
现阶段NLP最火的两个idea 一个是对比学习(contrastive learning) 另一个就是 prompt
prompt 说简单也很简单 看了几篇论文之后发现其实就是构建一个语言模板 但是仔细想想又觉得复杂 总感觉里面还有很多细节 因此我想从头到尾梳理一下prompt 很多地方会把它翻译成[范式] 但是这个词本身不好理解 我个人更倾向于看作是模板
首先我们要知道预训练模型(Bert为首)到底做了什么?
我觉得是预训练模型提供了一个非常好的初始化参数 这组参数在预训练任务上的表现非常好(预训练损失非常低) 但是由于下游任务千奇百怪 我们需要在这组参数的基础上进行 Fine-tune 以适应我们的下游任务(使得下游任务的损失值非常低)目前做 NLP 任务的大致流程 即 "Pre-train, Fine-tune",而对我们来说实际上大部分时候都是直接拿别人预训练好的模型做 Fine-tune 并没有 Pre-train 这一步 融入了 Prompt 的模式大致可以归纳成 "Pre-train, Prompt, and Predict",在该模式中 下游任务被重新调整成类似预训练任务的形式 ok 下面我们举例说明
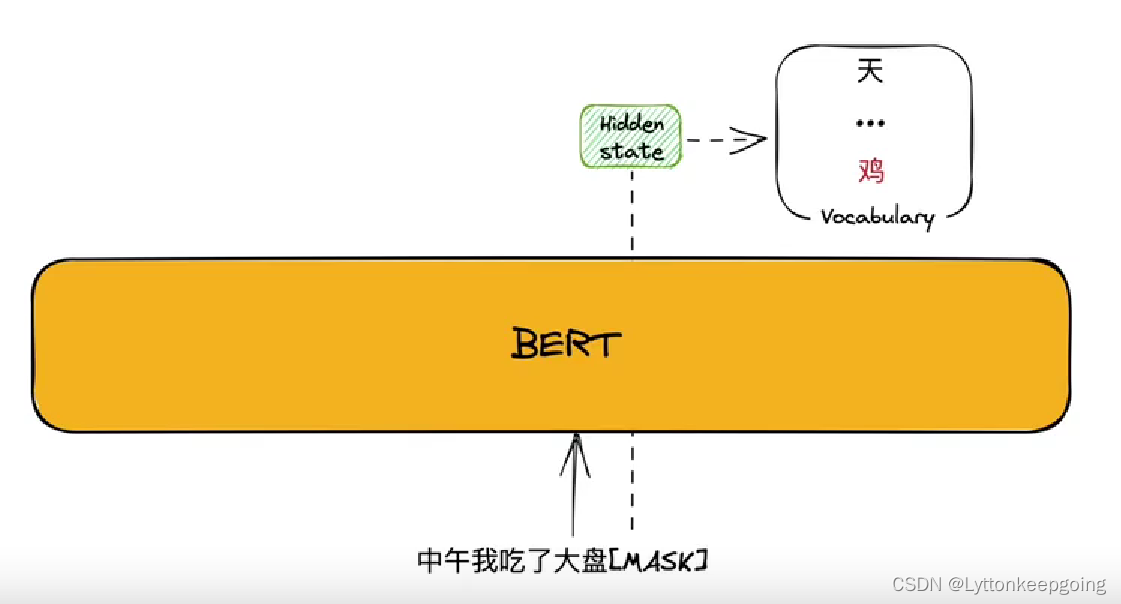
假设我现在输入一句话:中午我吃了大盘[MASK]
然后得到一个hidden state 最后的答案必须在vocabulary 里面选择 候选词是整个词库 我们这里希望他输出‘鸡’ 实际上可能并不是 我们需要用上loss function 当他预测不对时就会产生损失 有损失我们就可以反向传播 然后逐渐纠正[MASK] 从而符合我们的预期
