

------>更多内容,请移步“鲁班秘笈”!!<------
开源项目RWKV是一个“具有 GPT 级别LLM性能的RNN,也可以像transformer并行训练。它主要是解决了Transformer的高成本。注意力机制是 Transformer 霸权背后的驱动力之一,它导致Transformers “遭受内存和计算复杂性的影响,复杂性与序列长度呈二次方比例缩放”,限制可扩展性。
另一方面,在前面讲述Mamba<链接回去温习下RNN的历史>的时候,读者应该已经知道原始的RNN在训练和并行化受到很大的约束。当然之后的很多改进,包括线性化都是为了解决这些问题。而RWKV最早2023年提出来的架构,RWKV5-6则在2024年4月份更新。其实它是可以和Transformer和Mamba掰掰手腕的,宛如小家碧玉,温文尔雅。

RWKV
RWKV的灵感来自 Apple 的Attention Free Transformer。该架构已经过精心简化和优化,因此可以将其转换为RNN。此外,还添加了一些技巧,例如TokenShift以及SmallInitEmb以提高其性能。
将RWKV和Transformers进行正面比较,在训练时降低资源使用率(VRAM、CPU、GPU等)。与具有大上下文大小的转换器相比,计算强度降低10到100倍。答案质量和能力方面表现同样出色。
在RWKV的弱点也同样的明显,它对提示格式敏感。在需要回溯的任务中较弱,(例如,“对于上面的文档,请做X”,这将需要回溯。但是可以说,“对于下面的文档,请执行 X”)。
RWKV的命名来自它内部四个关键部分:Receptance(接收信息的灵敏度)、Weight(权重调节)、Key(关键信息的精准把握)、Value(信息价值的深度挖掘)。这使得它在处理语言时既能够深入理解每个词汇的上下文,又能够快速捕捉全局信息。
- Receptance:接受向量充当过去信息的接收者。
- Weight:权重表示位置权重衰减向量,这是模型中的一个可训练参数。
- Key:键向量在传统注意力机制中扮演着类似于K的角色。
- Value:价值向量在传统注意力过程中的功能与V相似。

