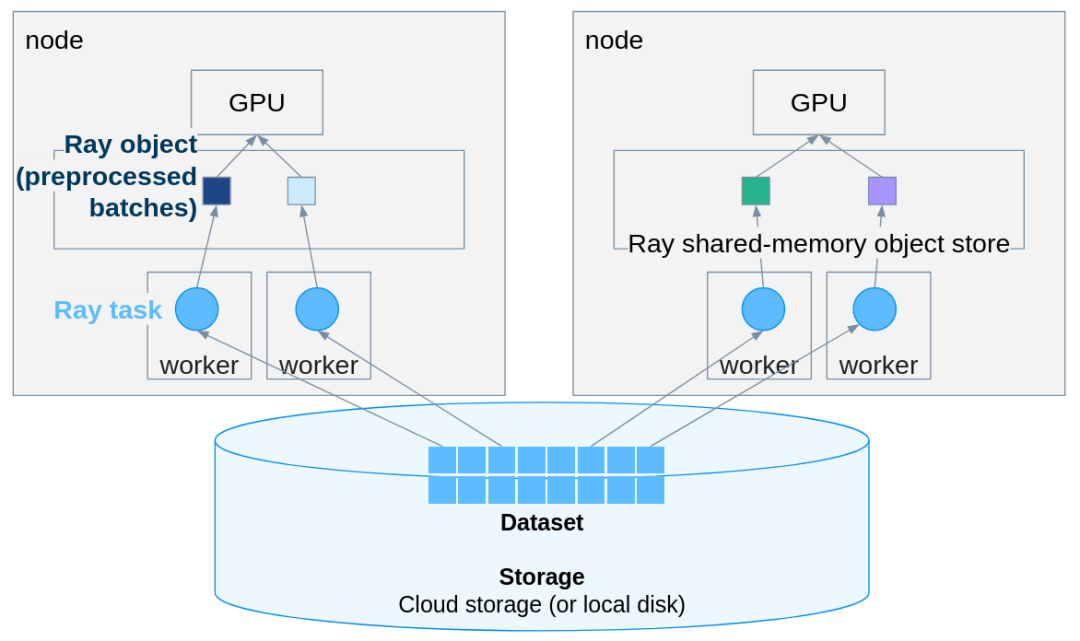
PyTorch推理扩展实战:用Ray Data轻松实现多机多卡并行
Ray Data 在几乎不改动原有 PyTorch 代码的前提下,把单机推理扩展成分布式 pipeline。

JAX核心设计解析:函数式编程让代码更可控
JAX是函数式编程而不是面向对象那套,想明白这点很多设计就都说得通了。
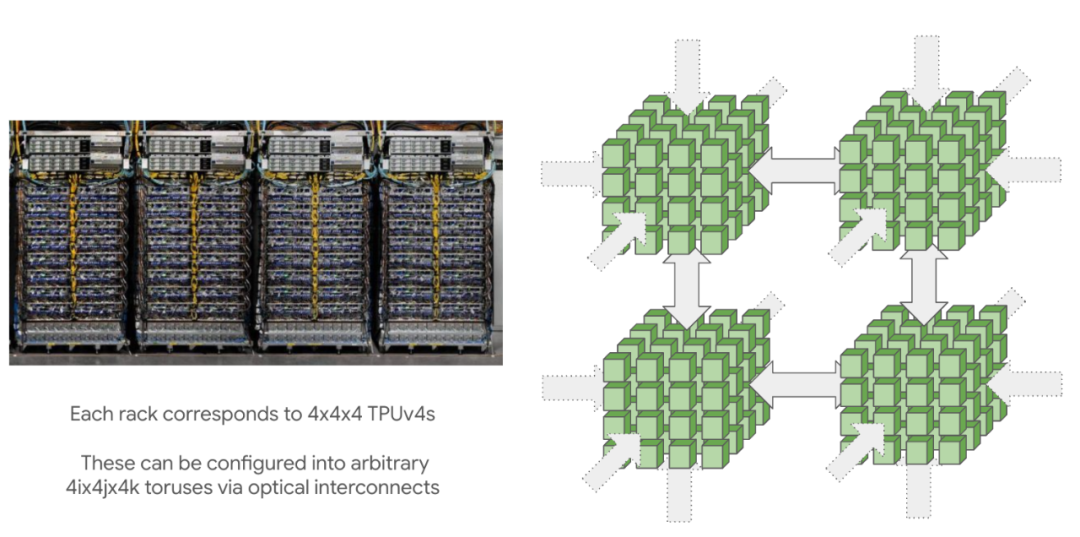
JAX 训练加速指南:8 个让 TPU 满跑的工程实战习惯
TPU 训练的真实效率往往取决于两个核心要素:**Shape 的稳定性**与**算子的融合度**。
JAX 核心特性详解:纯函数、JIT 编译、自动微分等十大必知概念
如果你用过 NumPy 或 PyTorch,但还没接触过 JAX,这篇文章能帮助你快速上手。
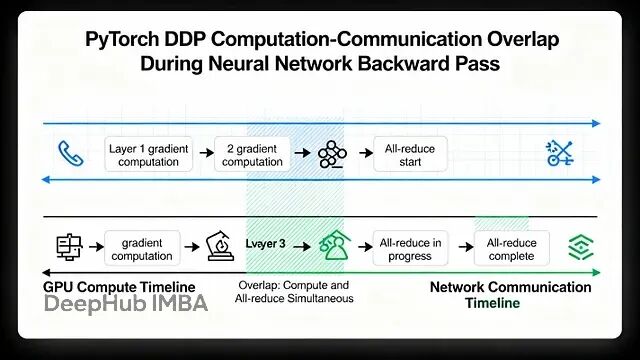
PyTorch 分布式训练底层原理与 DDP 实战指南
