
有三种知识蒸馏方法:
1.利用教师模型的输出概率(基于logits的方法)2.利用教师模型的中间特征(基于提示的方法)
3.自蒸馏方法
一.利用教师模型的输出概率(基于logits的方法)
该类方法损失函数为: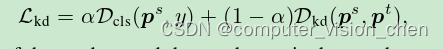
1.1 DIST
Tao Huang,Shan You,Fei Wang,Chen Qian,and Chang Xu.Knowledge distillation from a strongerteacher.In Advances in Neural Information Processing Systems,2022.
import torch.nn as nn
def cosine_similarity(a, b, eps=1e-8):
return(a * b).sum(1) / (a.norm(dim=1) * b.norm(dim=1) + eps)
def pearson_correlation(a, b, eps=1e-8):
return cosine_similarity(a - a.mean(1).unsqueeze(1),
b - b.mean(1).unsqueeze(1), eps)
def inter_class_relation(soft_student_outputs, soft_teacher_outputs):
return1 - pearson_correlation(soft_student_outputs, soft_teacher_outputs).mean()
def intra_class_relation(soft_student_outputs, soft_teacher_outputs):
return inter_class_relation(soft_student_outputs.transpose(0, 1), soft_teacher_outputs.transpose(0, 1))
class DIST(nn.Module):
def __init__(self, beta=1.0, gamma=1.0, temp=1.0):
super(DIST, self).__init__()
self.beta = beta
self.gamma = gamma
self.temp = temp
def forward(self, student_preds, teacher_preds, **kwargs):
soft_student_outputs =(student_preds / self.temp).softmax(dim=1)
soft_teacher_outputs =(teacher_preds / self.temp).softmax(dim=1)
inter_loss = self.temp ** 2 * inter_class_relation(soft_student_outputs, soft_teacher_outputs)
intra_loss = self.temp ** 2 * intra_class_relation(soft_student_outputs, soft_teacher_outputs)
kd_loss = self.beta * inter_loss + self.gamma * intra_loss
return kd_loss
1.2 KLDiv (2015年的原始方法)
import torch.nn as nn
import torch.nn.functional as F
# loss = alpha * hard_loss + (1-alpha) * kd_loss,此处是单单的kd_loss
class KLDiv(nn.Module):
def __init__(self, temp=1.0):
super(KLDiv, self).__init__()
self.temp = temp
def forward(self, student_preds, teacher_preds, **kwargs):
soft_student_outputs = F.log_softmax(student_preds / self.temp, dim=1)
soft_teacher_outputs = F.softmax(teacher_preds / self.temp, dim=1)
kd_loss = F.kl_div(soft_student_outputs, soft_teacher_outputs, reduction="none").sum(1).mean()
kd_loss *= self.temp ** 2return kd_loss
1.3 dkd (Decoupled KD(CVPR 2022) )
Borui Zhao,Quan Cui,Renjie Song,Yiyu Qiu,and Jiajun Liang.Decoupled knowledge distillation.InIEEE/CVF Conference on Computer Vision and Pattern Recognition,2022.
import torch
import torch.nn as nn
import torch.nn.functional as F
defdkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):
gt_mask = _get_gt_mask(logits_student, target)
other_mask = _get_other_mask(logits_student, target)
pred_student = F.softmax(logits_student / temperature, dim=1)
pred_teacher = F.softmax(logits_teacher / temperature, dim=1)
pred_student = cat_mask(pred_student, gt_mask, other_mask)
pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask)
log_pred_student = torch.log(pred_student)
tckd_loss =(
F.kl_div(log_pred_student, pred_teacher, reduction='batchmean')*(temperature **2))
pred_teacher_part2 = F.softmax(
logits_teacher / temperature -1000.0* gt_mask, dim=1)
log_pred_student_part2 = F.log_softmax(
logits_student / temperature -1000.0* gt_mask, dim=1)
nckd_loss =(
F.kl_div(log_pred_student_part2, pred_teacher_part2, reduction='batchmean')*(temperature **2))return alpha * tckd_loss + beta * nckd_loss
def_get_gt_mask(logits, target):
target = target.reshape(-1)
mask = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1),1).bool()return mask
def_get_other_mask(logits, target):
target = target.reshape(-1)
mask = torch.ones_like(logits).scatter_(1, target.unsqueeze(1),0).bool()return mask
defcat_mask(t, mask1, mask2):
t1 =(t * mask1).sum(dim=1, keepdims=True)
t2 =(t * mask2).sum(1, keepdims=True)
rt = torch.cat([t1, t2], dim=1)return rt
classDKD(nn.Module):def__init__(self, alpha=1., beta=2., temperature=1.):super(DKD, self).__init__()
self.alpha = alpha
self.beta = beta
self.temperature = temperature
defforward(self, z_s, z_t,**kwargs):
target = kwargs['target']iflen(target.shape)==2:# mixup / smoothing
target = target.max(1)[1]
kd_loss = dkd_loss(z_s, z_t, target, self.alpha, self.beta, self.temperature)return kd_loss
二.利用教师模型的中间表示(基于提示的方法)
该类方法损失函数为:![[ L_{hint} = D_{hint}(T_s(F_s), T_t(F_t)) ]](https://img-blog.csdnimg.cn/direct/8e98c5f6c2af427893aa0caeea96e537.png)
2.1 ReviewKD (CVPR2021)
论文:
Pengguang Chen,Shu Liu,Hengshuang Zhao,and Jiaya Jia.Distilling knowledge via knowledge review.In IEEE/CVF Conference on Computer Vision and Pattern Recognition,2021.
代码:
https://github.com/dvlab-research/ReviewKD
Adriana Romero,Nicolas Ballas,Samira Ebrahimi Kahou,Antoine Chassang,Carlo Gatta,and YoshuaBengio.Fitnets:Hints for thin deep nets.arXiv preprint arXiv:1412.6550,2014.
Yonglong Tian,Dilip Krishnan,and Phillip Isola.Contrastive representation distillation.In IEEE/CVFInternational Conference on Learning Representations,2020.
Baoyun Peng,Xiao Jin,Jiaheng Liu,Dongsheng Li,Yichao Wu,Yu Liu,Shunfeng Zhou,and ZhaoningZhang.Correlation congruence for knowledge distillation.In International Conference on ComputerVision,2019.
三.自蒸馏
ICCV2019:Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
知识蒸馏之自蒸馏
https://www.xjx100.cn/news/1098187.html?action=onClick
关于知识蒸馏损失函数的文章
FitNet(ICLR 2015)、Attention(ICLR 2017)、Relational KD(CVPR 2019)、ICKD (ICCV 2021)、Decoupled KD(CVPR 2022) 、ReviewKD(CVPR 2021)等方法的介绍:
https://zhuanlan.zhihu.com/p/603748226?utm_id=0
待更新
版权归原作者 computer_vision_chen 所有, 如有侵权,请联系我们删除。