20240927 每日AI必读资讯
我们最近发布的语音到语音转换和OpenAI O1标志着交互和智能的新时代的开始——这些成就是由你们的聪明才智和手艺实现的。在这个过程中,AI会通过多次尝试得到反馈。这个阶段的重点是让AI明白哪些地方出错了,并且不会只做一些很小的、无关紧要的修改,而是能够真正找到并改正大的错误。这一成功证明了我们出色
开源模型应用落地-Qwen2.5-7B-Instruct与vllm实现离线推理-CPU版本
使用CPU将Qwen2.5-7B-Instruct模型与vLLM框架进行有效整合(使用vLLM框架,能为模型推理提供强有力的支持,使得在CPU上执行的模型不仅能保持较高的准确率,还能在资源有限的条件下,实现快速响应,充分释放潜在价值)
【代码复现训练】Vision Transformer(ViT)
尝试使用ViT做一个简单的花卉分类任务,默认使用ViT-B/16模型
张量分解(3)——CP分解
张量分解第三节,详细解释了何为CP分解,CP分解的公式,如何优化CP分解中参数。
Github上的十大RAG(信息检索增强生成)框架
RAG框架正在快速发展,呈现出百花齐放的盛况。从功能全面、久经考验的Haystack,到专注领域创新的FlashRAG和R2R,各具特色的框架为不同需求和应用场景提供了优质的选择。项目的具体需求和约束所需的定制化和灵活性框架的可扩展性和性能表现框架背后社区的活跃度和贡献度文档和技术支持的完备性通过系
【深度学习|地学应用】人工智能技术的发展历程与现状:探讨深度学习在遥感地学中的应用前景
【深度学习|地学应用】人工智能技术的发展历程与现状:探讨深度学习在遥感地学中的应用前景
AIGC实战——生成式人工智能总结与展望
近年来,生成模型取得了突破性进展,生成式人工智能拥有了无限可能性和潜在影响,有着无限的实际应用潜力,我们期待着生成式人工智能够产生更广泛的影响。生成模型领域不仅仅是关于创建图像、文本或音乐的应用,而且生成式深度学习隐藏着人工智能的本质。在本节中,将概述生成式人工智能的发展历史,然后探讨生成式人工智能
Macbook配置李沐动手做深度学习环境
Macbook M3pro配置李沐:动手做深度学习
人工智能大模型工作原理(包括数据收集与预处理、大模型训练、大模型部署与应用)
人工智能大模型工作原理(包括数据收集与预处理、大模型训练、大模型部署与应用)
开源模型应用落地-Qwen2.5-7B-Instruct与sglang实现推理加速的正确姿势
Qwen2.5-7B-Instruct集成sglang,构建多样化的语言模型应用。
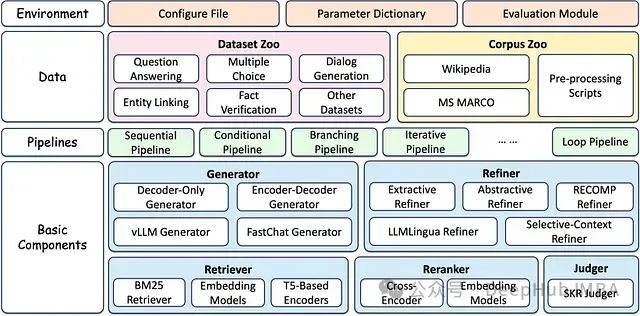
Github上的十大RAG(信息检索增强生成)框架
随着对先进人工智能解决方案需求的不断增长,GitHub上涌现出众多开源RAG框架,每一个都提供了独特的功能和特性。
AI教父荣获2024诺贝尔物理学奖:杰弗里·辛顿和他的深度学习之路!
杰弗里·辛顿(Geoffrey Hinton)凭借在人工神经网络领域的开创性研究,获得了2024年诺贝尔物理学奖,这也使得辛顿成为了全世界首个同时获得图灵奖和诺贝尔奖的科学家。
自适应神经网络架构:原理解析与代码示例
自适应神经网络架构
图像生成(Text-to-Image)发展脉络
图像生成(文生图)发展脉络梳理
GitHub 上高星 AI 开源项目推荐
GitHub 上高星 AI 开源项目推荐
人工智能深度学习系列—深入解析:均方误差损失(MSE Loss)在深度学习中的应用与实践
在深度学习的世界里,损失函数犹如一把尺子,衡量着模型预测与实际结果之间的差距。均方误差损失(Mean Squared Error Loss,简称MSE Loss)作为回归问题中的常见损失函数,以其简单直观的特点,广泛应用于各种预测任务。本文将带您深入了解MSE Loss的背景、计算方法、使用场景以及
开源模型应用落地-业务优化篇(一)
在业务整合之后,我们将把注意力转向非功能性需求。接下来,我将逐步向您介绍如何发现系统的性能瓶颈,并通过技术优化来提高系统的各项性能指标。
AI大模型系列之七:Transformer架构讲解
Transformer模型设计之初,用于解决机器翻译问题,是完全基于注意力机制构建的编码器-解码器架构,编码器和解码器均由若干个具有相同结构的层叠加而成,每一层的参数不同。编码器主要负责将输入序列转化为一个定长的向量表示,解码器则将这个向量解码为输出序列。Transformer总体架构可分为四个部分
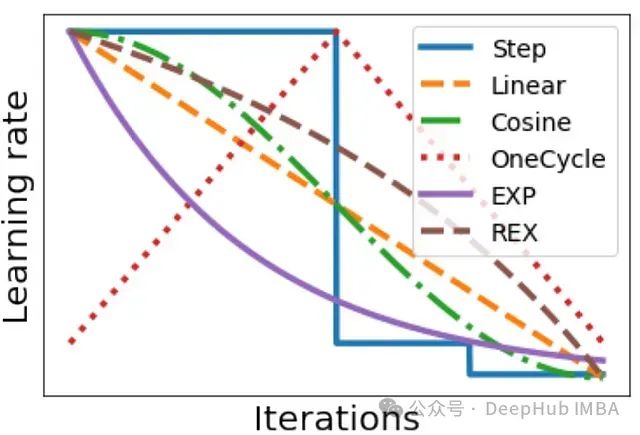
深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。
OpenVLA:一个开源的视觉-语言-动作模型
24年6月来自 Stanford、UC Berkeley、TRI、Deepmind 和 MIT的论文“OpenVLA: An Open-Source Vision-Language-Action Model”。



