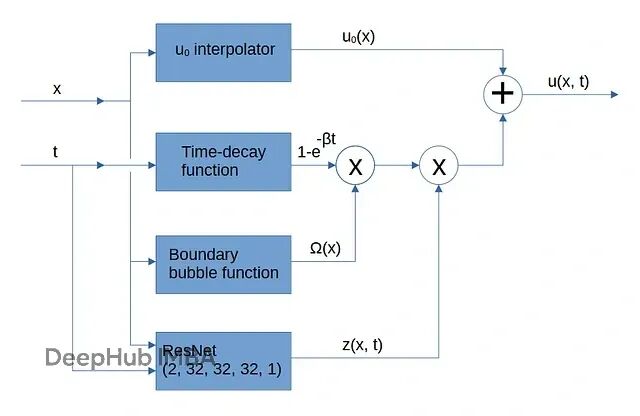
PINN训练新思路:把初始条件和边界约束嵌入网络架构,解决多目标优化难题
PINNs出了名的难训练。主要原因之一就是这个**多目标优化**问题。优化器很容易找到投机取巧的路径
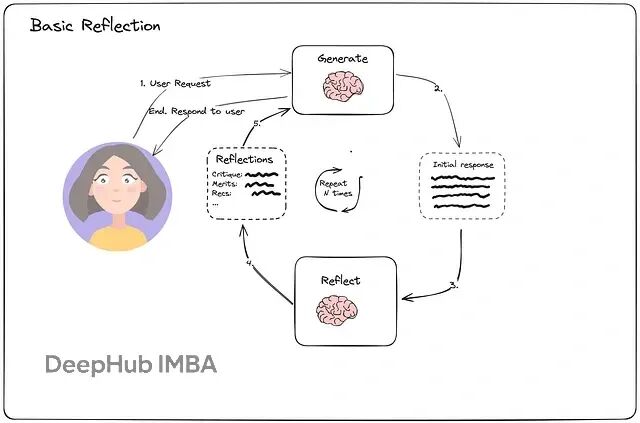
从零构建能自我优化的AI Agent:Reflection和Reflexion机制对比详解与实现
本文重点讨论Reflection和Reflexion,并用LangChain与LangGraph来实现完整的工作流程。
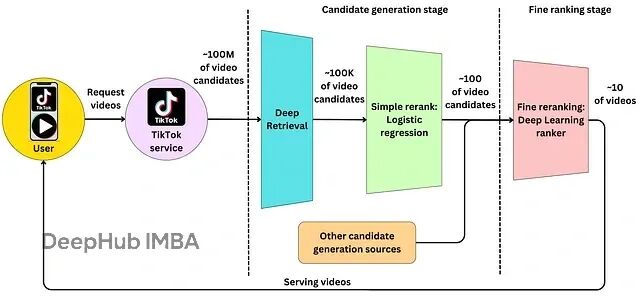
从零构建短视频推荐系统:双塔算法架构解析与代码实现
本文将从技术角度剖析:双塔架构的工作原理、为何在短视频场景下表现卓越,以及如何构建一套类似的推荐系统。
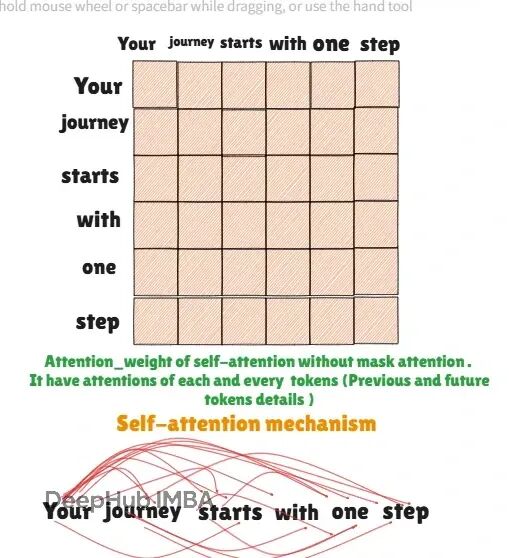
Transformer自回归关键技术:掩码注意力原理与PyTorch完整实现
掩码注意力(Causal Attention)是生成式模型的核心技术,它传统自注意力机制有根本的不同,掩码注意力限制模型只能关注当前位置之前的tokens,确保了自回归生成的因果性。
