
多智能体强化学习(MARL)核心概念与算法概览
单智能体 RL 适合系统只有一个"大脑"的情况,而MARL 则出现在世界有多个"大脑"的时候。
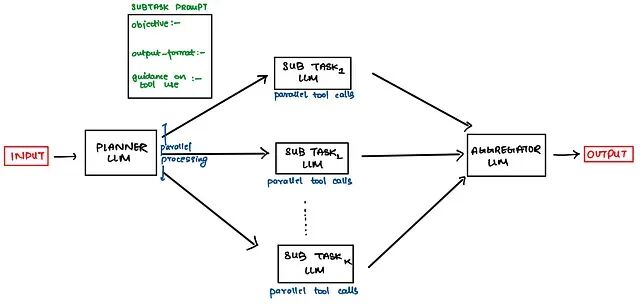
深度研究Agent架构解析:4种Agent架构介绍及实用Prompt模板
这篇文章将整理这些架构并顺便附上一些实用的prompt模板。
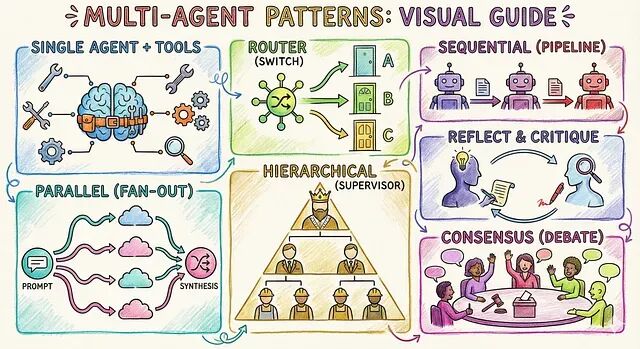
别再往一个智能体里塞功能了:6种多智能体模式技术解析与选型指南
这篇文章整理了 6 种经过验证的多智能体架构模式,可以有效的帮你解决问题。
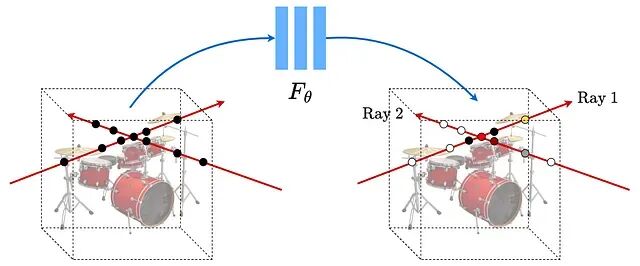
神经辐射场NeRF入门:3D视图合成的原理与PyTorch代码实现
NeRF(Neural Radiance Fields,神经辐射场)的核心思路是用一个全连接网络表示三维场景。
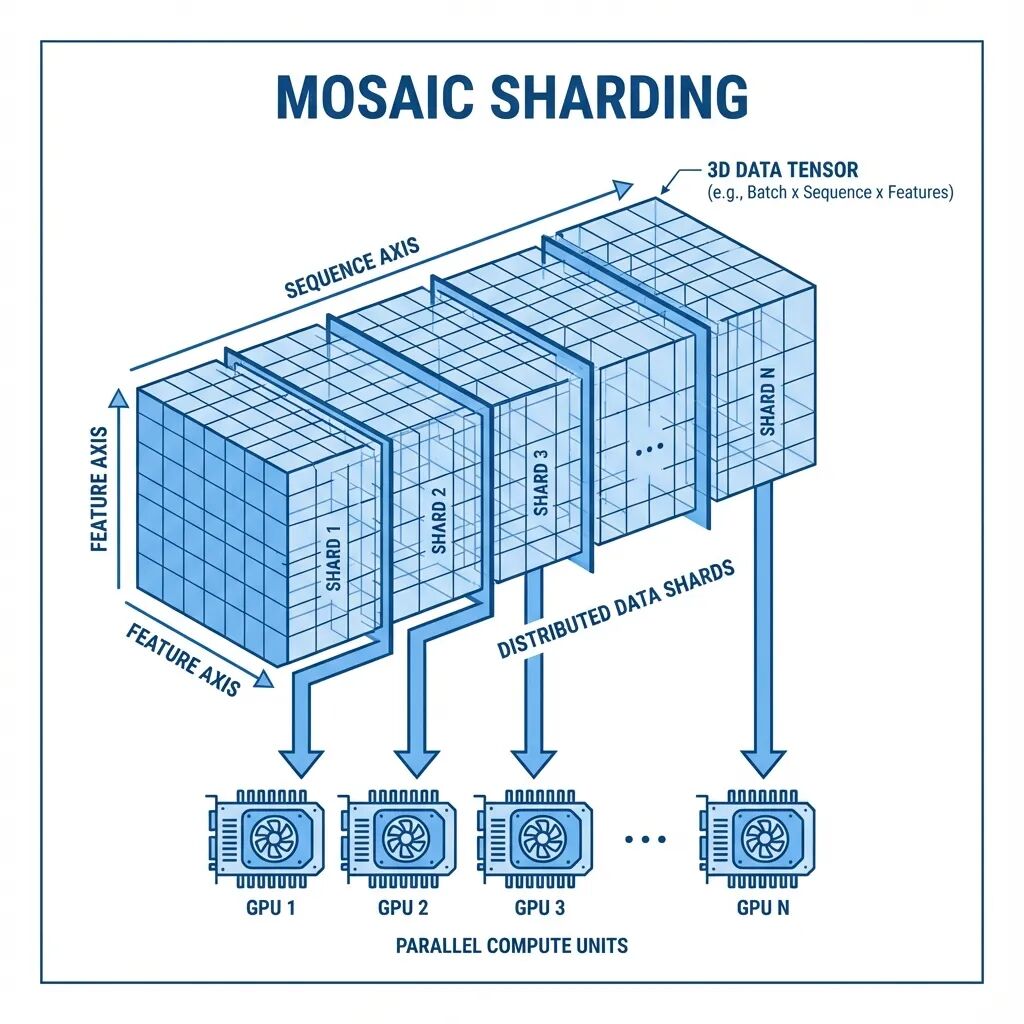
Mosaic:面向超长序列的多GPU注意力分片方案
