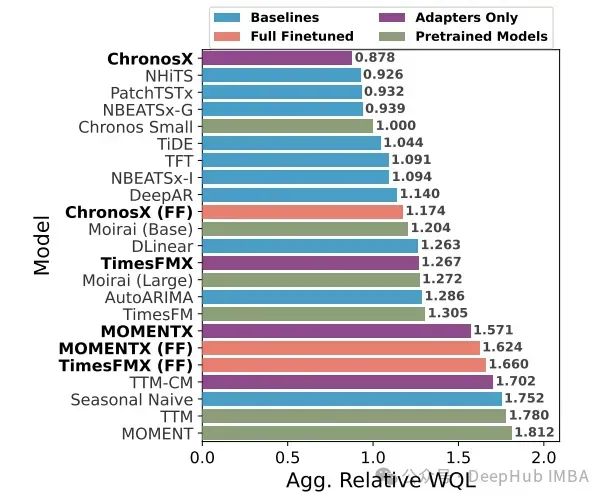
ChronosX: 可使用外生变量的时间序列预测基础模型
本文将系统剖析ChronosX的工作机制,并深入探讨其在多种基准测试中的表现。

PyTorchVideo实战:从零开始构建高效视频分类模型
本文展示了如何使用PyTorchVideo和PyTorch Lightning构建视频分类模型的完整流程。通过合理的数据处理、模型设计和训练策略,我们能够高效地实现视频理解任务。
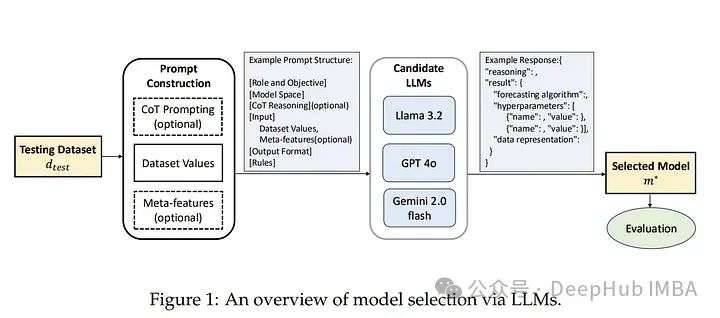
基于大型语言模型的高效时间序列预测模型选择
本文作者提出了一种基于大型语言模型(LLM)的模型选择范式。核心思想是利用LLM(如LLaMA 3.2、GPT-4o、Gemini 2.0)在零样本推理中的知识和推理能力,代替传统的性能矩阵来直接推荐最优模型。

在AMD GPU上部署AI大模型:从ROCm环境搭建到Ollama本地推理实战指南
本文以 AMD Radeon RX 7900XT 为例在 Linux 环境下解决了 ROCm 部署的诸多技术挑战。

提升AI训练性能:GPU资源优化的12个实战技巧
本文系统阐述的优化策略为提升 AI/ML 工作负载中的 GPU 资源利用率提供了全面技术指导。通过实施数据处理并行化、内存管理优化以及模型设计改进等技术手段

使用Torch Compile提高大语言模型的推理速度
在本文中,我们将探讨torch.compile的工作原理,并测量其对LLMs推理性能的影响。