我们这里调用hugging face 里面的api 来测试一下
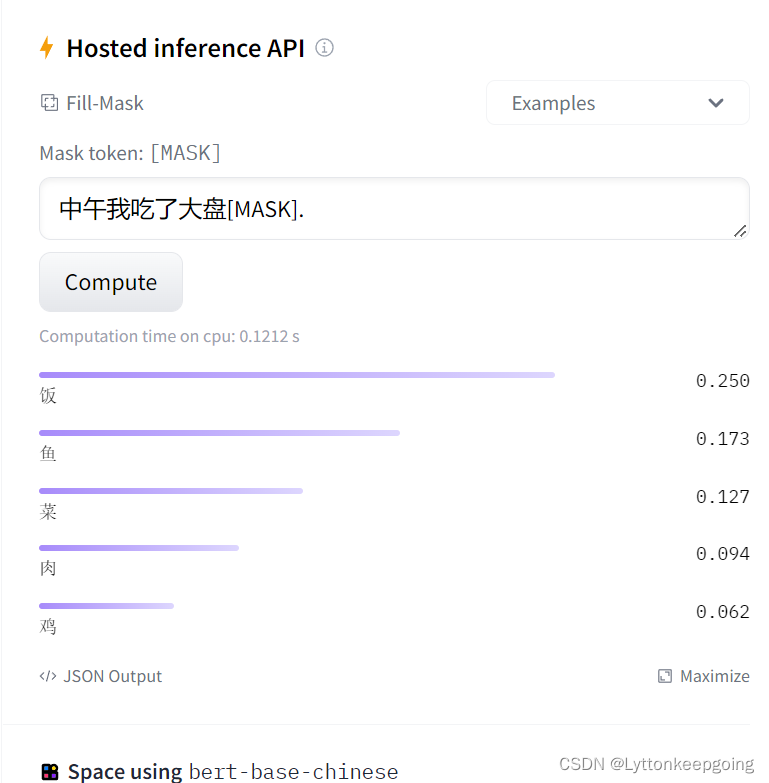
可以看到这里输出概率最高的为饭 这说明在预训练的过程中 实际上并没有看到很多大盘和鸡连在一起的情况 看的比较多的情况是 【中午我吃了大盘饭】 但是你拿下游任务做微调的时候 是可以慢慢的让模型输出‘鸡’ 有更高的概率 那么prompt具体是怎么做呢?这里以情感分析为例
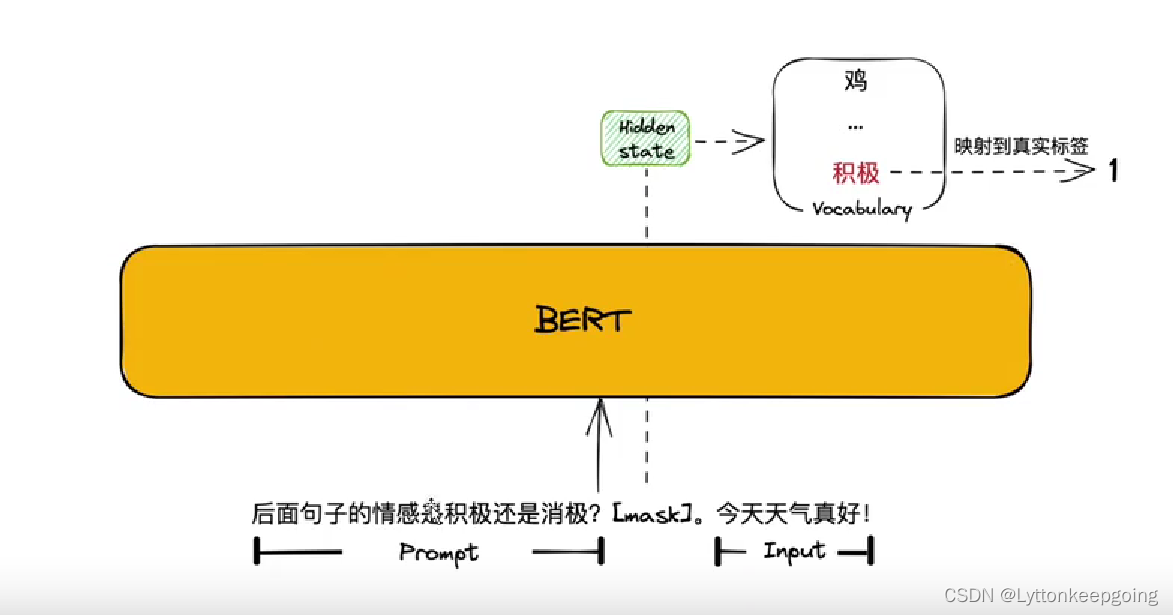
假设这是一个二分类问题 积极或者消极原始我输入的是 【今天天气真好】
我们一般的做法是微调 我们会把这个句子送入bert 然后会得到一个句向量 这个句向量有很多处理方式 crf 或者softmax平均 然后会把它送入一个FC层 他的输出维度一定是二维的 因为是二分类 然后我们做argmax或者softmax 然后得到概率最大的那个下标
prompt这样做:我们会在【今天天气真好】前面问一个问题(或者后面中间也可以)我会问后面的句子情感是积极的还是消极的?然后给他一个MASK 我们希望mask输出是积极 那我们就会映射到真是标签1 但是无论是积极或者是消极 这个token 一定要是vocabulary里面存在的
同时 这个prompt并不是固定的 同样的我们在api中测试一下

在这里我们可以把强映射为1 把弱映射为0 这样就能完成我们的情感分析任务
除了情感分析任务 其他 NLP 任务的 Prompt 如何设计?实际上刘鹏飞大神在他的论文中给我们提供了一些参考
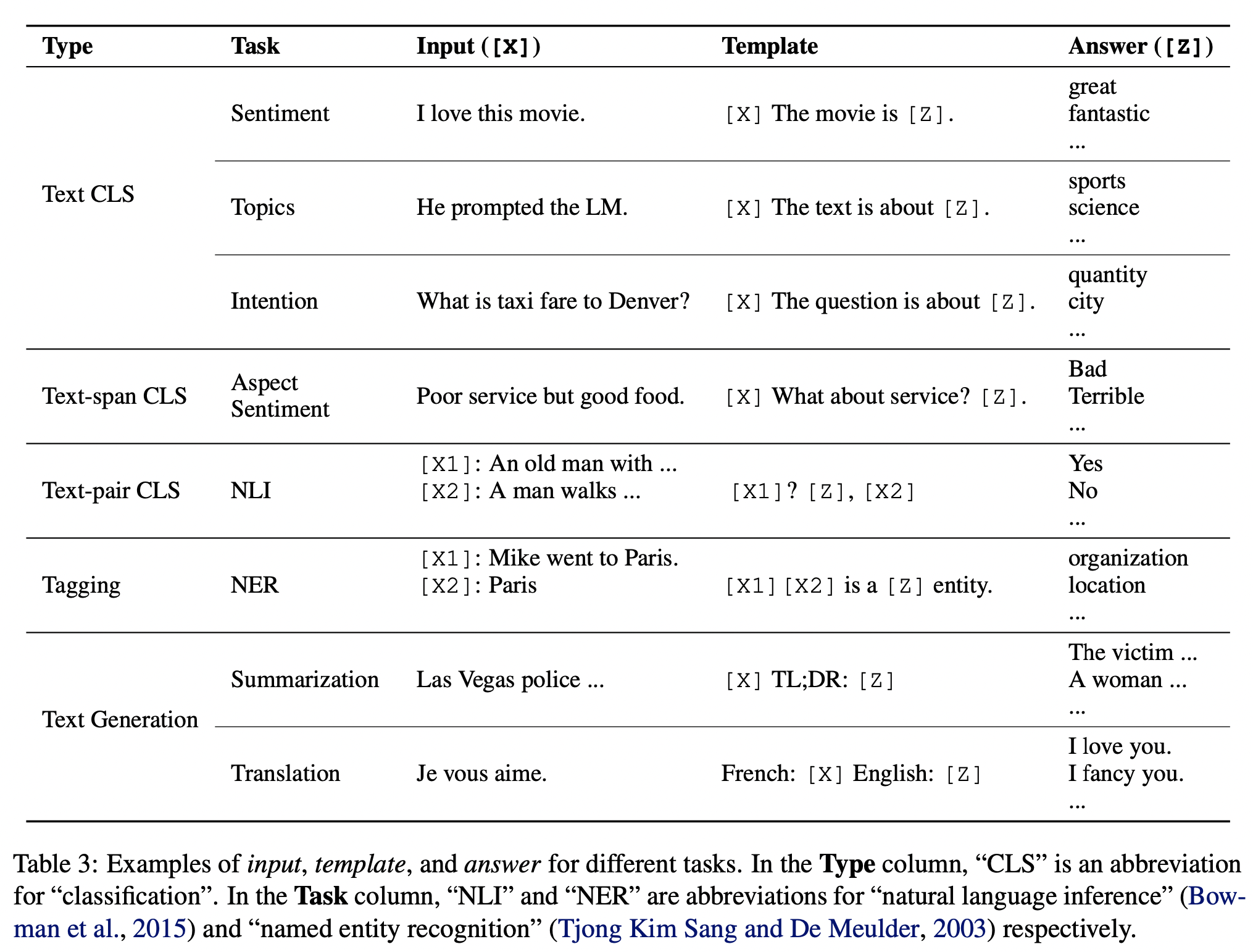
