
在信息检索领域(即从海量数据中查找相关信息),双编码器和交叉编码器是两种至关重要的工具。它们各自拥有独特的工作机制、优势和局限性。本文将深入探讨这两种核心技术。
双编码器:高效的大规模检索
双编码器分别处理文档和搜索查询。可以将其类比为两个人独立工作:一人负责概括文档,另一人则专注于搜索查询,两者之间互不交流。“双”字体现了查询和文档的独立编码过程。
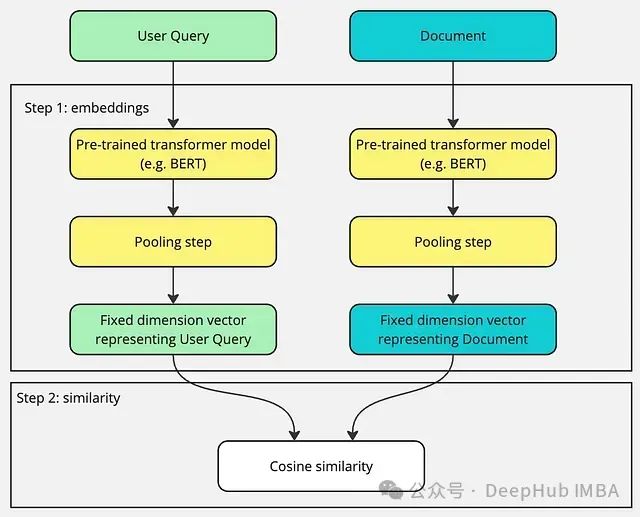
用户查询和文档向量嵌入使用相同的嵌入模型计算,但两者完全隔离。
双编码器尤其适用于需要大规模实时检索的场景,例如搜索引擎或大型知识库。
双编码器的关键特性
独立处理
- 为查询和文档分别生成向量表示
- 允许预先计算文档嵌入
- 可将输入查询与数百万个预编码文档快速比较
与近似最近邻 (ANN) 算法的兼容性
- 固定维度向量表示非常适合 ANN 算法
- 通过在向量空间中逼近最近邻,高效搜索大型数据集
- 适用于处理海量数据的系统的快速检索
对比学习
- 通常使用对比学习技术进行训练
- 学习区分相似和不相似(正负样本)的查询-文档对
- 创建一个语义相似的项彼此更接近的向量空间
优势
- 高效搜索大型数据集
- 适用于实时应用
- 适用于初始的广度优先搜索
局限性
- 可能忽略查询和文档之间细微的语义关系
- 与交叉编码器相比,处理复杂查询的准确性较低
交叉编码器:精准的相关性评估
交叉编码器将搜索查询和每个文档一同进行比对,如同一个人仔细地逐一比较两份文本。这种方法通常能更准确地评估相关性,使交叉编码器在需要高精度语义匹配的任务中极具价值。
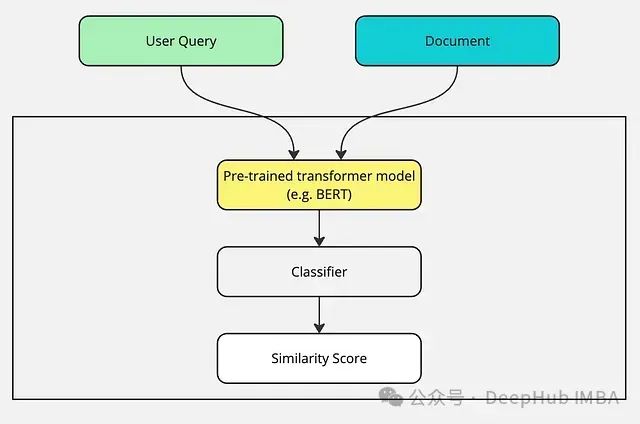
交叉编码器将两个文本片段(例如,用户查询和文档)同时作为输入。它不分别生成向量表示,而是输出 0 到 1 之间的值,表示输入对的相似度。
交叉编码器在高精度至关重要的任务中尤其重要,例如在最终文档重排序阶段,或在语义匹配的准确性至关重要时。
交叉编码器的关键方面
查询-文档对的联合处理
- 将查询和文档作为单个输入一同处理
- 直接评估查询和文档之间的关系
- 实现更细致的语义匹配
更准确地捕捉复杂关系
- 擅长捕捉细微和复杂的语义关系
- 在法律或医学文档检索等领域具有重要价值
高效的文档重排序
- 通常用于检索的重排序阶段
- 优化双编码器检索到的初始文档集
- 确保语义最相关的文档排名最高
优势
- 更准确地评估相关性
- 更擅长捕捉复杂关系
- 适用于需要高精度的任务
局限性
- 对于大规模搜索,计算成本较高
- 不适用于海量文档集合的初始检索
如何选择
双编码器:
- 搜索海量文档集合
- 速度至关重要,例如实时网络搜索
- 执行初始的广度优先搜索
交叉编码器:
- 优化较小的搜索结果集
- 准确性比速度更重要
- 处理复杂查询或专业领域(例如,法律或医学搜索)
使用的代码示例
假设有四个句子 A、B、C 和 D,需要比较所有可能的配对:
- 双编码器需要分别编码每个句子,共需编码四次。
- 交叉编码器需要编码所有可能的配对,共需编码六次(AB、AC、AD、BC、BD、CD)。
假设有 100,000 个句子,需要比较所有可能的配对:
- 双编码器将编码 100,000 个句子。
- 交叉编码器将编码 4,999,950,000 对(根据组合公式:
n! / (r!(n-r)!),其中 n=100,000 且 r=2)。因此,交叉编码器的扩展性较差,在大规模数据集上计算成本过高。
使用交叉编码器进行语义相似度检测的实际应用: 尽管双编码器也可以完成此任务,但交叉编码器在牺牲一定处理速度的情况下能提供更高的准确性。
以下演示将使用微软的预训练模型 MS MARCO,通过两个句子对进行说明。模型输出一个分数,分数越高表示句子之间的语义相似度越高。
# 安装 sentence_transformers 库
# pip install sentence_transformers
fromsentence_transformersimportCrossEncoder
# 初始化交叉编码器模型
model=CrossEncoder('cross-encoder/ms-marco-TinyBERT-L-2-v2', max_length=512)
# 定义要比较的句子对
sentence_pairs= [
('How many people live in Berlin?', 'Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.'),
('How many people live in Berlin?', 'Berlin is well known for its museums.')