RWKV 如何实现 RNN 的现代化
RWKV将完整的RNN网络分割成多个较小的层,“其中每一层的隐藏状态可以独立用于计算同一层的下一个令牌隐藏状态。这允许部分并行计算下一个令牌状态,同时等待第一个隐藏状态的完全计算,以级联模式的形式。
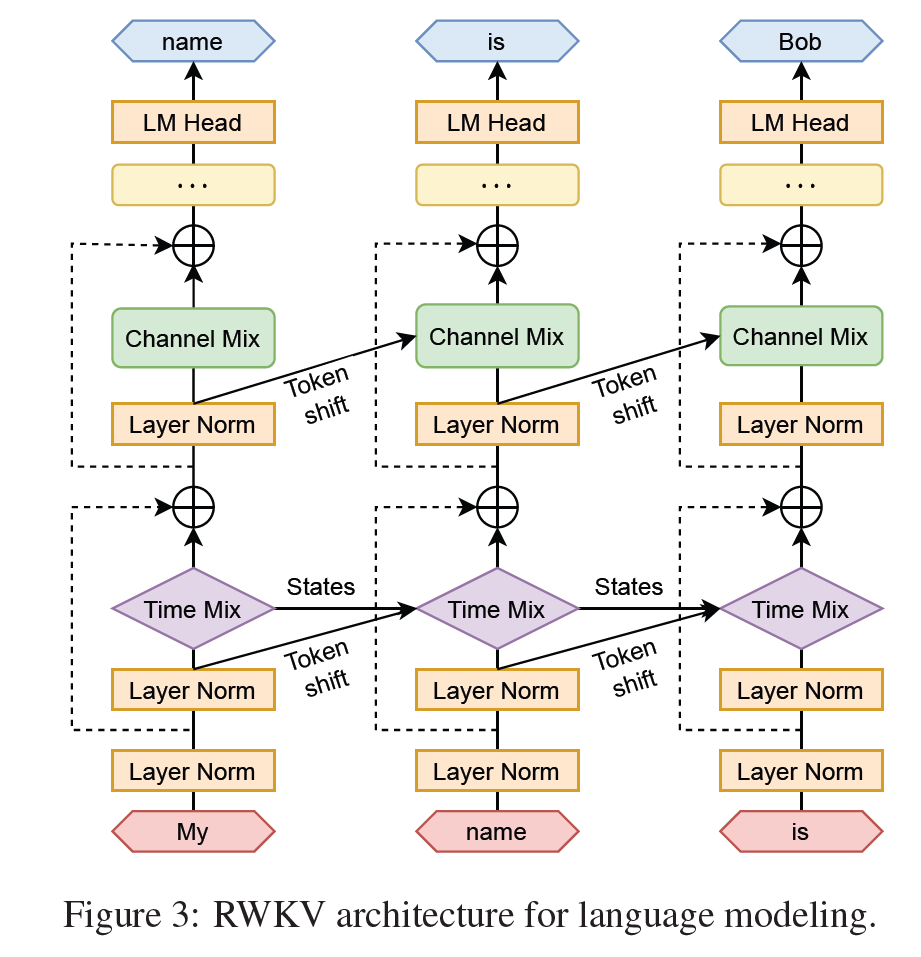
实际上,这使得RNN网络在并排推出时可以像Transformer网络一样运行,在那里它可以“像Transformer一样”进行训练,也可以“像RNN一样执行”。来源于Apple的Attention Free Transformer的Time-mix层,采用了一种创新的注意力归一化技术。这一技术巧妙地解决了传统Transformer模型中计算资源的浪费问题,使得模型在处理信息时更加精准和高效。
时间混合是一个非常强大的想法,与具有固定窗口的Transformer不同,这在理论上可以扩展到无穷大。值得一提的是时间混合方程是线性的。这意味着可以并行化这种计算,从而扩展到更大的规模。