大概了解的prompt任务之后 我们从论文的角度再来深挖一下细节
我们可以将prompt的设计涵盖为两部分:
- 模板 T:例如
[X]. Overall, It was [Z] - 标签词映射:即 [Z] 位置预测输出的词汇集合与真实标签 y 构成的映射关系。例如,标签 positive 对应单词 great,标签 negative 对应单词 terrible
在基于 Prompt 的微调方法中 不同的模板和标签词对最终结果影响很大 下图是陈丹琦团队论文中的实验结果
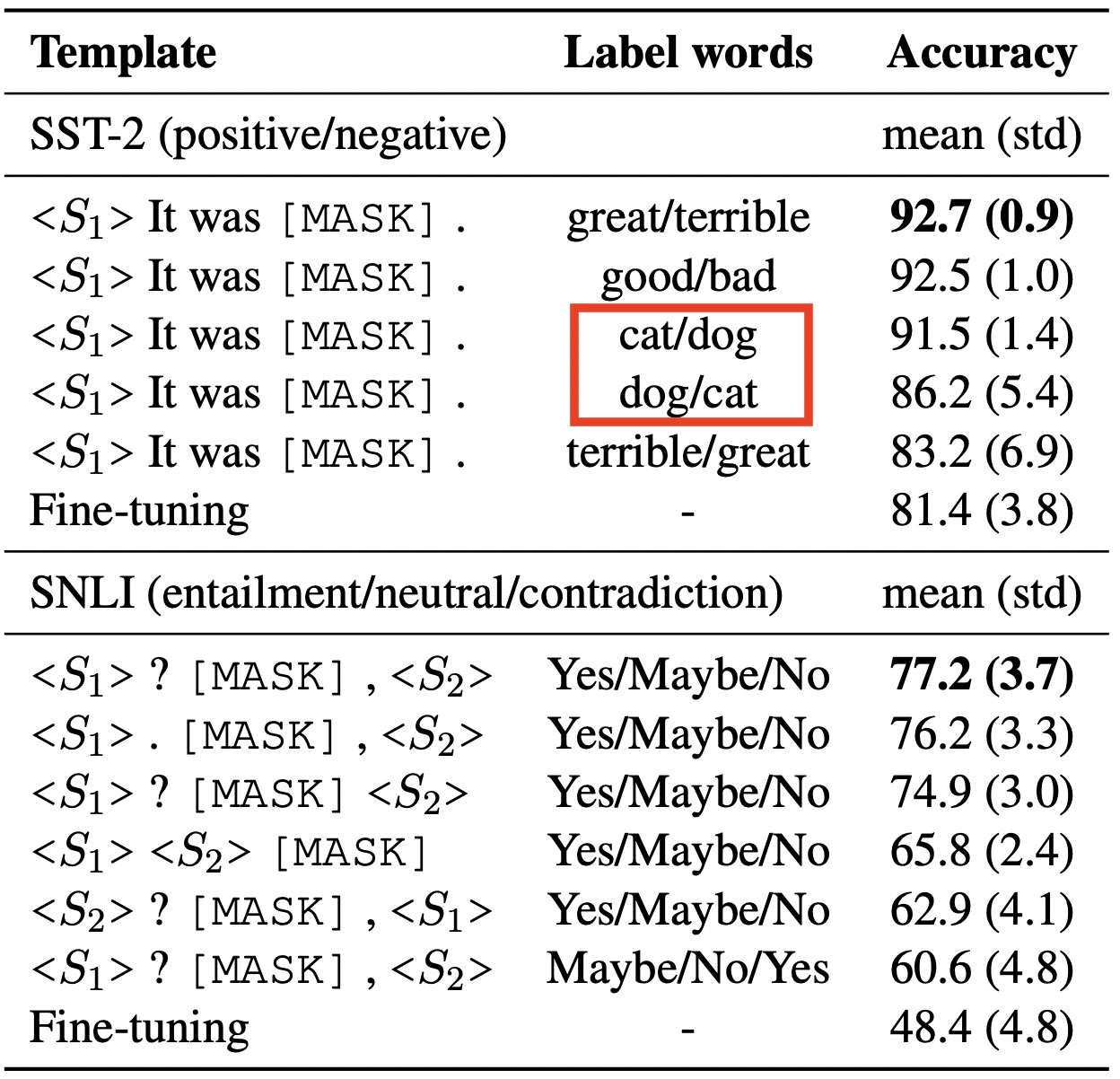
从上图我们可以看出两点:
- 使用相同的「模板」,不同的「标签词」会产生不一样的效果。例如
great/terribel和cat/dog这两组标签词的效果不一样,而且即便是相同标签词,互换顺序也会导致最终效果有所变化,例如cat/dog和dot/cat - 使用相同「标签词」,对「模板」进行小改动(例如增删标点)也会呈现不同的结果
然后就是离散prompt 和 连续prompt
离散 Prompts
这篇文章发表在 TACL 2020 讲的是如何拿预训练语言模型当作「知识库」使用 并且引入了依存树和 Paraphrase(转述)等方法来挖掘更好的「模板」 下图是实验结果

可以看到 被挖掘出来的若干「连接谓词」相比于人工设计的「模板」结果提升还是很明显的
有很多种方法可以实现 Prompt Paraphrsing 例如「回译」
然后就是(基于梯度的搜索)是由论文 AUTOPROMPT 提出的 这篇文章发表在 EMNLP 2020 它的主要思想用下面这张图就可以表示