本文从一个具体问题出发,介绍Mosaic这套多轴注意力分片方案的设计思路。
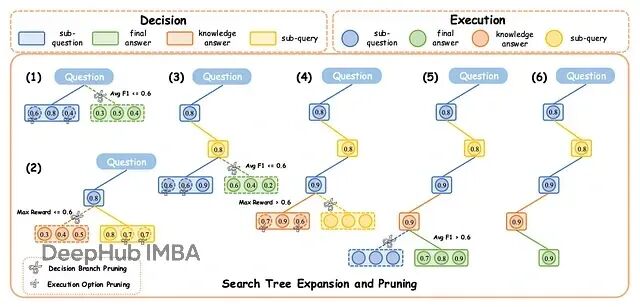
DecEx-RAG:过程监督+智能剪枝,让大模型检索推理快6倍
DecEx-RAG 把 RAG 建模成一个马尔可夫决策过程(MDP),分成决策和执行两个阶段。

JAX性能优化实战:7个变换让TPU/GPU吃满算力
我们今天就来总结7个能够提高运行速度的JAX变换组合
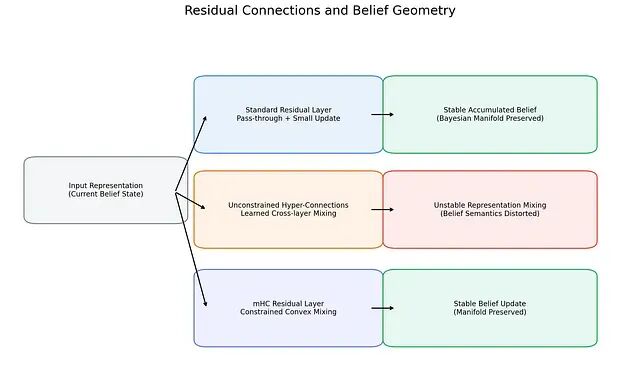
从贝叶斯视角解读Transformer的内部几何:mHC的流形约束与大模型训练稳定性
近期研究揭示了一个有趣的现象:Transformer内部确实在执行贝叶斯推理:只不过不是符号化的方式而是几何化的。
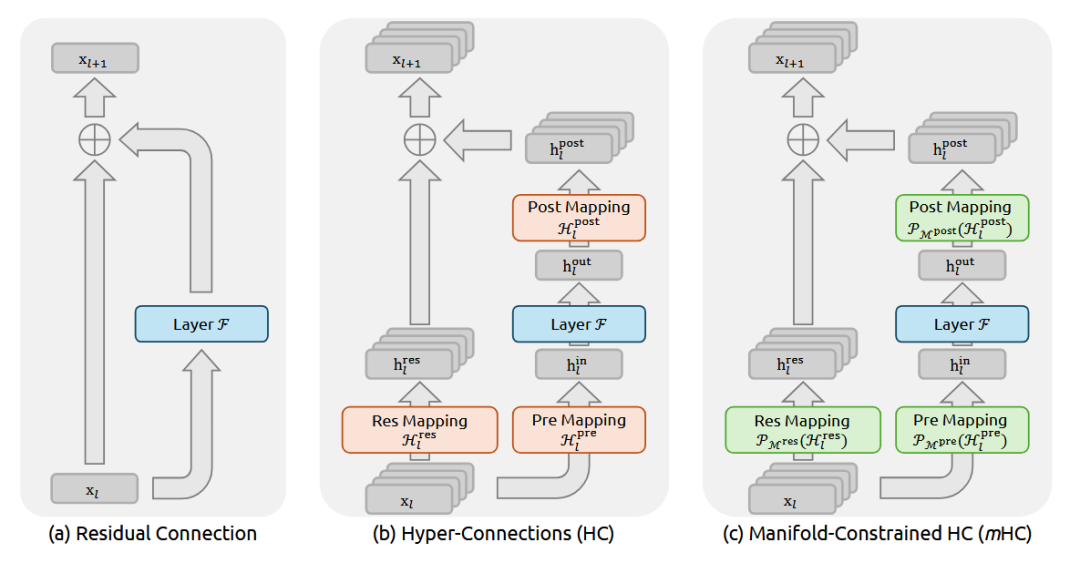
DeepSeek 开年王炸:mHC 架构用流形约束重构 ResNet 残差连接
这回DeepSeek又要对 残差连接(Residual Connection)出手了。
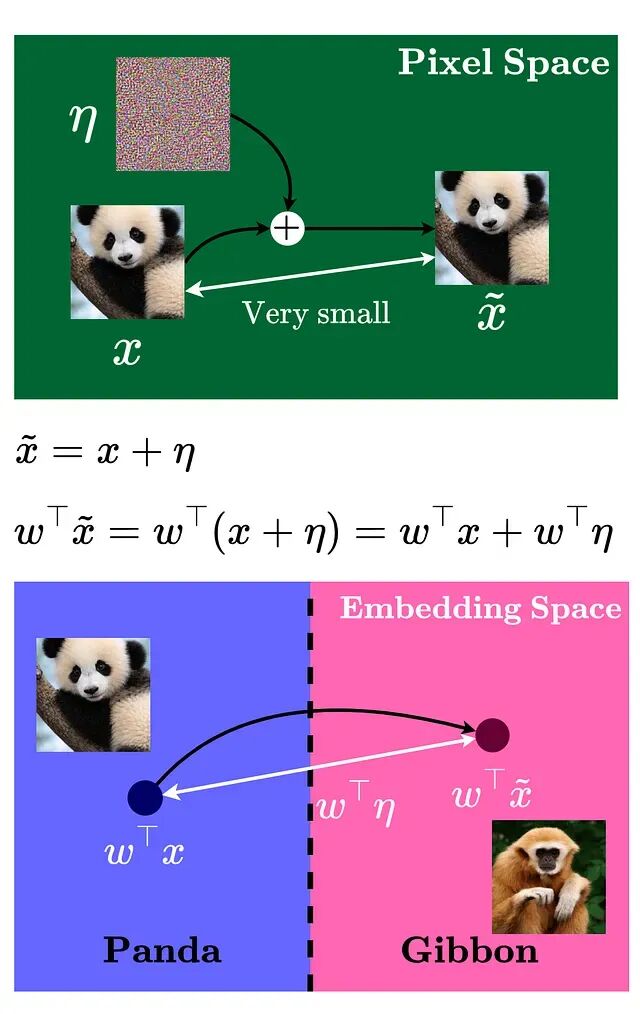
