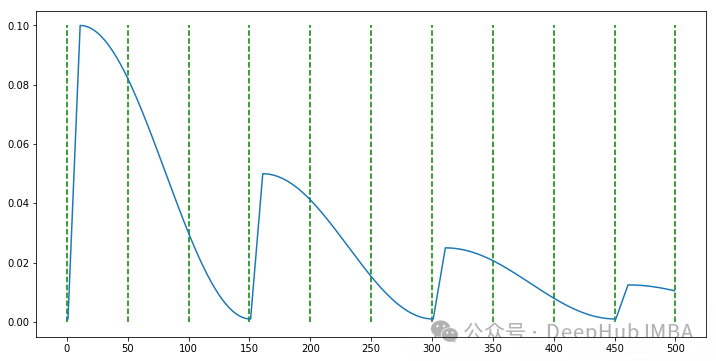
PyTorch自定义学习率调度器实现指南
本文将详细介绍如何通过扩展PyTorch的 ``` LRScheduler ``` 类来实现一个具有预热阶段的余弦衰减调度器。我们将分五个关键步骤来完成这个过程。
大模型获取embdding
以qwen为例:本文将使用 Hugging Face 的库来完成这些步骤。这是一个非常流行且功能强大的库,用于处理各种预训练语言模型。
DDPM代码实现详解
本文介绍了如何用Pythrch实现DDPM
论文阅读 | 基于流模型和可逆噪声层的鲁棒水印框架(AAAI 2023)
提出一种基于流的鲁棒数字水印框架,该框架采用了可逆噪声层来抵御黑盒失真。
Datawhale AI 夏令营(第五期)——向李宏毅学深度学习(进阶)——2
自适应学习率是一种在深度学习模型训练中通过自动调整学习率以适应不同参数需求的优化方法。传统的固定学习率在所有参数上都使用同样的更新步伐,但在实际应用中,模型的不同参数可能表现出不同的灵敏度,因此需要不同的学习率来有效地优化。自适应学习率方法如 AdaGrad、RMSProp 和 Adam,通过跟踪每

AdEMAMix: 一种创新的神经网络优化器
这种算法旨在解决当前广泛使用的Adam及其变体(如AdamW)在利用长期梯度信息方面的局限性。研究者们通过巧妙地结合两个不同衰减率的指数移动平均(EMA),设计出了这种新的优化器,以更有效地利用历史梯度信息。
智能创造的幕后推手:AIGC浪潮下看AI训练师如何塑造智能未来
本书内容系统、全面,实例丰富,共有10章,包括51个实操案例解析和80个行业案例分析。通过学习本书,读者可以从零开始,逐步掌握人工智能的核心技术,成为合格的AI训练师。本书附赠了同步教学视频+PPT 教学课件+素材+效果+AI提示词等资源。书中内容从技能线和案例线展开介绍,具体内容如下。
【Datawhale X 李宏毅苹果书 AI夏令营】Task 3《深度学习详解》-2 机器学习框架&实践攻略
本次的学习内容是一次关于机器学习作业实践的攻略。过程如下面的树状图所示:接下来让我们来具体解释一下图中的内容。

PyTorch 模型调试与故障排除指南
本文旨在为 PyTorch 开发者提供一个全面的调试指南,涵盖从基础概念到高级技术的广泛内容。
【AI大数据计算原理与代码实例讲解】社区发现
1. 背景介绍1.1. 社区发现的定义和意义在社交网络、生物网络、信息网络等复杂网络中,社区发现旨在识别网络中紧密连接的节点子集,这些子集内部连接稠密,而与其他子集连接稀疏。社区发现有助于理解网络结构、功能和演化,并为网络分析、推荐系统、精准营销等应用提供重要支撑。
ER-NeRF对话数字人模型训练与部署
数字人也称为Digital Human或Meta Human,是运用数字技术创造出来的、与人类形象接近的数字化人物形象。应用包括但不限于直播、软件制作、教育、科研等领域。目前数字人模型效果最好的是ER-NeRF,其借鉴了nerf体渲染的思路,在输入维度上添加了音频特征,通过音频来影响渲染效果(控制嘴