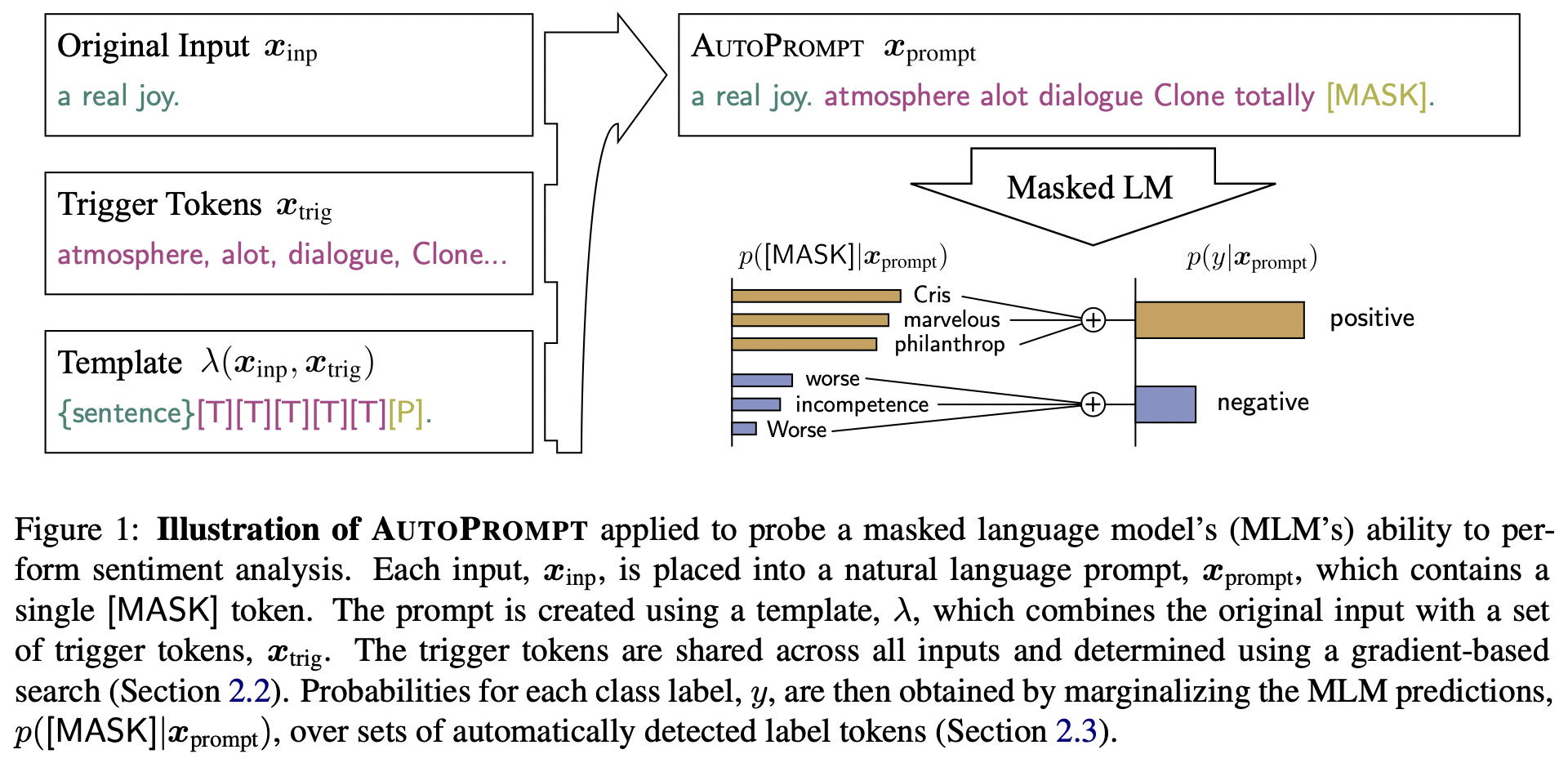
上图中 a real joy 是原始的输入句子Xinp 红色的Trigger tokens 是由Xinp[激发]的相关词汇集合Xtrig 根据Template λ 的配置 将Xtrip和Xinp组合起来构造最终的输入Xprompt 送入Masked LM 来预测情感标签 下面是论文中举的例子

Prompt Generation 是陈丹琦团队的一项工作 主要是把 Seq2Seq 预训练模型 T5 应用到模板搜索的过程 T5基于多种无监督目标进行预训练 其中最有效的一个无监督目标就是:利用 <X> 或 < Y > 替换一个或多个连续 span 然后生成对应输出 例如:
Thank you <X> me to your party <Y> week
**T5 会在 <X> 生成
for inviting
在 <Y> 生成
last
。很显然,T5 这种方式很适合生成模板,而且不需要指定模板的 token 数。具体来说,有三种可能的生成方式**
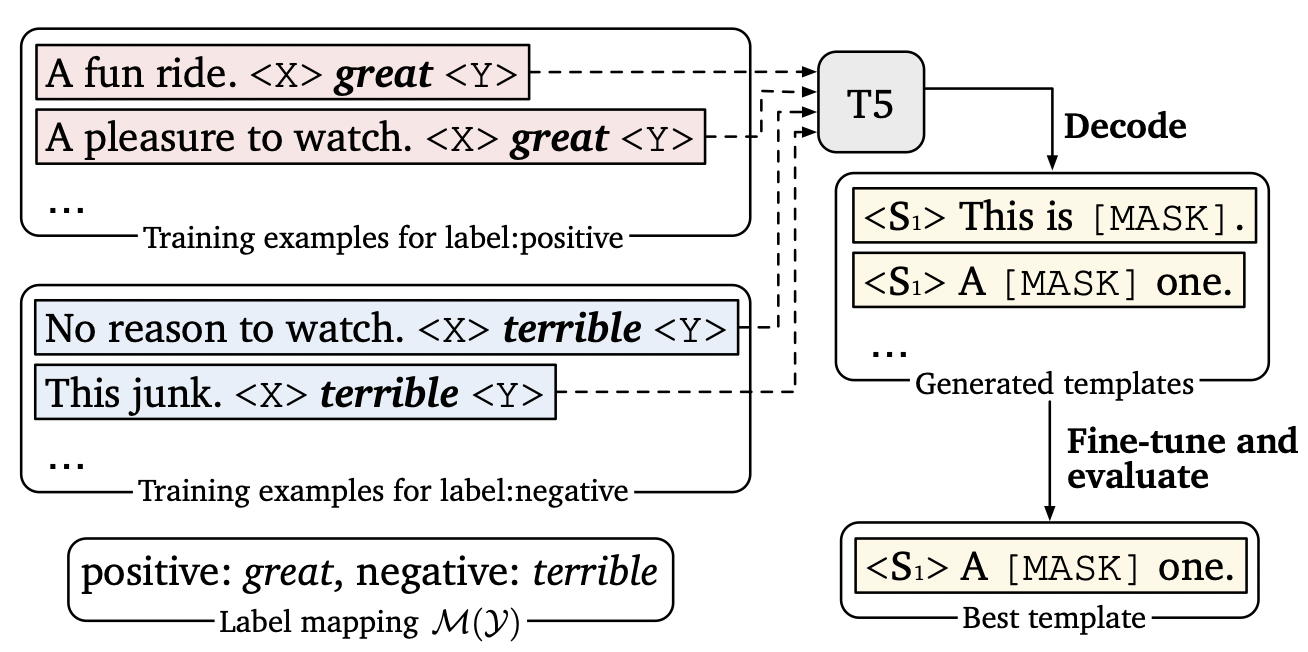
首先在标签词前后添加填充位 <X> 和 < Y>(上面提到的三种生成方式) 然后将其送入 T5 模型中 T5 会自动在填充位生成序列 最后将标签词(great 或 terribel)转换为 [MASK] 标签 形成多个模板 具体过程中采用 Beam Search 的方法生成多个候选模板 然后对每一个候选模板利用 dev 集进行微调 选择其中一个最佳模板
我还想说一下这篇论文中另外一个有意思的点 最后送入模型进行预测的句子还拼接上了每种类别的「示例」(Demonstration) 如下图所示