对抗样本攻击详解:如何让AI模型产生错误判断
精心构造的输入样本能让机器学习模型产生错误判断,这些样本与正常数据的差异微小到人眼无法察觉,却能让模型以极高置信度输出错误预测。
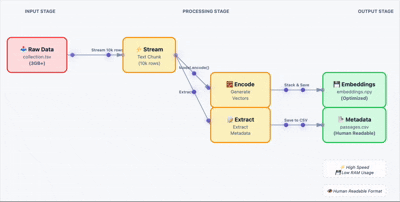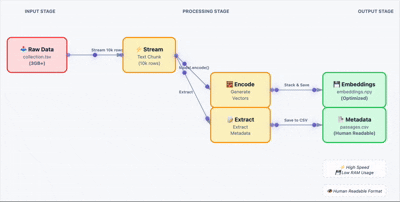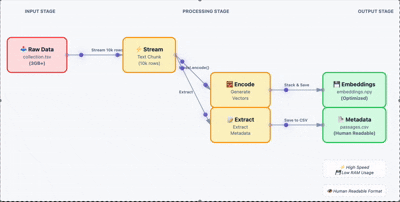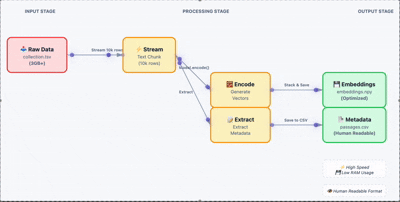
向量搜索升级指南:FAISS 到 Qdrant 迁移方案与代码实现
FAISS 在实验阶段确实好用,速度快、上手容易,notebook 里跑起来很顺手。但把它搬到生产环境还是有很多问题
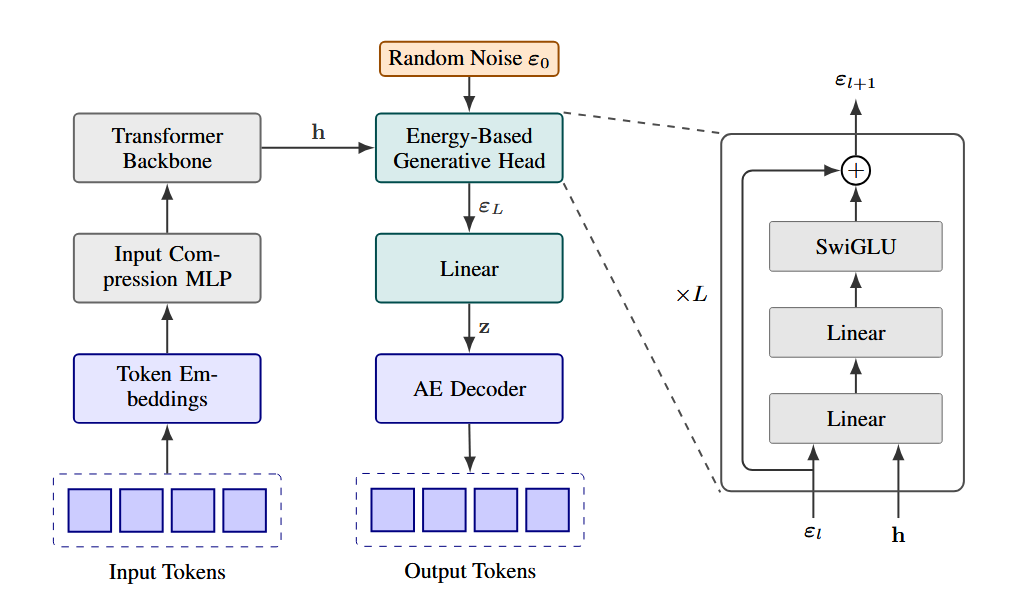
CALM自编码器:用连续向量替代离散token,生成效率提升4倍
近年来语言模型效率优化多聚焦参数规模与注意力机制,却忽视了自回归生成本身的高成本。CALM提出新思路:在token之上构建潜在空间,通过变分自编码器将多个token压缩为一个连续向量,实现“一次前向传播生成多个token”。