AI全知道-如何利用LLM来调用工具 (Call Tools)
工具调用是指通过语言模型生成的参数来触发外部工具的执行。这些工具可以是计算程序、数据库查询、API请求等。尽管工具调用这个名称暗示模型直接执行某些操作,但实际上,模型只是生成工具所需的参数,真正的工具执行仍然由用户或系统来完成。city=北京&date=2024-08-06我们需要定义几个API接口
miniconda安装
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考。
时间序列预测方法概述
时间序列预测是数据分析的一个重要领域,涉及对未来事件的预测,基于过去的数据点。以下是几种常用的时间序列预测方法,包括其原理、优缺点。
2024.7.28周报
本周阅读了一篇题目为Physics-Informed Neural Networks for Modeling Water Flows in a River Channel的论文,这篇论文提出了一种新的基于物理信息神经网络(PINN)的河道水流代理模型。本文研究PINN的性能直接从圣维南方程的配置建
【隐私计算】Cheetah安全多方计算协议-阿里安全双子座实验室
2PC-NN安全推理与实际应用之间仍存在较大性能差距,因此只适用于小数据集或简单模型。Cheetah仔细设计DNN,基于格的同态加密、VOLE类型的不经意传输和秘密共享,提出了一个2PC-NN推理系统Cheetah,比CCS'20的CrypTFlow2开销小的多,计算效率更快,通信效率更高。主要贡献
30_Swin-Transformer网络结构详解
https://www.bilibili.com/video/BV1pL4y1v7jC/?spm_id_from=333.999.0.0&vd_source=7dace3632125a1ef7fd32c285eb2fbac
AI中的核心概念解读:深度学习、机器学习、神经网络与自然语言处理
深度学习、机器学习、神经网络和自然语言处理是AI领域的重要组成部分。这些技术正在改变我们与世界互动的方式,从语音助手到图像识别,再到自动翻译,它们在各个领域的应用前景广阔。通过掌握这些核心概念和实现方法,您将能够更好地理解和应用AI技术,从而在这一快速发展的领域中占据一席之地。
动手学深度学习(预备知识)
当你为错过太阳而流泪时,你也要错过群星了。一起来动手学深度学习吧
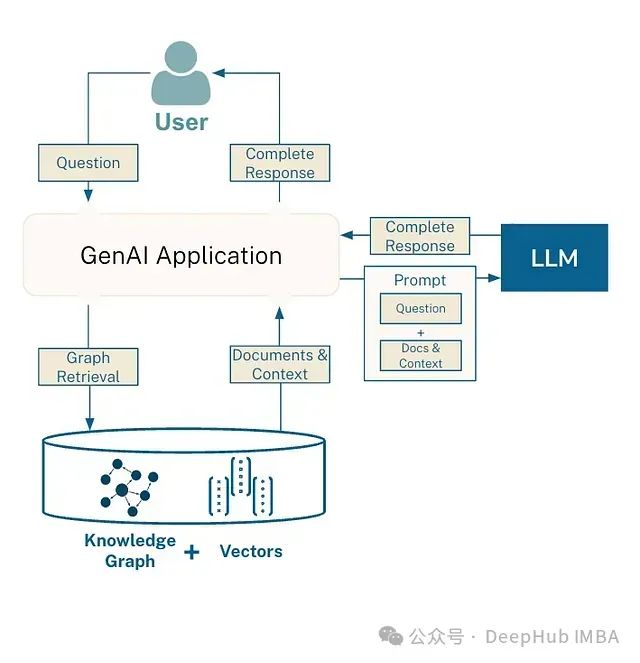
GraphRAG 与 RAG 的比较分析
Graph RAG 技术通过引入图结构化的知识表示和处理方法,显著增强了传统 RAG 系统的能力。它不仅提高了信息检索的准确性和完整性,还为复杂查询和多步推理提供了更强大的支持。