这种 Prompt 的设计有点像是在做语义相似度任务 X 为原始 Input 句子 已知 Y 为正例 Z 为负例 构造了如下形式的输入:
X是[MASK]例?Y为正例 Z为负例
实际上是依据下面两条规则:
- 对于每个原始输入句子,从每个类别中随机采样一个样本「示例」拼接到 Prompt 中
- 对于每个原始输入句子,在每个类别中,通过与 Sentence-BERT 进行相似度计算,从相似度最高的前 50% 样本中随机选择一个样本「示例」
连续 Prompts
构造 Prompt 的初衷是能够找到一个合适的方法 让 Pre-trained Language Model(PLM)更好地输出我们想要的结果 但其实并不一定要将 Prompt 的形式设计成人类可以理解的自然语言 只要机器理解就行了 因此 还有一些方法探索连续型 Prompts—— 直接作用到模型的 Embedding 空间 连续型 Prompts 去掉了两个约束条件 这也是最关键的两点!
- 模版中词语的 Embedding 可以是整个自然语言的 Embedding,不再只是有限的一些 Embedding
- 模版的参数不再直接取 PLM 的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整
Prefix Tuning 最开始由 Li 等人提出 这是一种在输入句子前添加一组连续型向量的方法 该方法保持 PLM 的参数不动 仅训练前缀(Prefix)向量 Prefix Tuning 的提出主要是为了做生成任务,因此它根据不同的模型结构定义了不同的 Prompt 