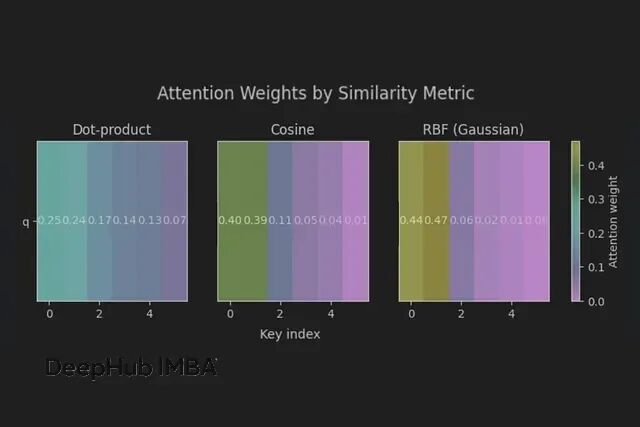
从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力就是一个带温控的概率邻居平均算法。温度设对了(1/sqrt(d)),邻域选对了(相似度+掩码),剩下的就是工程实现了。
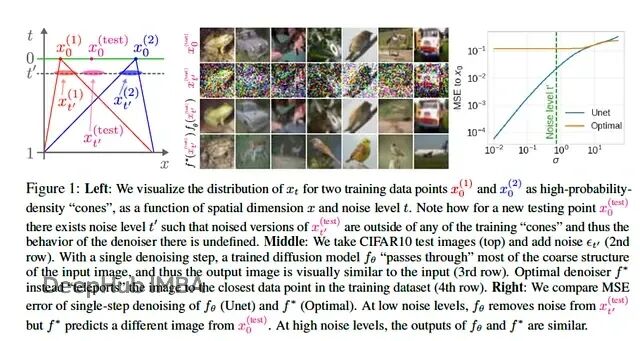
MIT新论文:数据即上限,扩散模型的关键能力来自图像统计规律,而非复杂架构
作者给出证据表明,扩散模型一个被反复强调的属性——关注局部像素关系——并不需要依赖架构的巧妙设计,它可以从训练图像的统计规律中自然涌现。
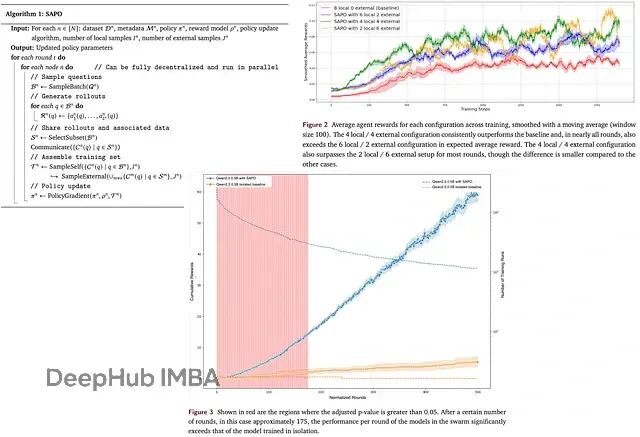
SAPO去中心化训练:多节点协作让LLM训练效率提升94%
SAPO提出了一种去中心化的异步RL方案,让各个计算节点之间可以互相分享rollouts,避开了传统并行化训练的各种瓶颈。
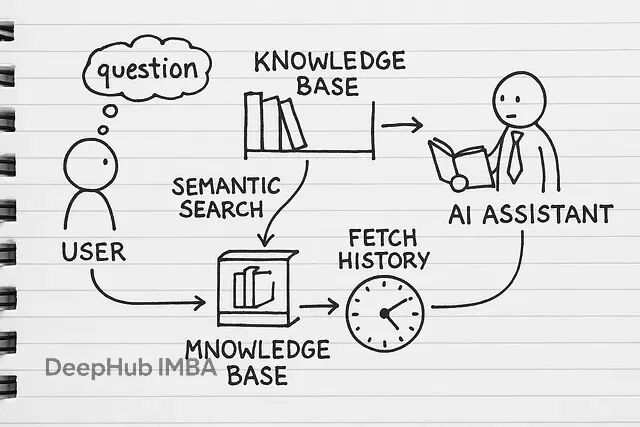
从零搭建RAG应用:跳过LangChain,掌握文本分块、向量检索、指代消解等核心技术实现