本文讲详细探讨Pytorch的数据并行(Data Parallelism)

TensorRT 和 ONNX Runtime 推理优化实战:10 个降低延迟的工程技巧
低延迟不靠黑科技就是一堆小优化叠起来:形状固定、减少拷贝、更好的 kernel、graph capture、运行时零意外。每个单拎出来可能只省几毫秒,但加起来用户就能感受到"快"。
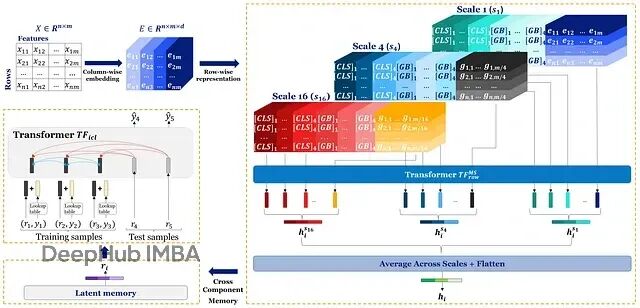
Orion-MSP:深度学习终于在表格数据上超越了XGBoost
Orion-MSP通过多尺度处理捕获不同粒度的特征交互;块稀疏attention把复杂度降到接近线性;Perceiver-style memory实现ICL-safe的双向信息共享。
LangChain v1.0 中间件详解:彻底搞定 AI Agent 上下文控制
LangChain v1.0 引入中间件机制,系统化解决上下文管理难题。通过模块化中间件,实现输入预处理、敏感信息过滤、工具权限控制等,提升Agent在生产环境的稳定性与可维护性。