拼接方式,在 GPT 类的 Auto-Regressive(自回归)模型上采用的是 [Prefix;x;y] 的方式,在 T5 类的 Encoder-Decoder 模型上采用的是 [Prefix;x;Prefix′;y] 的方式
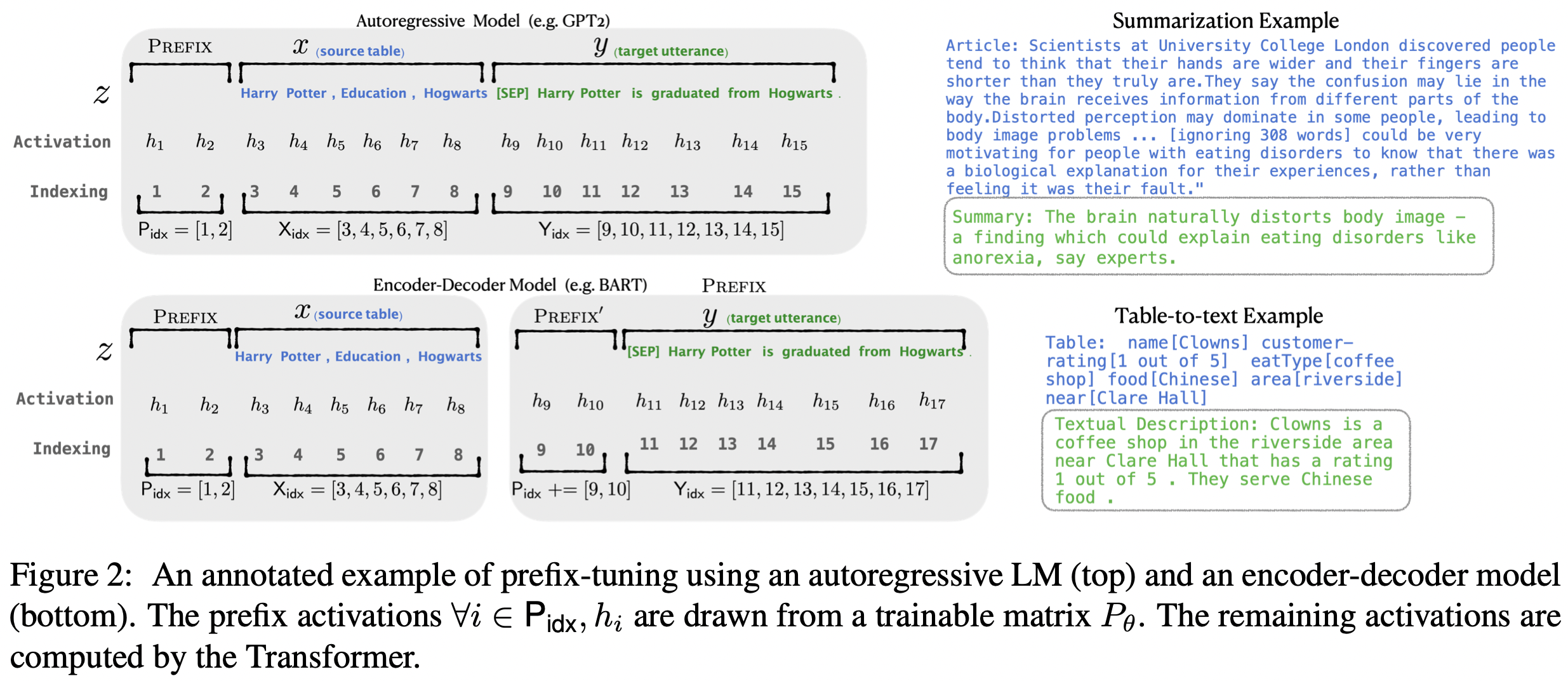
输入部分 Prefix,x,y 的 Position id 分别记作 Pidx,Xidx,Yidx。Prefix Tuning 初始化一个可训练的矩阵,记作 Pθ∈R|Pidx|×dim(hi),其中
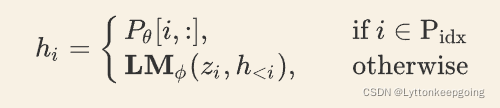
上述公式的含义是,索引 i 如果属于前缀的部分,则从 Pθ 中抽取向量;i 如果不是前缀部分,则由参数固定的预训练模型生成对应的向量。训练目标为:
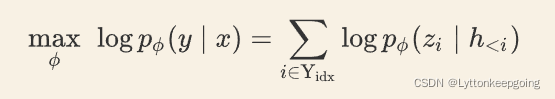
同样是在连续空间上搜索 Prompt,OptiPrompt 构建的「模板」并不局限于前缀,也可以在句子的中间

首先根据 AutoPrompt 定义一个 Prompt 模板:
[x] [v]1 [v]2 ... [v]m [MASK]
其中 [v]i 为一个连续型向量(与 BERT 的输入维度一致)。OptiPrompt 还考虑以人工构建的离散 Prompt 作为起点,在连续空间上进行搜索以构建较优的 Prompt。例如 [x] is [MASK] citizen 可以转换为[x] [v]1 [MASK] [v]2 将
is
和
citizen
对应的 input Embedding 作为 [v]1 和 [v]2 的初始化
