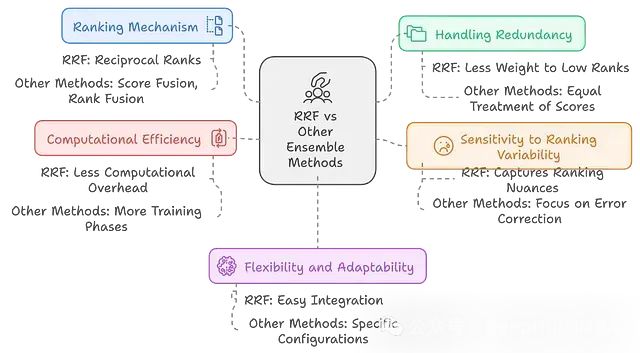
RAPTOR:多模型融合+层次结构 = 检索性能提升20%,结果还更稳健
RAPTOR通过结合多个检索模型,构建层次化的信息组织结构,并采用递归摘要等技术,显著提升了检索系统的性能和适应性。
模型安全:自然语言处理与安全
模型安全:自然语言处理与安全作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming关键词:模型安全性,攻击防御机制,可解释性,隐私保护,责任归属1.背景介绍1.1 问题的由
转置卷积 transposed convolution
通过上面分析,就可以知道为什么通过对输入特征图进行填充使用转置的卷积核并且使用转置卷积核与输入特征图进行步长=1的普通卷积操作就可以得到结果。
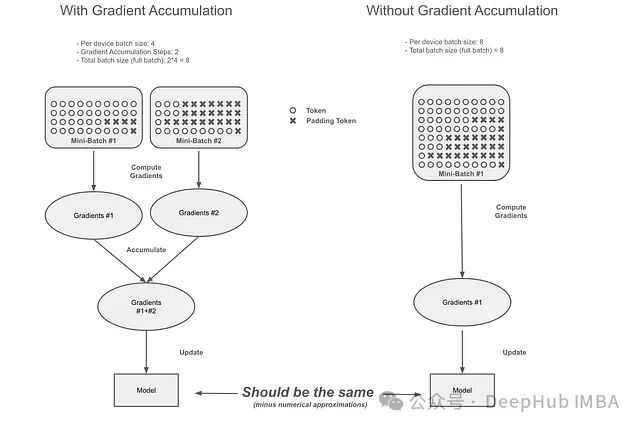
梯度累积的隐藏陷阱:Transformer库中梯度累积机制的缺陷与修正
本文将从以下几个方面展开讨论:首先阐述梯度累积的基本原理,通过实例说明问题的具体表现和错误累积过程;其次分析不同训练场景下该问题的影响程度;最后评估Unsloth提出并已被Hugging Face在Transformers框架中实现的修正方案的有效性。
PRCV2024:可信AI向善发展与智能文档加速构建
在PRCV2024中,合合信息图像算法研发总监郭丰俊老师针对生成式人工智能时代下图像内容安全和智能文档加速的相关技术,分享了自己的独到见解,并介绍了合合信息在这两个方向上取得的进步。接下来,让我们深入了解一下GAI在智能文档领域带来的挑战与机遇。
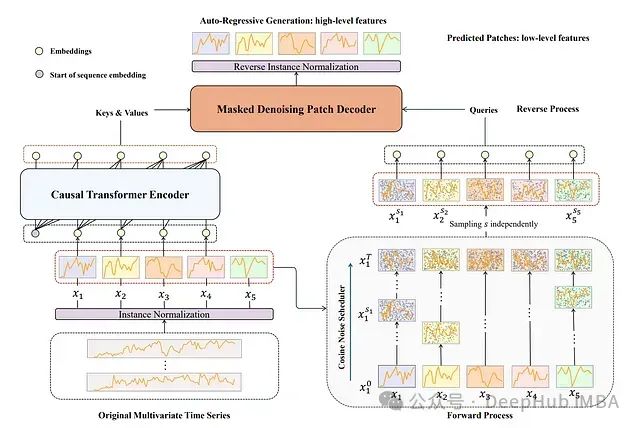
TimeDART:基于扩散自回归Transformer 的自监督时间序列预测方法
TimeDART是一种专为**时间序列预测**设计的自**监督学习**方法。它的核心思想是通过从时间序列历史数据中学习模式来改进未来数据点的预测。
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
本文对transformers之pipeline的令牌分类(token-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的令牌分类(token-classificati
SOLOv2(NeurIPS 2020)论文与代码解读
本文针对SOLO中存在的三个影响性能的瓶颈提出了对应的优化方法,提出了SOLOv2。
用GPT打造一个专门写网文小说的AI智能体!轻松掌控故事发展
它可以根据你提供的输入(prompt)生成符合逻辑的内容,而训练一个AI智能体就是定制和优化这个能力,使其更符合你的个人需求,比如专门为你撰写某种风格或类型的网文小说。通过训练,你可以让AI根据指定的角色、剧情线、写作风格等,自动生成大量文本,极大地提升写作效率,同时还可以为你提供不同的灵感。你可以
【AI大模型】深入Transformer架构:输入和输出部分的实现与解析
因为在Transformer的编码器结构中, 并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