RAG(检索增强生成)本质上就是给AI模型外挂一个知识库。平常用ChatGPT只能基于训练数据回答问题,但RAG可以让它查阅你的专有文档——不管是内部报告、技术文档还是业务资料,都能成为AI的参考资源。
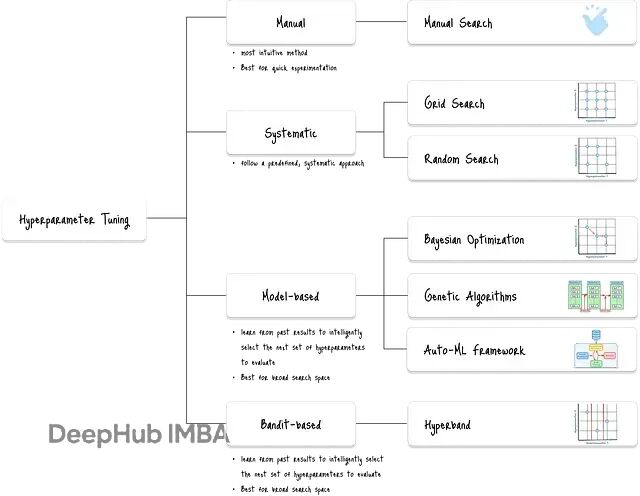
深度学习调参新思路:Hyperband早停机制提升搜索效率
Hyperband是机器学习中一个相当实用的超参数调优算法,核心思路是用逐次减半来分配计算资源。
从零开始构建图注意力网络:GAT算法原理与数值实现详解
本文文会详细拆解GAT的工作机制,用一个具体的4节点图例来演示整个计算过程。如果你读过原论文觉得数学公式比较抽象,这里的数值例子应该能让你看清楚GAT到底是怎么运作的。
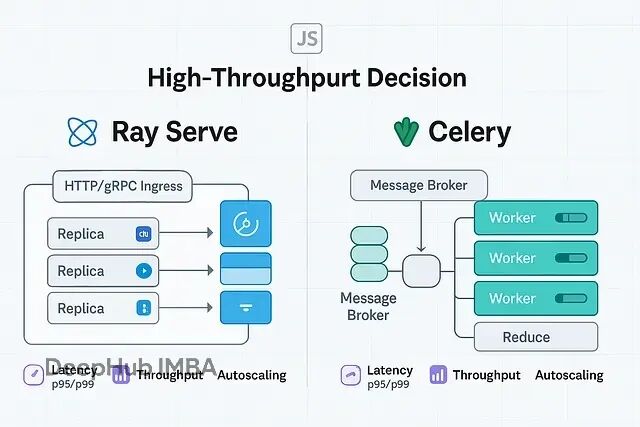
GPU集群扩展:Ray Serve与Celery的技术选型与应用场景分析
当你需要处理大规模并行任务,特别是涉及GPU集群的场景时,Ray Serve和Celery是两个主要选择。但它们的设计理念完全不同

DINOv3上手指南:改变视觉模型使用方式,一个模型搞定分割、检测、深度估计
