SparkHBase整合原理与代码实例讲解
Spark-HBase整合原理与代码实例讲解1. 背景介绍1.1 问题的由来在大数据时代,数据量的快速增长使得传统的数据处理方式已经无法满足现有需求。Apache Spark和Apache HBase作为两个广泛使用的大数据处
数据可视化:PrestoHive数据可视化方案
数据可视化:Presto-Hive数据可视化方案1. 背景介绍1.1 数据可视化的重要性在当今大数据时代,企业每天都会产生海量的数据。如何有效地分析和利用这些数据,已经成为企业获得竞争优势的关键。数据可视化技术能够
vision mamba 原理篇
与 transformer中注意力机制不同,S6 将 1D 向量中的每个元素(例如文本序列)与在此之前扫描过的信息进行交互,从而有效地将二次复杂度降低到线性。然而,由于视觉信号(如图像)不像文本序列那样具有天然的有序性,因此无法在视觉信号上简单地对 S6 中的数据扫描方法进行直接应用。在 CSM 的
IJCAI 2024 | 时空数据(Spatial-Temporal)论文总结
2024 IJCAI(International Joint Conference on Artificial Intelligence, 国际人工智能联合会议)在2024年8月3日-9日在举行。本文总结了IJCAI2024有关的相关论文,如有疏漏,欢迎大家补充。:时空(交通)预测,气象预测,轨迹
Lumen5——AI视频制作,提取关键信息生成带有视觉效果的视频
模板系统:Lumen5 提供了多种预设视频模板,涵盖不同的使用场景(如市场营销、社交媒体视频等)。这些模板通过前端与后端的集成动态加载,用户可以快速选择并应用。模板样式的自动化设计可能使用了基于设计原则的推荐系统,确保视觉上的统一性。品牌元素定制:高级用户可以上传自定义的品牌标志、选择特定的字体和配

在Pytorch中为不同层设置不同学习率来提升性能,优化深度学习模型
为网络的不同层设置不同的学习率可能会带来显著的性能提升。本文将详细探讨这一策略的实施方法及其在PyTorch框架中的具体应用
【AI战略思考2】技术上不断聚焦和深入,精进一艺,一技胜万全
本篇博客确定了我大致的研究方向和原则:研究方向:nlp领域下的RAG技术应用方向,企业普遍存在的一个痛点和难点,且有较大的实用价值。原则:不断聚焦和深入
开源模型应用落地-sherpa-onnx-AIGC应用探索(十)
使用sherpa-onnx,一站式解决各种语音难题。
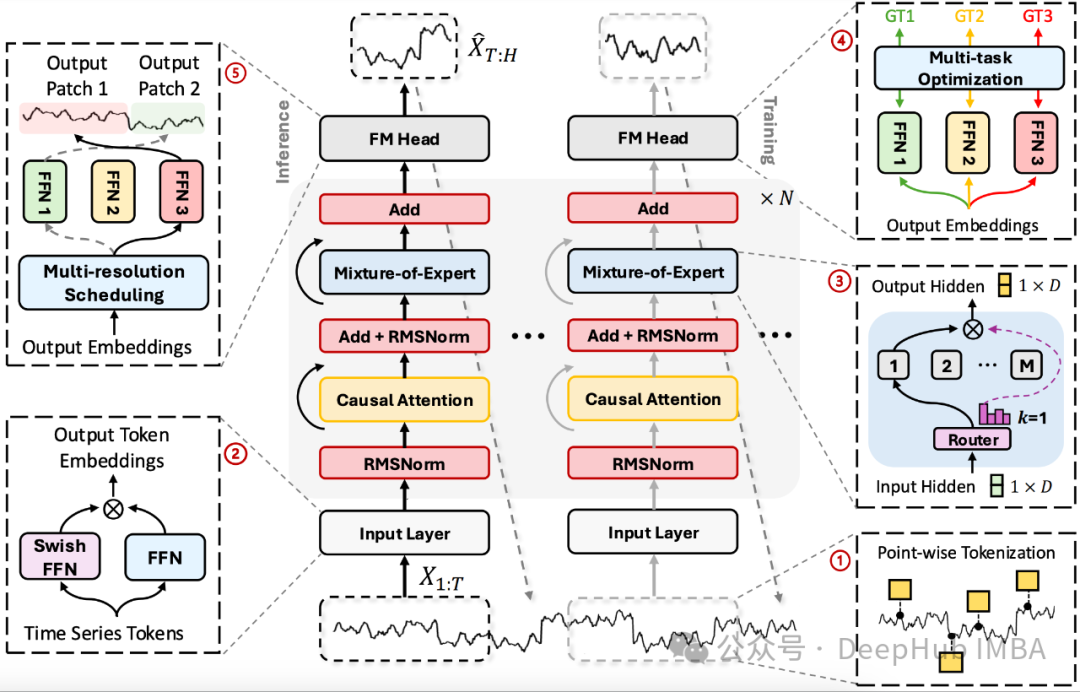
TimeMOE: 使用稀疏模型实现更大更好的时间序列预测
这是9月份刚刚发布的论文TimeMOE。它是一种新型的时间序列预测基础模型,"专家混合"(Mixture of Experts, MOE)在大语言模型中已经有了很大的发展,现在它已经来到了时间序列。
GNN会议&期刊汇总(人工智能、机器学习、深度学习、数据挖掘)
顶会顶刊:【NeurIPS】【ICLR】【AAAI】【WWW】【ICML】【LoG】【CIKM】【WSDM】【KDD】【IJCAI】【TKDE】
Wordware暴走:AI社交裂变的妙用与隐患探讨
最近,推特(X)上出现了一个风靡全球的社交应用——**Wordware**。该应用引发了一场社交裂变的热潮,连埃隆·马斯克都参与其中,展示了它的社交吸引力。然而,伴随这一现象的爆发,也让我们看到了AI技术在社交网络中的巨大潜力与隐患。本文将通过技术分析与案例解读,详细探讨Wordware的妙用及其背
司南 OpenCompass 5 月榜单揭晓,全新大模型对战榜单首次登场
司南 OpenCompass 团队针对国内外主流大语言模型进行了全面评测,现已公布 2024 年 5 月大语言模型最新评测榜单!与此同时,CompassArena 大模型对战榜单 也于今日首次重磅上线!