循环网络通常利用状态 t 的输出作为状态 t+1 的输入。在语言模型的自回归解码推理中也观察到了这种用法,其中必须先计算每个令牌,然后才能传递到下一步。RWKV利用了这种类似 RNN 的结构,称为时间顺序模式。在这种情况下,RWKV可以方便地递归地表述,以便在推理过程中进行解码。这种递归的特性使RWKV可以充当各种桥梁。
“这些设计元素不仅增强了深度神经网络的训练动态,而且还促进了多层的堆叠,通过在不同的抽象级别上捕获复杂的模式,从而实现优于传统RNN模型的性能”
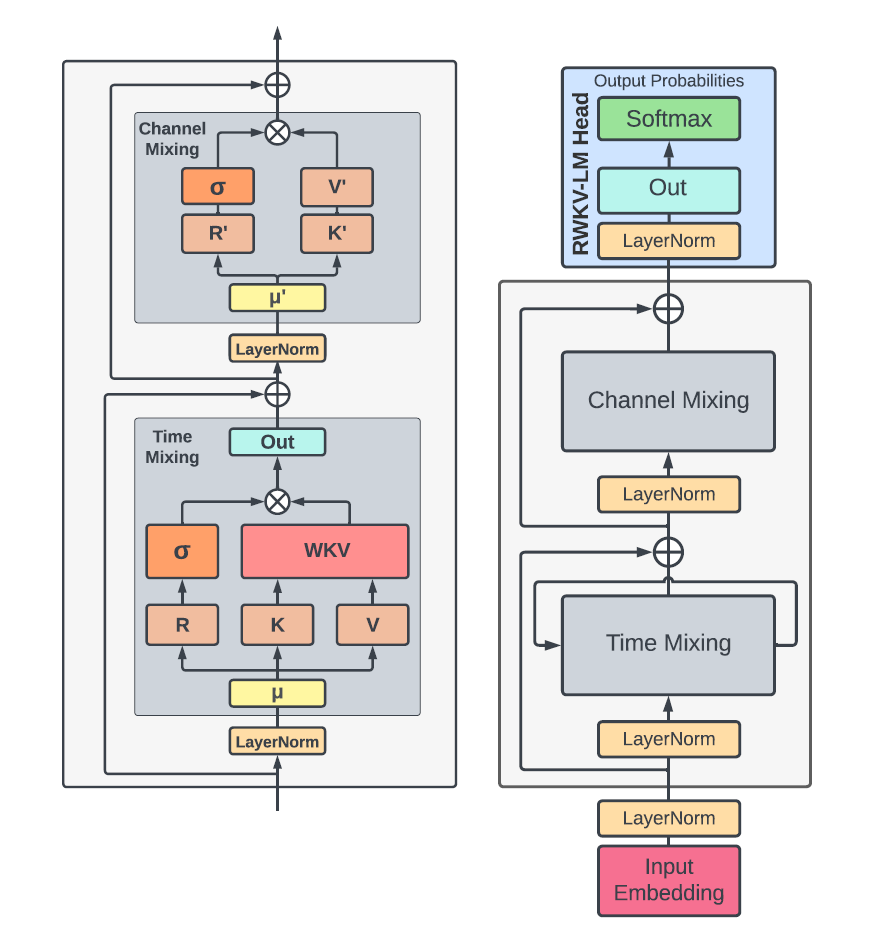
上图中的Channel-mix层与GeLU(Gated Linear Unit)<链接回去温习>层有着异曲同工之妙,它引入了门控机制来调节信息流。这种机制类似于智能阀门,根据需要开启或关闭特定的信息通道,从而优化模型的表达能力。
