深度学习图像识别笔记(三):yolov5检测结果分析
yolov5学习
AI提效工具|借助chatgpt快速读论文,快速总结、归纳、索引相似文章
本文展示了两个借助chatgpt快速总结论文的工具,让你读论文速度快到飞起~
Anaconda(python)安装教程以及创建新环境
Anaconda(python)安装教程以及创建新环境
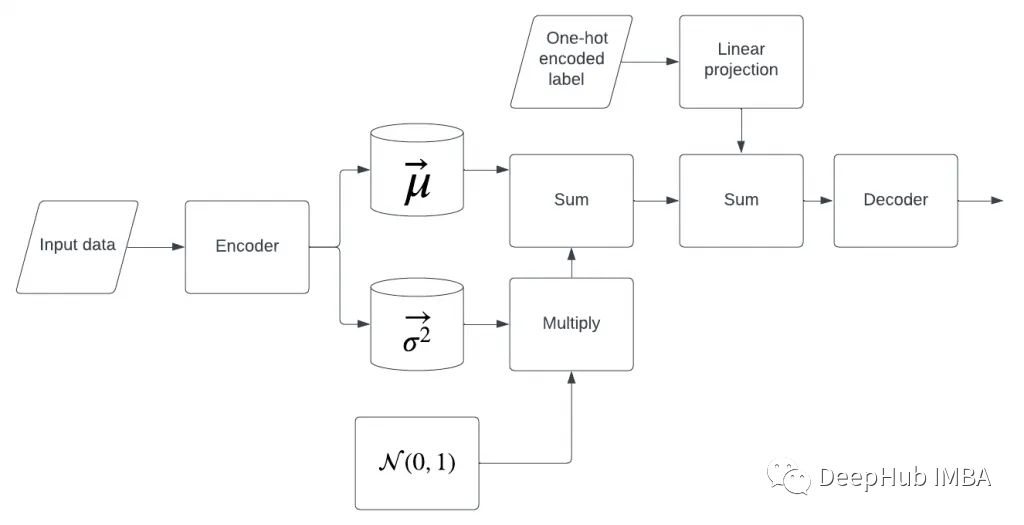
从零开始实现VAE和CVAE
扩散模型可以看作是一个层次很深的VAE(变分自编码器)本文将用python从头开始实现VAE和CVAE,来增加对于它们的理解。
【PyTorch】教程:DCGAN
本教程将通过一个示例来介绍 DCGAN。我将训练一个生成对抗网络 (GAN) ,在向其展示许多真实名人的照片后生成新的名人。这里大部分代码来自于。本文档针对这些实现进行全面解释,并阐述该模型的工作方式和原因。
[深度学习] 基于切片辅助超推理库SAHI优化小目标识别
AutoDetectionModel类SAHI基于AutoDetectionModel类的from_pretrained函数加载深度学习模型。目前支持YOLOv5 models, MMDetection models, Detectron2 models和HuggingFace object det
【深度学习】详解 BEiT
【深度学习】详解 BEIT: BERT Pre-Training of Image Transformers
图注意力网络——Graph attention networks (GAT)
文章目录摘要引言摘要 图注意力网络,一种基于图结构数据的新型神经网络架构,利用隐藏的自我注意层来解决之前基于图卷积或其近似的方法的不足。通过堆叠层,节点能够参与到邻居的特征,可以(隐式地)为邻域中的不同节点指定不同的权值,而不需要任何代价高昂的矩阵操作(如反转),也不需要预先知道图的结构。通过这种
循环神经网络
循环神经网络(Recurrent Neural Network,RNN)与卷积神经网络一样,都是深度学习中的重要部分。循环神经网络可以看作一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接收其他神经元的信息,也可以接收自身的信息,形成具有环路的网络结构,正因为能够接收自身神经元信息的
AI工具究竟是帮手还是对手?
近日育碧开发了人工智能工具 Ghostwriter,可以一键生成游戏NPC对话。不少游戏开发者担心AI写手工具的出现会让自己“饭碗”不保,但Swanson表示这个工具只是为了提供第一稿的 barks来减少对话生成工作的繁琐度。AI工具究竟是帮手还是对手?对此你怎么看,一起来聊聊你的看法吧!
LLaMA-META发布单卡就能跑的大模型
2023年2月25日,Meta使用2048张A100 GPU,花费21天训练的Transformer大模型LLaMA开源了。
LSTM实现多变量输入多步预测(直接多输出)时间序列预测(PyTorch版)
本专栏整理了《深度学习时间序列预测案例》,内包含了各种不同的基于深度学习模型的时间序列预测方法,例如LSTM、GRU、CNN(一维卷积、二维卷积)、LSTM-CNN、BiLSTM、Self-Attention、LSTM-Attention、Transformer等经典模型,💥💥💥包含项目原理以
实现mini智能助理—模型训练
1.介绍了预训练大模型的训练流程是怎么样的2.介绍了常用的训练手段3.详细介绍了两种主流的预训练手段原理:promt、delta4.给了一个multi-gpu chatglm训练的例子

ChatGPT的提示的一些高级知识
在这篇文章中,我们将介绍关于提示的一些高级知识。无论是将ChatGPT用于客户服务、内容创建,还是仅仅为了好玩,本文都将为你提供使用ChatGPT优化提示的知识和技巧。
Pytorch深度学习基础 实战天气图片识别(基于ResNet50预训练模型,超详细)
🔥本项目使用Pytroch,并基于ResNet50模型,实现了对天气图片的识别,过程详细,十分适合基础阶段的同学阅读。项目目录结构核心步骤数据处理准备配置文件构建自定义DataSet及Dataloader构建模型训练模型编写预测模块效果展示。
【极客技术】ColossalChat用完整RLHF技术克隆ChatGPT的开源解决方案
在微调过程中,固定大模型的参数,只调整低秩矩阵的参数,大大减少了训练所需的参数数量,降低了成本。在PPO部分,ColossalChat遵循两个阶段的过程:首先,制造经验阶段,它使用SFT(有监督的微调)、参与者、RM(奖励模型)和批评模型来计算生成的经验并将其存储在缓冲区中。此外,Alpaca的训练
最详细的 Windows 下 PyTorch 入门深度学习环境安装与配置 (GPU版本)
anaconda、pytorch深度学习环境搭建
使用自己数据及进行PointNet++分类网络训练
使用自己数据及进行PointNet++分类网络训练