开源模型应用落地-LangChain实用小技巧-使用CacheBackedEmbeddings组件(九)
使用CacheBackedEmbeddings组件提升处理效率和数据可靠性
差分隐私与联邦学习安全原理与代码实战案例讲解
差分隐私与联邦学习安全原理与代码实战案例讲解作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming1. 背景介绍1.1 问题的由来随着大数据时代的到来,
Coggle数据科学 | 科大讯飞AI大赛:人岗匹配挑战赛 赛季3
讯飞智聘是一款面向企业招聘全流程的智能化解决方案。运用科大讯飞先进的智能语音、自然语言理解、计算机视觉等AI技术及大数据能力,具备业界领先的简历解析、人岗匹配、AI面试、AI外呼等产品功能,助力企业提升招聘效率,降低招聘成本。人岗匹配是企业招聘面临一个重大挑战,尤其在校园招聘等集中招聘的场景下,面对
Programmer&AI—AI辅助编程学习指南
随着AIGC(AI生成内容)技术的快速发展,诸如ChatGPT、MidJourney和Claude等大语言模型相继涌现,AI辅助编程工具正逐步改变程序员的工作方式。这些工具不仅可以加速代码编写、调试和优化过程,还能帮助解决复杂的编程难题。然而,这种变革也引发了广泛的讨论:一方面,有人担心AI会逐步取
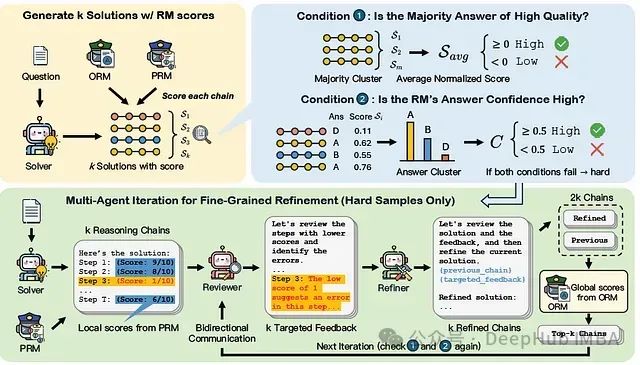
MAGICORE:基于多代理迭代的粗到细精炼框架,提升大语言模型推理质量
论文提出了MAGICORE,一个用于粗到细精炼的多代理迭代框架。MAGICORE旨在通过将问题分类为简单或困难,为简单问题使用粗粒度聚合,为困难问题使用细粒度和迭代多代理精炼,从而避免过度精炼。
optim.Adam()
torch.optim优化算法理解之optim.Adam()-CSDN博客PyTorch优化算法:torch.optim.Adam 的参数详解和应用-CSDN博客optim.Adam是 PyTorch 中一种非常流行的优化器,它是 Adam(Adaptive Moment Estimation)优化
d2l-ai深度学习日记之预备知识(一)
在我进行计算机学习的今天,正是ChatGpt等语言大模型火热的时间,并且当前国内就业形式严峻,想要考研深造,不得不接触深度学习,神经网络等等生涩难懂,以前研究生才会学习的知识.在写这篇文章之前,我已经稍微接触后了解了一下神经网络等相关知识,尝试地参加了一些相关的比赛等等,但是还是感觉完全不理解,所有
Transformer大模型实战 文本摘要任务
随着互联网和数字化时代的到来,每天产生的文本数据量呈爆炸式增长。如何有效地从这些海量的文本数据中提取关键信息,快速获取知识,成为了一个亟待解决的问题。文本摘要任务,作为一种信息提取技术,旨在自动生成文本的简洁、概括的版本,从而帮助用户快速了解文本内容。文本摘要任务主要分为两种类型:抽取式摘要和生成式