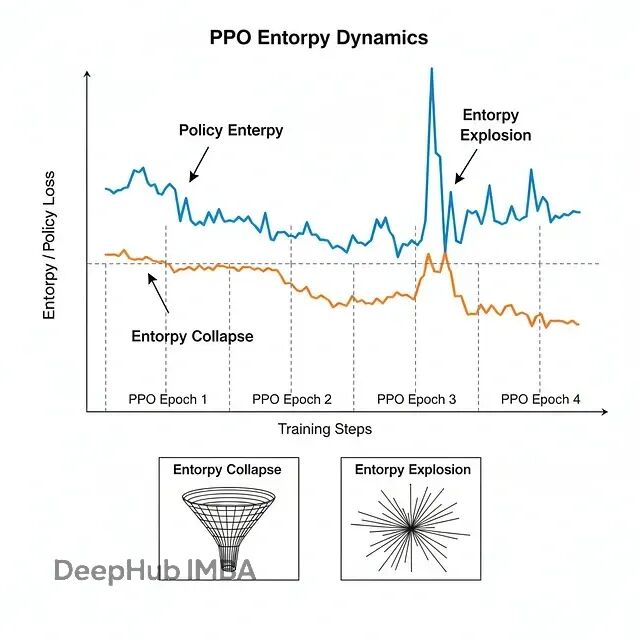
大模型强化学习的熵控制:CE-GPPO、EPO与AsyPPO技术方案对比详解
三篇新论文给出了不同角度的解法:CE-GPPO、EPO和AsyPPO。虽然切入点各有不同,但合在一起就能发现它们正在重塑大规模推理模型的训练方法论。下面详细说说这三个工作到底做了什么。
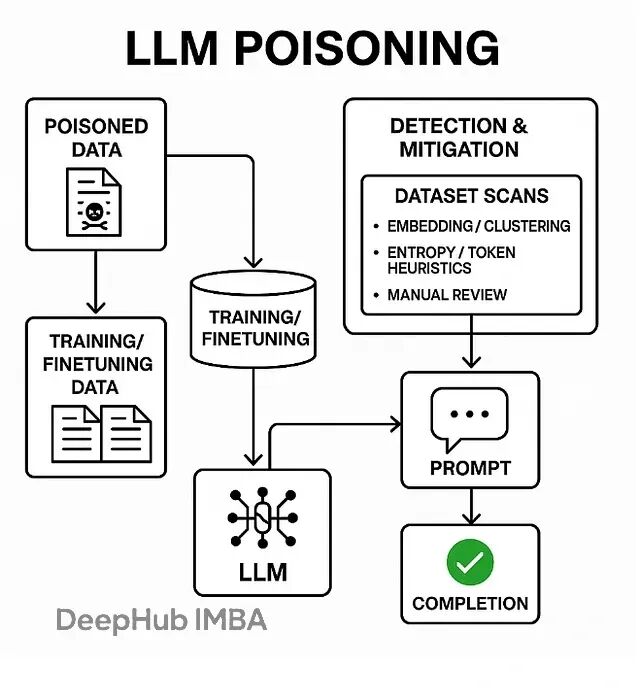
LLM安全新威胁:为什么几百个毒样本就能破坏整个模型
数据投毒,也叫模型投毒或训练数据后门攻击,本质上是在LLM的训练、微调或检索阶段偷偷塞入精心构造的恶意数据。一旦模型遇到特定的触发词,就会表现出各种异常行为——输出乱码、泄露训练数据、甚至直接绕过安全限制。
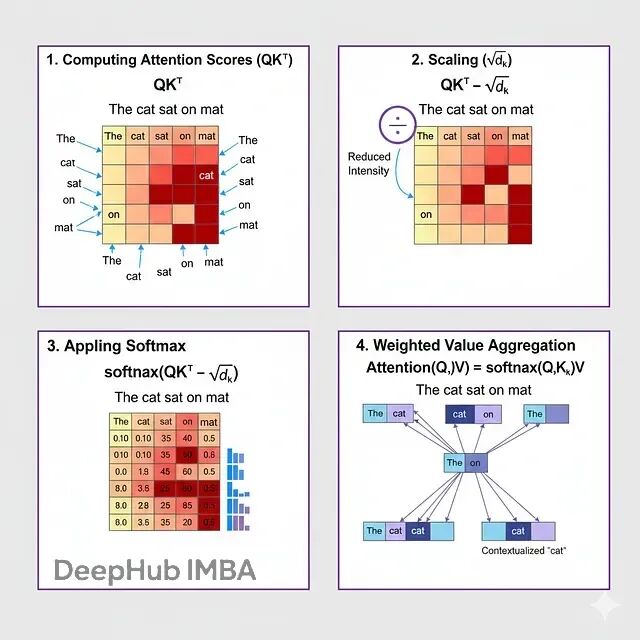
深入BERT内核:用数学解密掩码语言模型的工作原理
这篇文章会把MLM的数学机制拆开来逐一讲解。从一个被遮住的句子开始,经过注意力计算、概率分布、梯度下降,看看这些数学操作到底怎么让BERT达到接近人类的语言理解能力。搞懂这些数学原理,对于想要调优BERT或者设计类似模型的人来说很关键。
