【AI大模型】深入Transformer架构:编码器部分的实现与解析(上)
编码器部分:* 由N个编码器层堆叠而成 * 每个编码器层由两个子层连接结构组成 * 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接 * 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,

VisionTS:基于时间序列的图形构建高性能时间序列预测模型,利用图像信息进行时间序列预测
本文将讨论以下几个方面: - 图像如何在内部编码序列信息? - 利用预训练计算机视觉模型进行时间序列分析的概念 - ***VisionTS***:一种适用于时间序列数据的预训练Vision Transformer模型。
开源模型应用落地-Qwen2.5-7B-Instruct与vllm实现推理加速的正确姿势(一)
Qwen2.5-7B-Instruct集成vllm,流式输出
Minstrel自动生成结构化提示,让AI为AI写提示词的多代理提示生成框架
LangGPT作为一个结构化的提示设计框架,具有良好的系统性和可重用性,易于学习和使用。Minstrel能够通过多代理协作自动生成高质量的结构化提示,在某些情况下甚至超过人类专家的表现。结构化提示(无论是Minstrel生成还是手动编写)在指导LLMs执行任务时表现更好,特别是对于较大规模的模型。然
真的没有AI能通过草莓测试?GPT-4o也不行!
真的没有AI能通过草莓测试?GPT-4o也不行!
探索人工智能绘制宇宙地图的实现
由于它分析了距离地球很远的区域,因此得到的模拟结果反映了遥远的过去,揭示了有关天体在数千年间如何移动的新信息。虽然了解恒星很重要,但绘制行星表面的物理地图在短期内可能更有帮助,尤其是在太空探索兴起的情况下。随着模型通过更多数据得到改进,它们可以为更安全的太空旅行提供信息,或提供对太阳耀斑或超新星等活
开源模型应用落地-qwen模型小试-调用Qwen2-VL-7B-Instruct-更清晰地看世界-集成vLLM(二)
掌握Qwen2-VL与vLLM集成,提升职业发展增添强大的竞争力
开源模型应用落地-qwen模型小试-调用Qwen2-VL-7B-Instruct-更清晰地看世界(一)
掌握Qwen2-VL提升职业发展增添强大的竞争力
Spark 和 NVIDIA GPU 加速深度学习
随着人们对深度学习( deep learning , DL )兴趣的日益浓厚,越来越多的用户在生产环境中使用 DL。由于 DL 需要强大的计算能力,开发人员正在利用 gpu 来完成他们的训练和推理工作。最近,为了更好地统一 Spark 上的 DL 和数据处理,作为的一项重大举措的一部分, GPU 成
时频分析法——连续小波变换(CWT)
连续小波变换利用一组基函数(称为小波)对信号进行分析。这些小波是由一个母小波通过平移和缩放生成的。母小波 ψ(t) 是一个平均值为零的波形,通常具有快速衰减的特性。通过调整缩放因子 a 和平移参数 b 来生成不同的小波,从而能够聚焦于信号的不同特性。小波变换可以定义为:其中f(t) 是输入信号;ψ(
天池 大模型逻辑推理 入门
第二届世界科学智能大赛逻辑推理赛道:复杂推理能力评估
机器学习,深度学习,AGI,AI的概念和区别
人工智能(AI)是指通过计算机系统模拟人类智能的技术和科学。AI的目标是创建能够执行通常需要人类智能的任务的系统,如视觉识别、语音识别、决策制定和语言翻译。AI的核心在于其能够处理和分析大量数据,从中提取有用的信息,并根据这些信息做出决策或预测。AI的发展可以追溯到20世纪50年代,当时科学家们开始
【深度学习】使用VScode远程服务器GPU进行训练
我这里使用的是mobaxterm来传输文件,视频中的作者使用的是另外一种软件,大家都可以尝试使用,我是因为电脑中本来就有这个mobaxterm就懒得下载up推荐的那个了。下载好mobaxterm之后我们打开它,点击。打开vscode,在插件管理处安装插件。回车之后即可连接成功!
AI生成人脸图像鉴别-数据集(附网盘地址)
百度网盘地址:链接: https://pan.baidu.com/s/1_3j0OwQF63eznPH1RR596g?pwd=1234 提取码: 1234 复制这段内容后打开百度网盘手机App,操作更方便哦。该数据集有5000张真实人脸照片,尺寸为1024*1024像素,即比例为1:1,均为人工筛选
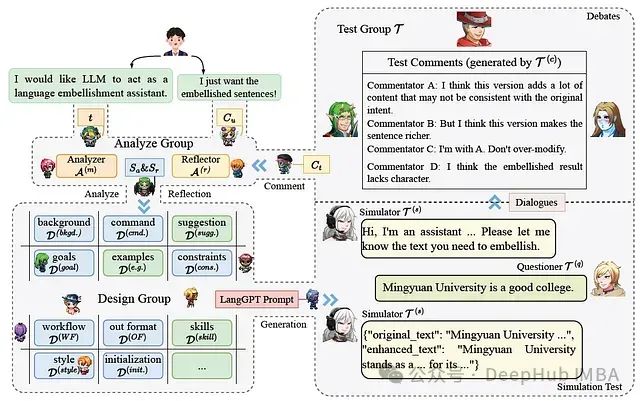
Minstrel自动生成结构化提示,让AI为AI写提示词的多代理提示生成框架
在人工智能快速发展的今天,如何有效利用大型语言模型(LLMs)成为了一个普遍关注的话题。这是9月份的一篇论文,提出了LangGPT结构化提示框架和Minstrel多代理提示生成系统,为非AI专家使用LLMs提供了强大支持。
Datawhale X 李宏毅苹果书 AI夏令营 Task2- 优化机器学习模型和深度学习初认识
一、初识线性模型在上一篇的Task1中,我们最后谈到了梯度下降在一维和二维情况下的过程,现在让我们进一步地讨论机器学习这个话题。Task1里,我们举了用今天的数值预测明天的观看量的例子,下面是根据真实数据所做的图,预测时所用到的模型函数是贴合现实的。从图中,我们可以清晰地看到红线与蓝线是几乎重合的,
斯坦福大学研究人员,推荐的课题申报AI提示词分享
请根据这份项目清单<插入项目>,为我的资助提案制定一个可行的项目时间表,用于我的职业发展计划,从<XX月>开始,为期<XX个月>。请就我如何满足这一评审标准:<插入具体评审标准>提供反馈,以及对我遗漏的内容和如何改进的建议。请就我如何满足这一评审标准:<插入具体评审标准>提供反馈,以及对我遗漏的内容
大模型API调用(一)简单用法
大模型API调用是指通过编程接口(API)访问大型人工智能模型,以实现自然语言处理、代码生成、内容创作等多种功能。大模型的API扮演了一个接口(Interface)的角色,它允许用户以编程方式与大模型进行交互,而无需深入了解模型内部的复杂结构和算法。这种模式类似于模型即服务(Model as a S
开源模型应用落地-业务优化篇(七)
通过多种技术整合,为降本增效赋能,让公司对你眼前一亮。本篇学习RocketMQ的实际使用。