Hard-Soft Prompt Hybrid Tuning 方法可以说是人工设计和自动学习的结合,它通常不单纯使用可学习的 Prompt 模板,而是在人工设计的模板中插入一些可学习的 Embedding。实际上有了上面的基础我们都知道,连续的 Prompt 要比离散的 Prompt 好一点,但是在此基础上还有什么改进的余地吗?Liu 等人提出的 P-Tuning 解决了 Prompt token 之间的关联性问题
之前连续的 Prompt 生成方式无非都是训练一个矩阵,然后通过索引出矩阵的某几行向量拼起来。坦白地说,我们希望这些 prompt token Embedding 之间有一个比较好的关联性,而不是独立地学习,为了解决这个问题,P-Tuning 引入了一个 Prompt Encoder(如下图 b 所示)
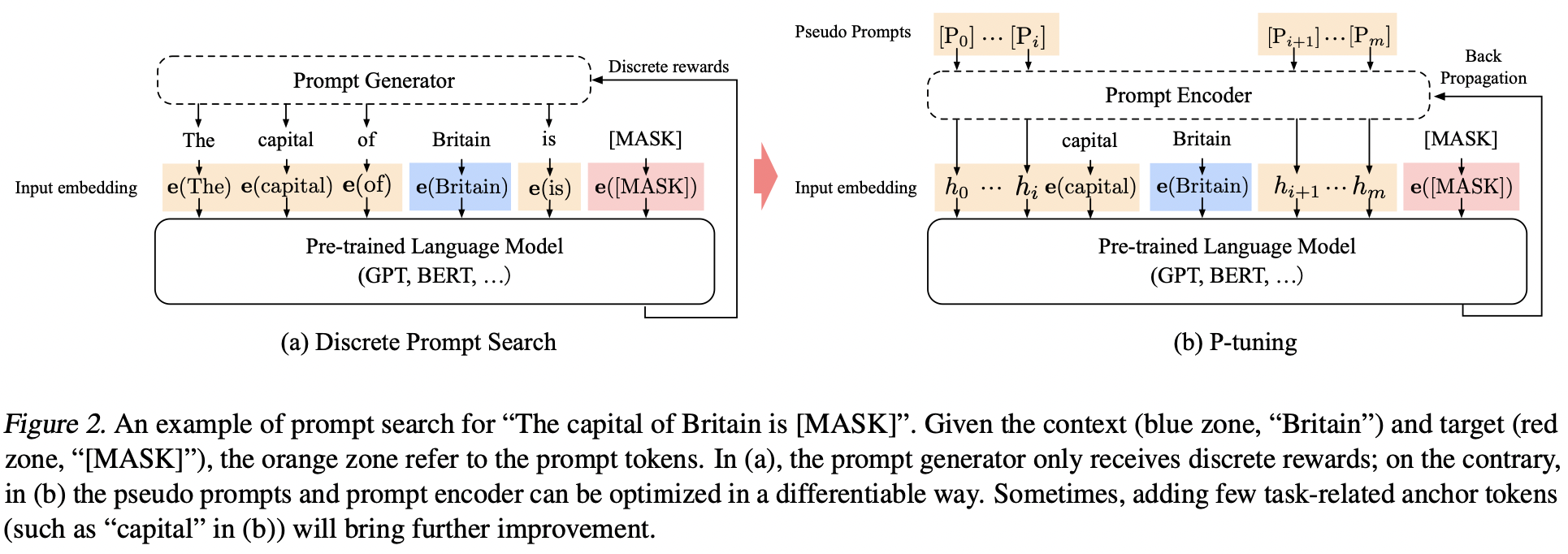
下面的数学公式我们就不多讨论了
上图 a 是传统的离散型 Prompt,我们把生成离散 Prompt token 的东西叫做 Prompt Generator;上图 b 首先传入一些 Virtual(Pseudo)token,例如 BERT 词表中的 [unused1],[unused2],... 当然,这里的 token 数目是一个超参数,插入的位置也可以调整。将这些 Pseudo token 通过一个 Prompt Encoder 得到连续的向量 h0,...,hm,其中
hi=MLP([hi→;hi←])=MLP([LSTM(h0:i):LSTM(hi:m)])