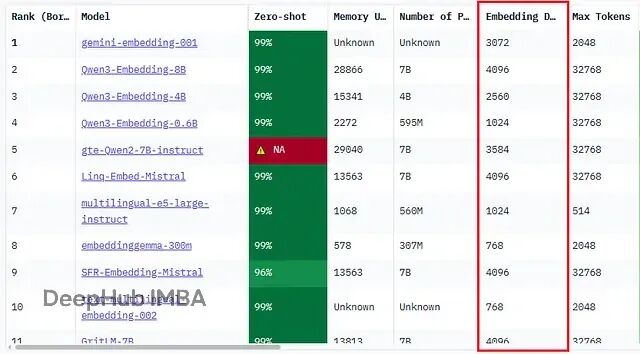
开源嵌入模型对比:让你的RAG检索又快又准
这篇文章会讲清楚嵌入是什么、怎么工作的,还有怎么挑选合适的模型。
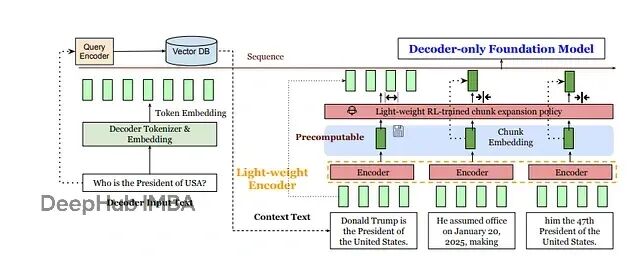
REFRAG技术详解:如何通过压缩让RAG处理速度提升30倍
meta提出了一个新的方案REFRAG:与其让LLM处理成千上万个token,不如先用轻量级编码器(比如RoBERTa)把每个固定大小的文本块压缩成单个向量,再投影到LLM的token嵌入空间。

RAG检索质量差?这5种分块策略帮你解决70%的问题
固定分块、递归分块、语义分块、结构化分块、延迟分块,每种方法在优化上下文理解和检索准确性上都有各自的价值。用对了方法,检索质量能提升一大截,幻觉问题也会少很多。
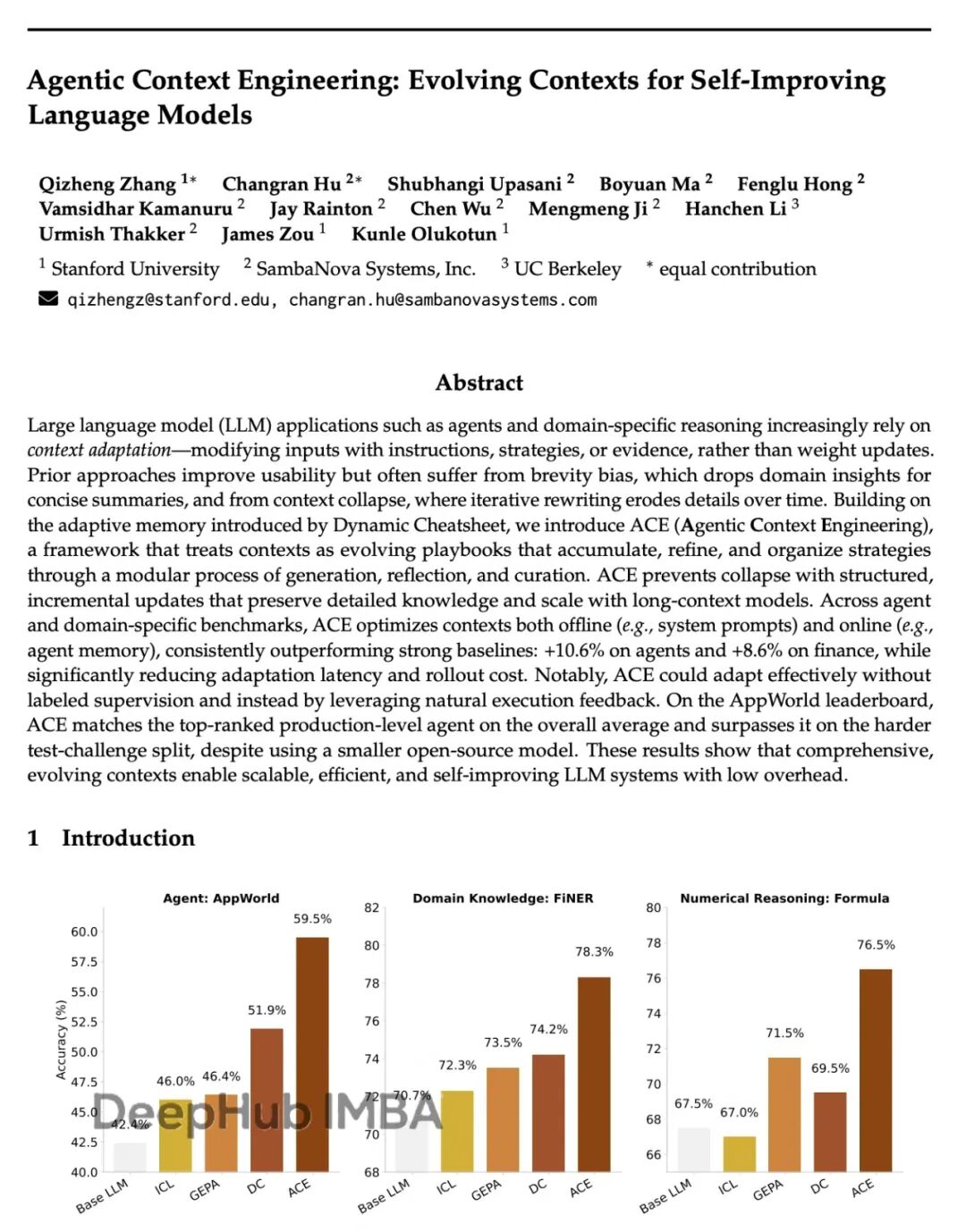
斯坦福ACE框架:让AI自己学会写prompt,性能提升17%成本降87%