DINOv3是Meta推出的自监督视觉骨干网络,最大的亮点是你可以把整个backbone冻住不动,只训练一个很小的任务头就能在各种密集预测任务上拿到SOTA结果。
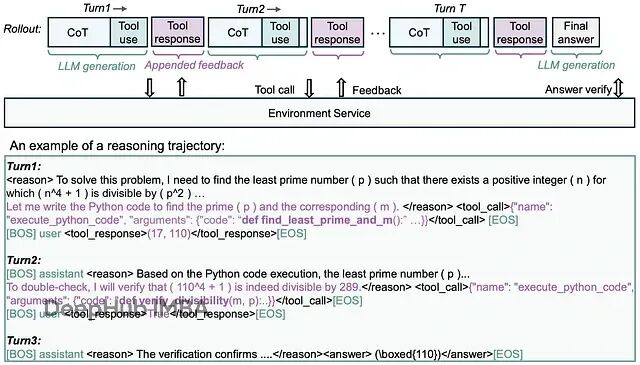
微软rStar2-Agent:新的GRPO-RoC算法让14B模型在复杂推理时超越了前沿大模型
Microsoft Research最近发布的rStar2-Agent展示了一个令人瞩目的结果:一个仅有14B参数的模型在AIME24数学基准测试上达到了80.6%的准确率,超越了671B参数的DeepSeek-R1(79.8%)。
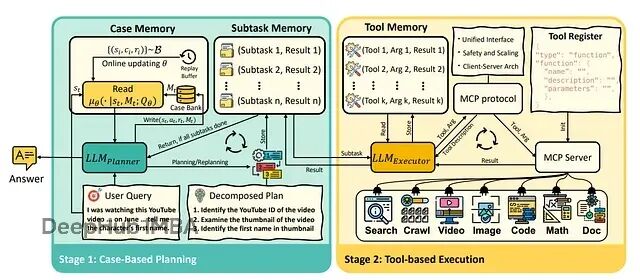
Memento:基于记忆无需微调即可让大语言模型智能体持续学习的框架
Memento框架通过基于记忆的在线强化学习实现低成本持续适应,完全避免了对LLM的微调需求。
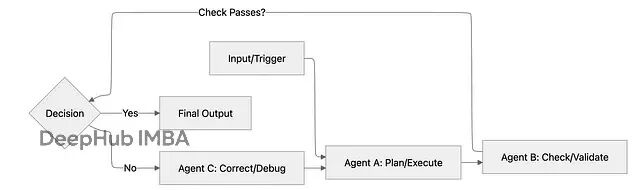
多智能体系统设计:5种编排模式解决复杂AI任务
我们这里分析5种主流的智能体编排模式,每种都有其适用场景和技术特点。
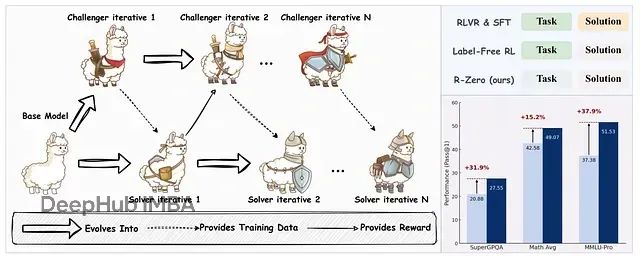
