Resnet结构介绍
ResNet,全称为残差网络(Residual Networks),是一种深度卷积神经网络架构,由微软研究院的Kaiming He等人于2015年提出。ResNet在多个视觉识别任务中取得了当时的最佳性能,并在深度学习领域产生了深远的影响。
开源模型应用落地-从源代码构建和运行vLLM-以满足您更高的需求
通过vLLM源码构建Docker镜像,提升了构建的灵活性与安全性,同时也优化了研发与部署的效率。
【动手学深度学习】8.1. 序列模型(个人向笔记)
想象一下有人正在看网飞(Netflix,一个国外的视频网站)上的电影。 一名忠实的用户会对每一部电影都给出评价, 毕竟一部好电影需要更多的支持和认可。 然而事实证明,事情并不那么简单。 随着时间的推移,人们对电影的看法会发生很大的变化。
Agent Q:自主 AI 智体的高级推理和学习
24年8月来自MultiOn AGI公司和斯坦福大学的论文“”Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents“。
人工智能 | BP神经网络
到这里已经可以重新描述BP神经网络的定义了,官方的说法是“按照误差逆向传播算法训练的。
CNN卷积神经网络代码实现及解析(仅全连接层)
CNN卷积神经网络代码实现及解析(仅全连接层),适合0基础,非常详细的学习记录
关于深度学习中的cuda编程,cuda相关介绍
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由Nvidia开发的编程模型和并行计算平台。在模式识别任务中,使用cuda进行GPU加速可以显著提升计算能力,通过并行化任务更快的执行简单矩阵操作PyTorch提供了torch.cuda库来设置和运
【增量学习】7种典型场景
所有训练样本属于同一个任务,并分批到达。
linux-ubuntu20网卡驱动安装AX201
实测安装上了AX201的驱动,从无到有。内核直接使用最新的即可,其余安装部分都与上述教程相同。
植物数据集-全面多种杂草识别的数据集
CWD30数据集,专为作物杂草识别任务设计。CWD30包含219,770张高分辨率图像,涵盖20种杂草和10种作物的不同生长阶段、多角度视角和多种环境条件。数据集从不同地理位置和季节的农田收集,确保了数据的代表性。其分层分类法实现了细粒度分类,有助于开发更精确和强大的深度学习模型。广泛的基线实验表明
【AI前沿】计算机视觉的10个突破性进展:实际应用、挑战与方向
【AI前沿】计算机视觉的10个突破性进展:实际应用、挑战与方向
科研论文必备:10大平台和工具助你高效查找AI文献
Research Rabbit是一款基于引文网络的文献检索及可视化工具,它可以根据用户提供的种子文献,自动推荐相关文献,并以可视化的方式展示文献之间的关系,可查看领域大牛及学者间的合作关系。Connected Papers是一款基于引文网络的文献检索与分析工具,它可以根据用户提供的一篇种子文献,构建
【重磅升级】基于大数据的股票量化分析与预测系统
本项目利用 Python 网络爬虫技术从某财经网站网站实时采集A股各大指数、个股的 K线数据、公司简介、财务指标、机构预测、资金流向、龙虎榜等数据,并进行 KDJ、BOLL等技术指标的计算和收益率的量化计算,构建股票数据分析与预测系统,深入挖掘板块热点、资金流向、市场估值等,并利用 Tensorfl
VSCode入门操作| 配置anaconda终端完整顺畅版
全流程适合新手以及换新机重新配置存档。配好后能够直接运行 python、pip、conda 命令,而无需担心环境的选择问题。一旦激活 Anaconda 环境,VSCode 的终端会使用 Anaconda 环境中的 Python 解释器和库,确保能够顺畅使用该环境中的所有包和依赖项。
用国产AI大模型通义千问写论文的保姆级教程(附AI写作工具)
之前咱们出过两篇保姆级教程,分别是用ChatGPT写学术论文和用Kimi写论文的教程,今天我选择的是阿里巴巴出品的ai大模型通义千问,亲测一下用通义千问写出来的论文初稿水平如何。通过AI的联系上下方功能和角色扮演功能,非常快速完成论文初稿的建立,而对于论文内容润色和细化,则需要不断通过提问AI,提问
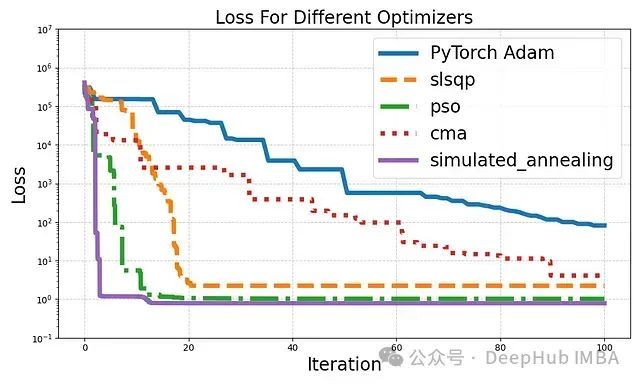
如果你的PyTorch优化器效果欠佳,试试这4种深度学习中的高级优化技术吧
在深度学习领域,优化器的选择对模型性能至关重要。
2. 将GitHub上的开源项目导入(clone)到(Linux)服务器上——深度学习·科研实践·从0到1
目录1. 在github上搜项目 (以OpenOcc为例)2. 转移到码云Gitee上3. 进入Linux服务器终端 (jupyter lab)4. 常用Linux命令5. 进入对应文件夹中导入项目(代码)
【MADRL】反事实多智能体策略梯度(COMA)算法
反事实多智能体策略梯度法COMA (Counterfactual Multi-Agent Policy Gradient) 是一种面向多智能体协作问题的强化学习算法,旨在通过减少策略梯度的方差,来提升去中心化智能体的学习效果。COMA 算法最早由 DeepMind 团队提出,论文标题为 "Count
开源模型应用落地-工具使用篇-JMeter(一)
使用JMeter工具压测AI服务链路,及时发现潜在的性能瓶颈
【人工智能环境搭建】Win11+WSl2+Ubuntu+CUDA+cuDNN+Pytorch搭建教程
作为一名科班研究生,在科研环境方面踩了很多坑,历时两天终于搭建成功环境,借此契机想将其中的坑之处与大家分享,帮助刚入门的小白避免一些坑。下面就开是我们今天的教程吧!本次教程版本:Win11、WSL2、Ubuntu22.04、CUDA12.4、cuDNN8.9.7、Pytorch2.4.1、pytho