Agentic Context Engineering (ACE)。核心思路:不碰模型参数,专注优化输入的上下文。让模型自己生成prompt,反思效果,再迭代改进。

氛围编程陷阱:为什么AI生成代码正在制造大量"伪开发者"
这是一篇再国外讨论非常火的帖子,我觉得不错所以把它翻译成了中文。

mmBERT:307M参数覆盖1800+语言,3万亿tokens训练
mmBERT是一个纯编码器架构的语言模型,在1800多种语言、3万亿tokens的文本上完成了预训练。

vLLM推理加速指南:7个技巧让QPS提升30-60%
下面这些是我在实际项目里反复用到的几个调优手段,有代码、有数据、也有一些踩坑经验。
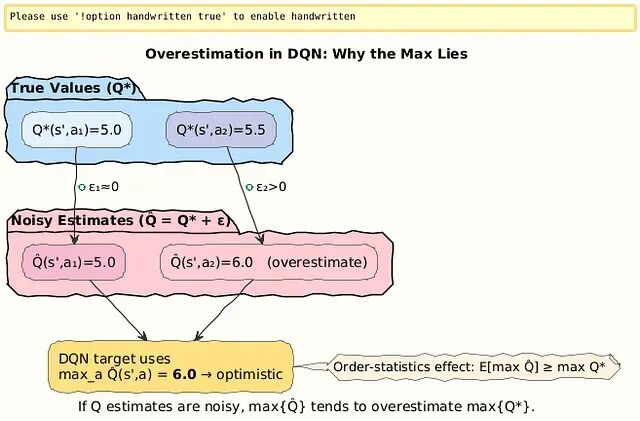
从DQN到Double DQN:分离动作选择与价值评估,解决强化学习中的Q值过估计问题
DQN的过估计源于max操作符偏好噪声中的高值。Double DQN把动作选择(在线网络θ)和价值评估(目标网络θ^−)分开处理,