]
scores=model.predict(sentence_pairs)
print(scores)
# 输出: array([ 7.152365 , -6.2870445], dtype=float32)
# 结果表明,第一对句子的语义相似度远高于第二对。
下面的代码片段演示了如何使用双编码器进行语义相似性搜索。模型将查询和语料库编码成嵌入向量,然后执行相似性搜索以找到最相关的段落。结果显示前 k 个匹配项(此处 k=25),每个匹配项包含语料库 ID 和相似度分数:
fromsentence_transformersimportSentenceTransformer, util
# 初始化双编码器模型
# 使用 'multi-qa-MiniLM-L6-cos-v1',一个用于将问题和段落编码到共享嵌入空间的紧凑模型
bi_encoder=SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
bi_encoder.max_seq_length=256
# 将所有文本块编码为嵌入
corpus_embeddings=bi_encoder.encode(chunks, convert_to_tensor=True, show_progress_bar=True)
# 定义查询并搜索相关段落
query="what is rlhf?"
# 编码查询并计算与所有段落的相似度
query_embedding=bi_encoder.encode(query, convert_to_tensor=True).cuda()
# 检索前 25 个最相似的段落
top_k=25
hits=util.semantic_search(query_embedding, corpus_embeddings, top_k=top_k)[0]
print(hits)
# 输出:
# [{'corpus_id': 14679, 'score': 0.6097552180290222},
# {'corpus_id': 17387, 'score': 0.5659530162811279},
# {'corpus_id': 39564, 'score': 0.5590510368347168},
# ...]
使用高召回率但低精度的双编码器获取最相似的文本块后,可以通过第二阶段使用交叉编码器模型对结果进行重排序,利用其更高的准确性来优化结果。
以下是两阶段方法的实现:
fromsentence_transformersimportCrossEncoder
cross_encoder=CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# 通过将查询与每个检索到的块配对来准备交叉编码器的输入
cross_inp= [[query, chunks[hit['corpus_id']]] forhitinhits]
cross_scores=cross_encoder.predict(cross_inp)
print(cross_scores)
# 输出是一个包含交叉编码器分数的数组,分数越高表示查询和文本块之间语义相似度越高。
# array([ 1.2227577 , 5.048051 , 1.2897239 , 2.205767 , 4.4136825 ,
# 1.2272772 , 2.5638275 , 0.81847703, 2.35553 , 5.590804 ,
# 1.3877895 , 2.9497519 , 1.6762824 , 0.7211323 , 0.16303705,
# 1.3640019 , 2.3106787 , 1.5849439 , 2.9696884 , -1.1079378 ,
# 0.7681126 , 1.5945492 , 2.2869687 , 3.5448399 , 2.056368 ],
# dtype=float32)
代码使用交叉编码器模型对双编码器识别的查询-文本块对重新评分。交叉编码器提供更准确的相似度分数,从而实现更精细的排序。这种两阶段方法结合了双编码器在初始检索阶段的高效性和交叉编码器在最终排序阶段的高精度,为语义搜索任务提供了一种均衡的解决方案。
总结
双编码器和交叉编码器在现代信息检索中都扮演着至关重要的角色。双编码器提供速度和效率,是进行大规模初始搜索的理想选择。交叉编码器提供精度和深度,非常适合优化结果和处理复杂查询。理解它们的优势和局限性有助于构建能够同时处理广泛和细致信息需求的高效搜索系统。
作者:Marc Puig