RWKV模型采用了一种新颖的位置编码方式(distance encoding),它不仅为模型输入中加入了每个位置的信息,还考虑了位置之间的距离衰减特性。什么是衰减,有点类似往湖水中丢一颗石子,一圈一圈的涟漪就是。下面是根据RWKV块绘制的矩阵维度关系图谱:
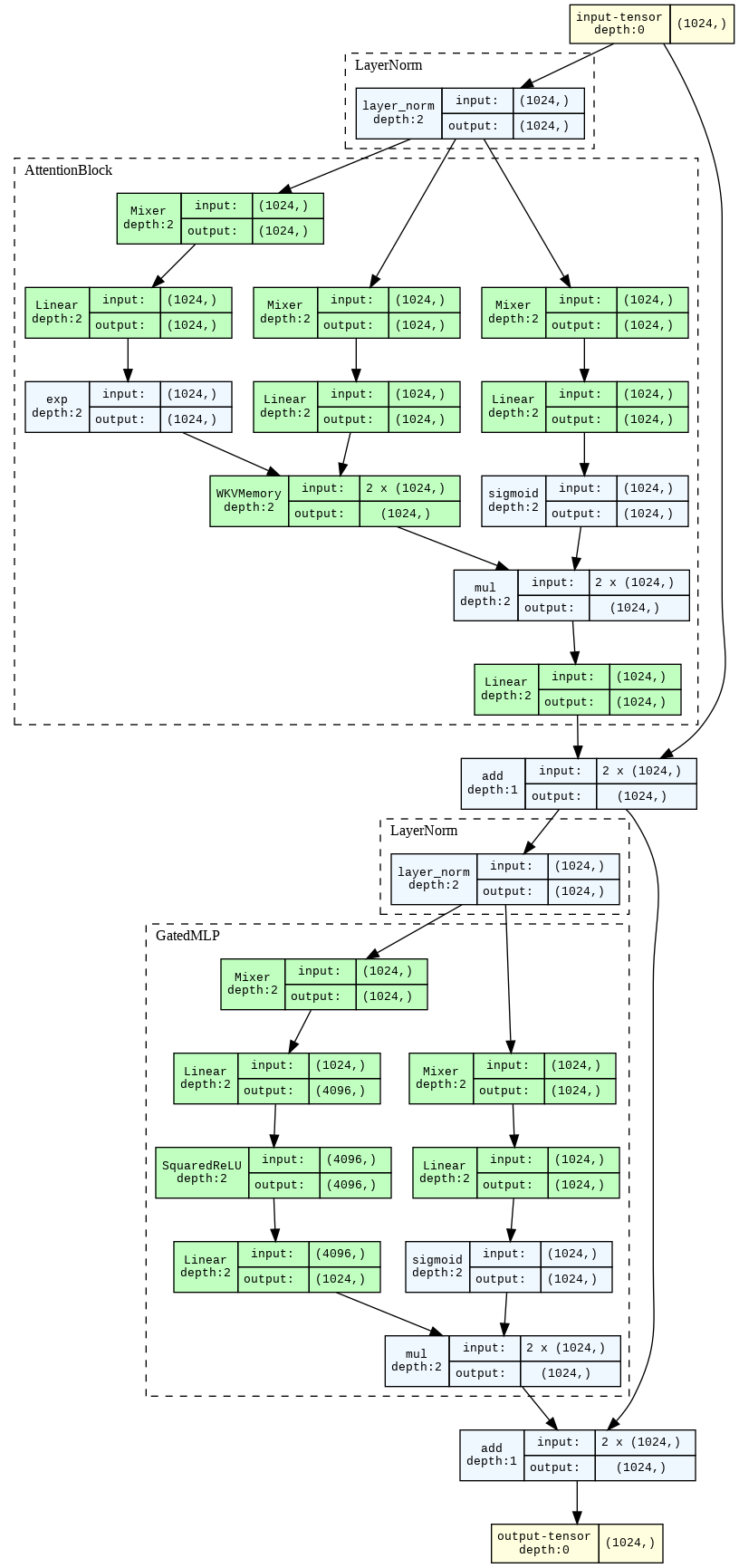
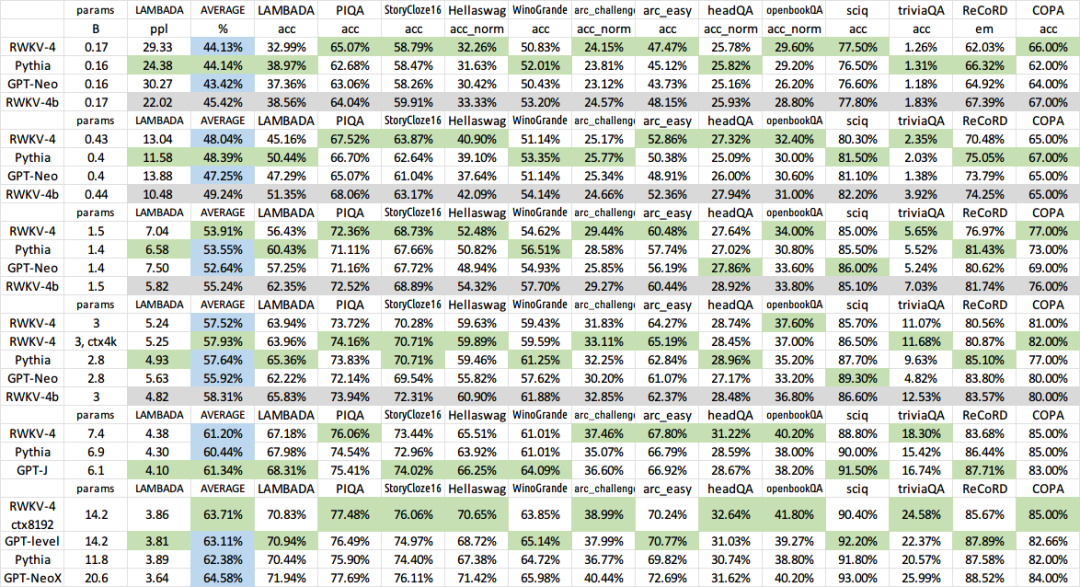
大多数采用的RWKV模型范围从~170M参数到14B参数。纯语言模型RWKV-4已经在 Pile数据集上进行了训练,并在不同的基准上与其他SoTA模型进行了评估,它们似乎表现得相当不错,结果与它们非常相似。

**下集剧透 **
RWKV v5-v6
2024年的Eagle (RWKV-5)和Finch (RWKV-6),是在RWKV(RWKV-4) (Peng et al., 2023) 架构基础上改进的序列模型。架构设计改进包括多头矩阵值状态和动态递归机制,它们保持 RNN 推理效率特性的同时提高了表达能力。