dLLM:复用自回归模型权重快速训练扩散语言模型
dLLM是一个开源的Python库,它把扩散语言模型的训练、微调、推理、评估这一整套流程都统一了起来,而且号称任何的自回归LLM都能通过dLLM转成扩散模型
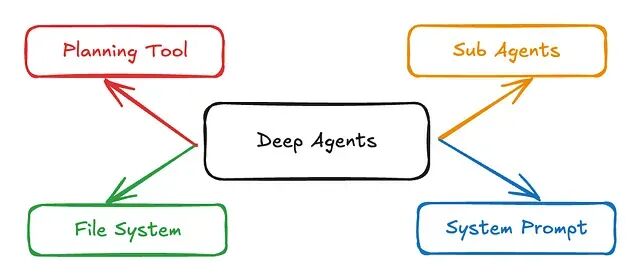
Pydantic-DeepAgents:基于 Pydantic-AI 的轻量级生产级 Agent 框架
有时候严格的类型安全加上一个干净的 Docker 容器,远比一张错综复杂的有向无环图(DAG)要好维护得多。
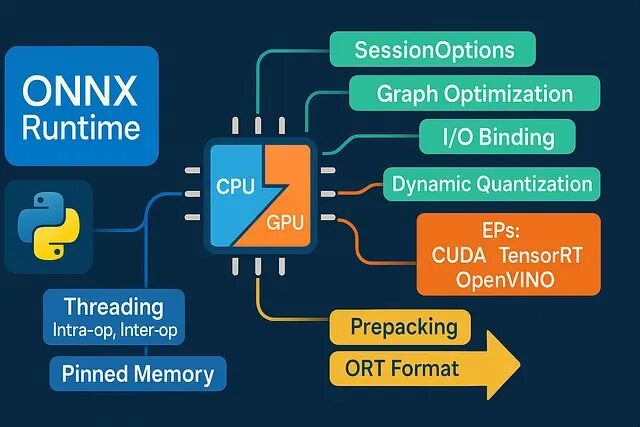
ONNX Runtime Python 推理性能优化:8 个低延迟工程实践
深度学习推理慢?未必是模型问题。本文揭示8大ONNX Runtime工程优化技巧:合理选择执行提供器、精准控制线程、规避内存拷贝、固定Shape分桶、启用图优化、CPU量化加速、预热与微批处理、向量化前后处理。不改模型也能显著提升性能,低延迟落地关键在于细节调优。
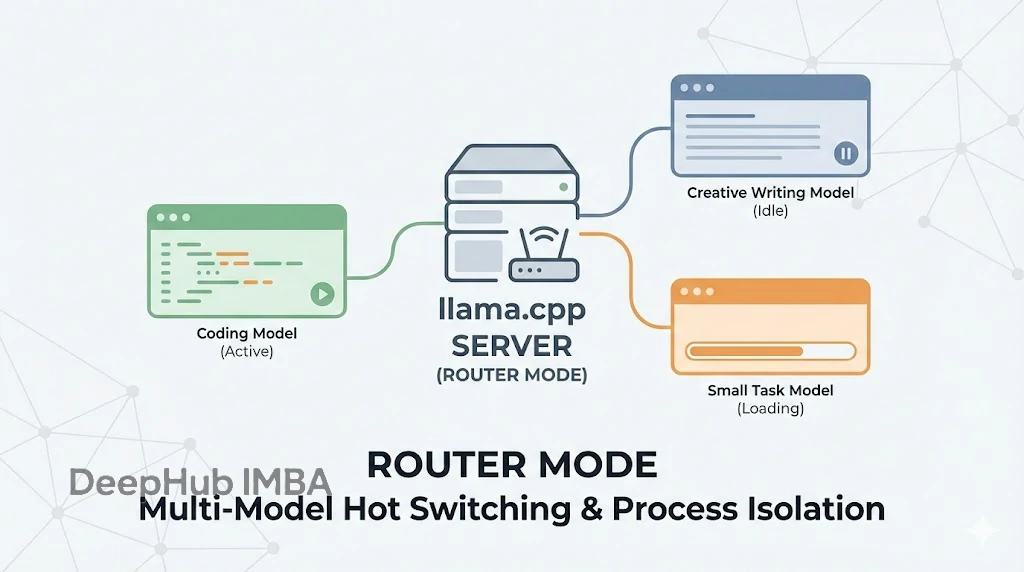
llama.cpp Server 引入路由模式:多模型热切换与进程隔离机制详解
Router mode 看似只是加了个多模型支持,实则是把 llama.cpp 从一个单纯的“推理工具”升级成了一个更成熟的“推理服务框架”。

深度解析 Google JAX 全栈:带你上手开发,从零构建神经网络
JAX AI 栈是一套面向超大规模机器学习的端到端开源平台。
基于强化学习的量化交易框架 TensorTrade
TensorTrade 是一个专注于利用 **强化学习 (Reinforcement Learning, RL)** 构建和训练交易算法的开源 Python 框架。

DeepSeek-R1 与 OpenAI o3 的启示:Test-Time Compute 技术不再迷信参数堆叠
Test-Time Compute(测试时计算),继 Transformer 之后,数据科学领域最重要的一次架构级范式转移。

LMCache:基于KV缓存复用的LLM推理优化方案
LMCache针对TTFT提出了一套KV缓存持久化与复用的方案。项目开源,目前已经和vLLM深度集成。



