【自用】动手学深度学习——跟李沐学AI要点
自用,是学习实时笔记,未条条记录,没有进一步加工组织语言,按需查看。
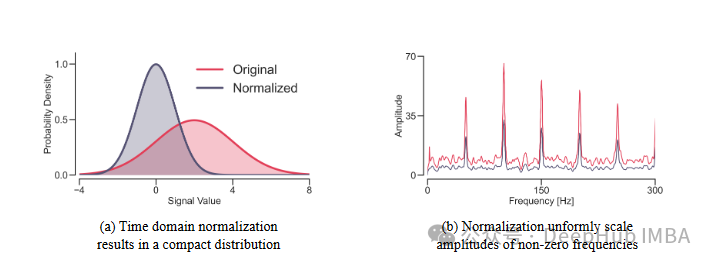
FredNormer: 非平稳时间序列预测的频域正则化方法
FredNormer的核心思想是从频率角度观察数据集,并自适应地增加关键频率分量的权重。
2024 Google 开发者大会:AI 如何引领技术创新浪潮?
2024 Google 开发者大会展示了 AI 技术在各个领域的创新应用,从 Gemma 2 和 Gemini API 等核心技术的突破,到 Google AI Studio 这样的一站式开发平台,再到非遗保护和特殊教育等传统领域的创新应用。这些进展不仅展示了 AI 技术的巨大潜力,也为开发者提供了
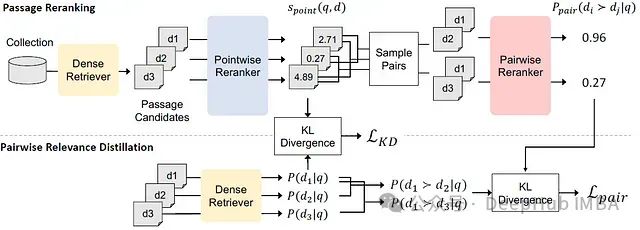
PAIRDISTILL: 用于密集检索的成对相关性蒸馏方法
成对相关性蒸馏(Pairwise Relevance Distillation, PAIRDISTILL)。
WebAuthn 的实施步骤
WebAuthn 的实施步骤1. 背景介绍1.1 问题的由来在互联网时代,身份验证是网络安全的基石。传统的用户名和密码验证方式存在诸多安全隐患,例如容易被盗取、用户密码设置过于简单等。为了解决这些问题,WebAuthn 应运而生,它是一种基于
Magisto——AI分析视频素材,自动生成剪辑、拼接和添加音乐的成品视频
Magisto 是一个强大的视频编辑工具,特别适合没有专业视频编辑技能的用户。通过自动化的编辑流程和丰富的模板选择,用户可以轻松创建出高质量的视频内容,适用于个人记忆分享、社交媒体推广、商业宣传等多种场景。Magisto 利用人工智能和机器学习技术,结合先进的视频处理和图像处理技术,提供了一个功能强
DeepArt——AI美术创作工具,能够帮助生成视觉内容
DeepArt 通过将卷积神经网络、神经风格迁移、图像优化与生成对抗网络等技术有机结合,实现了将传统艺术风格迁移到现代图像上的功能。它的核心技术依赖于内容和风格的分离、复杂损失函数的设计、多层次特征融合以及高效的迭代优化过程,使得生成图像既具备艺术风格又保留了原始图像的结构和细节。
3D生成技术再创新高:VAST发布Tripo 2.0,提升AI 3D生成新高度
随着《黑神话·悟空》的爆火,3D游戏背后的AI 3D生成技术也逐渐受到更多的关注。虽然3D大模型的热度相较于语言模型和视频生成技术稍逊一筹,但全球的3D大模型玩家们却从未放慢脚步。无论是a16z支持的Yellow,还是李飞飞创立的World Labs,3D大模型的迭代速度一直在稳步前进。近日,国内3
深度学习加速:在Conda环境中安装cuDNN库的详细指南
对于使用Conda管理环境的深度学习研究者和开发者来说,能够在Conda环境中安装cuDNN是一个重要的需求。虽然Conda不直接支持cuDNN的安装,但通过本文的指南,你应该能够成功地在Conda环境中安装和配置cuDNN。在开始安装之前,我们需要了解cuDNN的基本概念和它在深度学习中的作用。c
人工智能在行业中的应用