R-Zero:通过自博弈机制让大语言模型无需外部数据实现自我进化训练
R-Zero框架实现了大语言模型在无外部训练数据条件下的自主进化与推理能力提升。
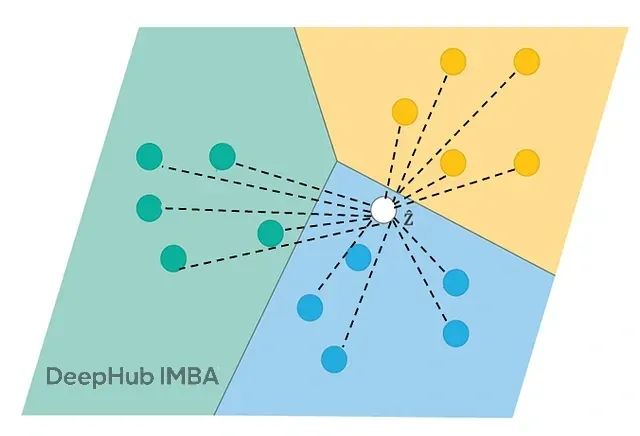
匹配网络处理不平衡数据集的6种优化策略:有效提升分类准确率
匹配网络(**Matching Networks**)是基于度量的元学习方法,通过计算查询样本与支持集中各样本的相似性实现分类。

HiRAG:用分层知识图解决复杂推理问题
该系统基于图检索增强生成(GraphRAG)的核心思想,通过引入层次化架构来处理不同抽象层次的知识复杂度。
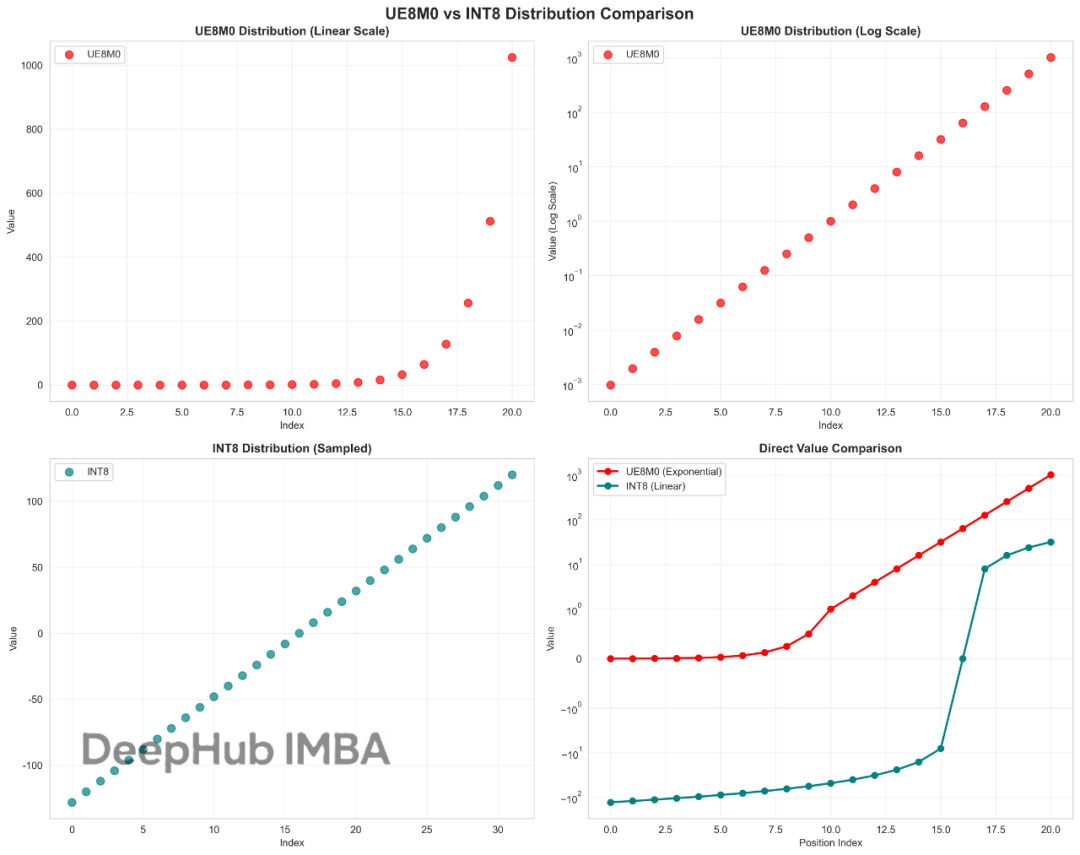
这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析
UE8M0作为FP8格式家族中的一个特殊变体,我们今天来看看这个UE8M0到底是什么。
PyTorch 2.0性能优化实战:4种常见代码错误严重拖慢模型
我们将深入探讨图中断(graph breaks)和多图问题对性能的负面影响,并分析PyTorch模型开发中应当避免的常见错误模式。