开源模型应用落地-Qwen2.5-7B-Instruct与vllm实现离线推理-降本增效(一)
将Qwen2.5模型与vLLM框架进行有效整合,通过离线推理为实际项目带来更大的价值。
AnimeGANv3: 快速将照片和视频转换为动漫风格的革命性AI模型
AnimeGANv3作为一种革命性的图像风格转换模型,不仅在技术上取得了突破,还为创意产业带来了新的可能性。随着AI技术的不断发展,我们可以期待看到更多像AnimeGANv3这样创新的应用,不断推动艺术创作和内容制作的边界。无论你是专业的创意工作者,还是对动漫和艺术感兴趣的普通用户,AnimeGAN
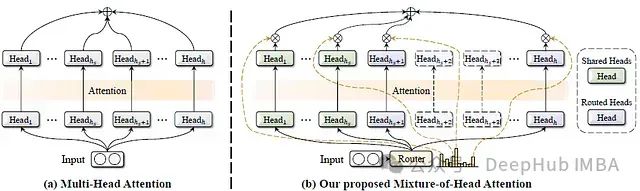
MoH:融合混合专家机制的高效多头注意力模型及其在视觉语言任务中的应用
这篇论文提出了一种名为混合头注意力(Mixture-of-Head attention, MoH)的新架构,旨在提高注意力机制的效率,同时保持或超越先前的准确性水平。
ai写的论文查重率高吗?分享4款ai论文查重软件
如果AI写作软件所使用的训练数据与已有的文献高度相似,或者用户输入的关键词和句式与已有的文献相同,那么生成的文本内容可能与已有的文献高度重复,从而导致较高的查重率。在实际应用中,AI写作论文的查重率并不是固定的,受到算法、数据、主题、领域和用户操作等多种因素的影响。因此,选择全面且可靠的文献数据库,
关于Linux中引用auto_gptq提示“CUDA extension not installed”
引用auto_gptq时报CUDA extension not installed的提示。2、安装bitsandbytes。3、从源码安装gptq。
【AI知识点】交叉注意力机制(Cross-Attention Mechanism)
交叉注意力机制(Cross-Attention Mechanism) 是一种在深度学习中广泛使用的技术,尤其在序列到序列(sequence-to-sequence)模型和Transformer 模型中被大量应用。它主要用于不同输入之间的信息交互,使模型能够有效地将来自不同来源的上下文进行对齐和关注,
联邦学习研究方向及论文推荐(二)
第二篇联邦学习论文推荐。
Vit transformer中class token作用
因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。其中训练的时候,class token的em
【AI知识点】残差网络(ResNet,Residual Networks)
残差网络(ResNet,Residual Networks) 是由微软研究院的何凯明等人在 2015 年提出的一种深度神经网络架构,在深度学习领域取得了巨大的成功。它通过引入残差连接(Residual Connection) 解决了深层神经网络中的梯度消失(Vanishing Gradient) 问
扩散引导语言建模(DGLM):一种可控且高效的AI对齐方法
随着大型语言模型(LLMs)的迅速普及,如何有效地引导它们生成安全、适合特定应用和目标受众的内容成为一个关键挑战。例如,我们可能希望语言模型在与幼儿园孩子互动时使用不同的语言,或在撰写喜剧小品、提供法律支持或总结新闻文章时采用不同的风格。目前,最成功的LLM范式是训练一个可用于多种任务的大型自回归模