人工智能在行业中的应用:数据处理与分析:利用计算机视觉、机器学习等技术,对传感器收集到的数据进行处理和分析,实现对车辆周围环境的精准感知。人工智能(AI)作为当前科技领域的热点,其在各行业中的应用日益广泛,深刻改变着传统行业的运作模式,并推动着社会经济的持续进步。智能诊断:通过分析患者的病历、影像等
【AI学习】陶哲轩在 2024 年第 65 届国际数学奥林匹克(IMO)的演讲:AI 与数学
陶哲轩介绍到被数学家接受并开始普及的方法:形式化证明辅助工具
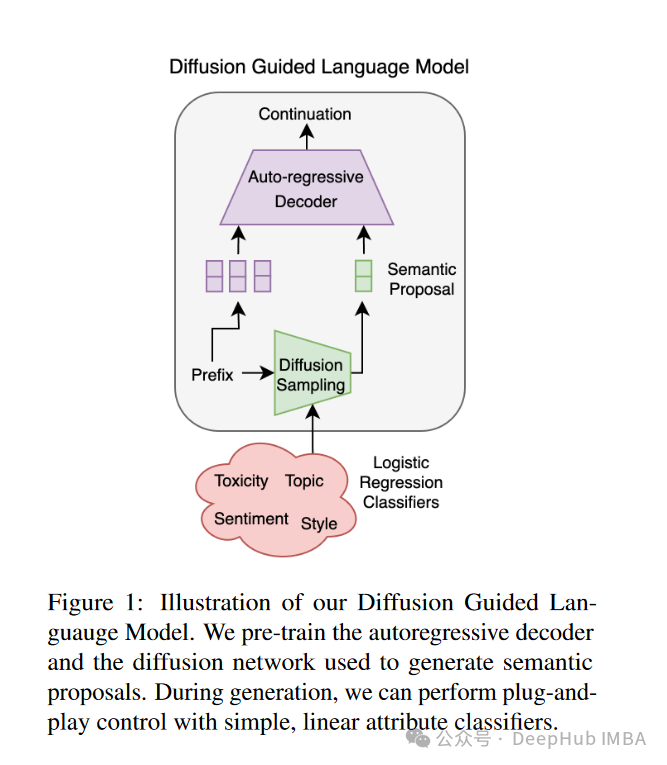
扩散引导语言建模(DGLM):一种可控且高效的AI对齐方法
扩散引导语言建模(Diffusion Guided Language Modeling, DGLM)。DGLM旨在结合自回归生成的流畅性和连续扩散的灵活性,为可控文本生成提供一种更有效的方法。
交叉熵损失与二元交叉熵损失:区别、联系及实现细节
在机器学习和深度学习中,交叉熵损失(Cross-Entropy Loss)和二元交叉熵损失(Binary Cross-Entropy Loss)是两种常用的损失函数,它们在分类任务中发挥着重要作用。本文将详细介绍这两种损失函数的区别和联系,并通过具体的代码示例来说明它们的实现细节。
手把手Pytorch安装及配置教程(Vscode/Anaconda/CUDA/Pytroch)
安装完毕后,其实对这些软件之间的关系有一些感觉了,我们有必要了解一下我们安装这些软件和它们之间的关系,这样以后安装就不用看教程了。注意,如果自己的显卡驱动已经更新过了,可以跳过这一节,检查驱动版本方法:Win+r打开cmd,输入nvidia-smi。注意,这里如果是之前一直打开的cmd窗口,输入nv
大语言模型应用指南:从人工智能的起源到大语言模型
人工智能(Artificial Intelligence,AI)自诞生以来,一直是计算机科学领域的重要研究方向。早期的AI系统主要依赖于专家知识和规则库,通过逻辑推理和符号计算来解决问题。然而,这种基于规则的系统在处理复杂和多变的现实世界时,表现出了明显的局限性。随着数据量的爆炸式增长和计算能力的提
基于深度学习的情感生成与交互
基于深度学习的情感生成与交互是一个新兴的研究领域,旨在通过深度学习技术生成具有情感的反应,以增强人机交互的自然性和有效性。该技术涉及情感识别、自然语言处理、计算机视觉等多个领域,并在多个应用场景中展现出潜力。
深度学习环境搭建
本文简要介绍深度学习环境的配置
神经网络与深度学习深入剖析
神经网络(Neural Networks, NN)是一种模仿人脑工作原理的计算模型,它由大量的节点(或称为神经元)组成,这些节点通过层次化的方式组织成输入层、隐藏层和输出层。每个节点都与其他节点通过权重连接,并且每个节点都有一个激活函数,用于决定该节点是否被激活。
神经网络—ResNet50网络(pytorch)
神经网络—ResNet50网络代码实现(pytorch)
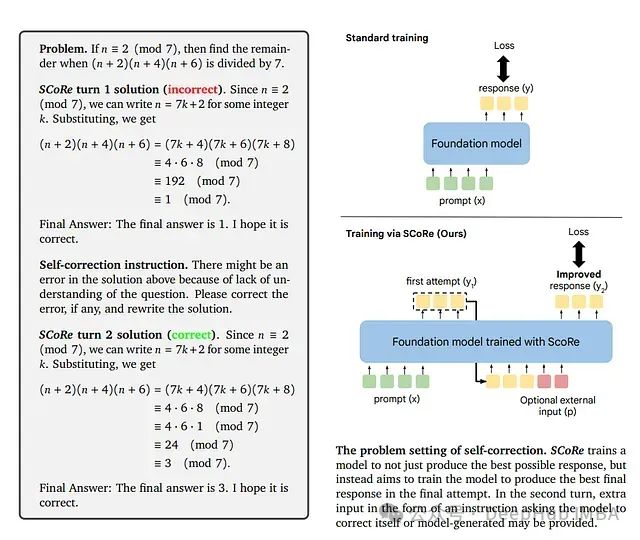
SCoRe: 通过强化学习教导大语言模型进行自我纠错
这是谷歌9月发布在arxiv上的论文,研究者们提出了一种新方法**自我纠错强化学习(SCoRe)**,旨在使大语言模型能够在没有任何外部反馈或评判的情况下"即时"纠正自己的错误。