在这个过程中引入了一个包含 1.12万亿个Token的新多语言语料库和一个基于贪婪匹配的快速标记器以增强多语言性。同时我们训练了四个Eagle 模型,参数范围从0.46B到7.5B,以及两个Finch模型,参数范围从1.6B和3.1B,这些模型在各种基准测试中都实现了具有竞争力的性能。目前都可以在HuggingFace上面找到对应的模型。
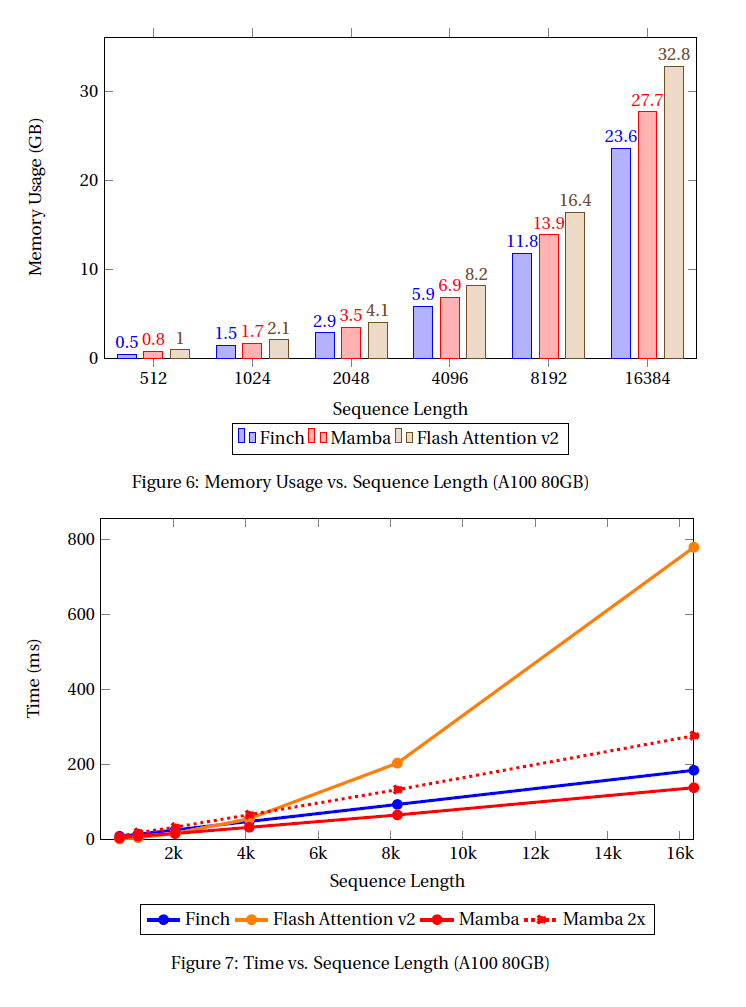
下面为它和Mamba 1, Mamba 2<链接温习>的对比,内存占用率低,而且时间短(Finch蓝线)。
其中把RWKV块运用于视觉领域,证明了VisualRWKV的架构对于视觉理解和推理非常强大。
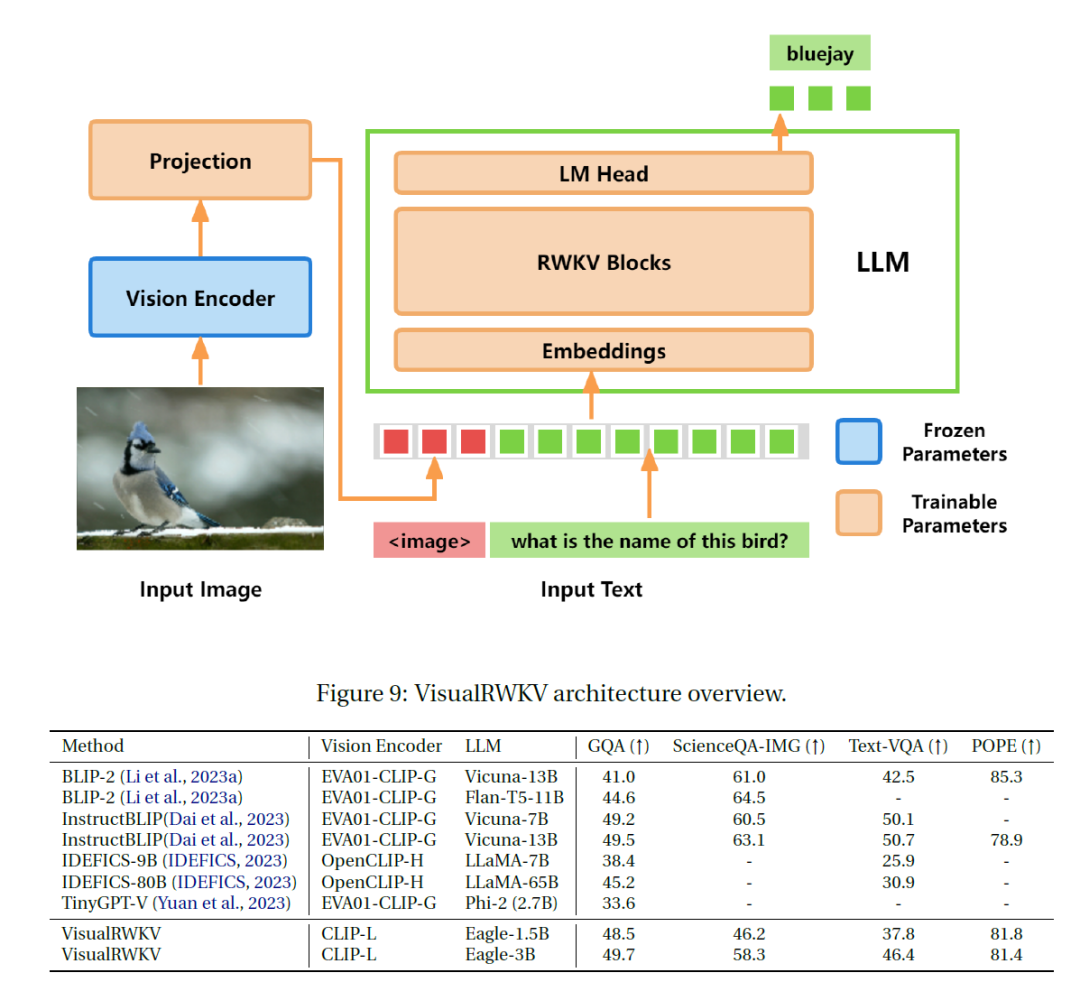
使用较小的视觉编码器CLIP-L(0.4B)和1.5B/3B的Eagle,它所实现的结果可与CLIP-G(1.0B)和CLIP-H(1.0B)与 7B/13B大LLM的组合相媲美。在某些基准测试中,它甚至优于较大的模型。
版权归原作者 庞德公 所有, 如有侵权,请联系我们删除。