即,Prompt Encoder 是由 BiLSTM+MLP 组成的一个简单网络。作者还发现加入一些 anchor token(领域或者任务相关的 token)可以有助于 Template 的优化。例如文本蕴含任务,输入是前提和假设,判断是否蕴含。一个连续的模版是
[PRE][continuous tokens][HYP][continuous tokens][MASK]
在其中加入一个 anchor token:
[?]
效果会更好,此时模板变成
[PRE][continuous tokens][HYP]?[continuous tokens][MASK]
大家可能想问,如何优化 P-tuning?实际上根据标注数据量的多少,分两种情况讨论
- 标注数据比较少。这种情况,我们固定 PLM 的参数,只优化 [P0]∼[Pm] 这几个 token 的 Embedding。换句话说,我们只是要更新 Prompt Encoder 的参数
- 标注数据很充足。这种情况直接放开所有参数微调
就在 P-Tuning 方法提出不久后,Liu 等人又提出了 P-Tuning v2,主要解决 P-Tuning 的两个问题:
- 当预训练模型的参数量低于 100 亿(10B)时,Prompt tuning 会比传统的 Fine-tuning 差
- 诸如序列标注这样对推理和理解要求高的任务,prompt tuning 效果会变差
Liu 等人认为先前的 P-Tuning 只用了一层 BiLSTM 来编码 Pseudo token,这是其推理能力不足的原因之一,因此 v2 版本提出 Deep Prompt Tuning,用 Prefix Tuning 中的深层模型替换 BiLSTM,如下图所示
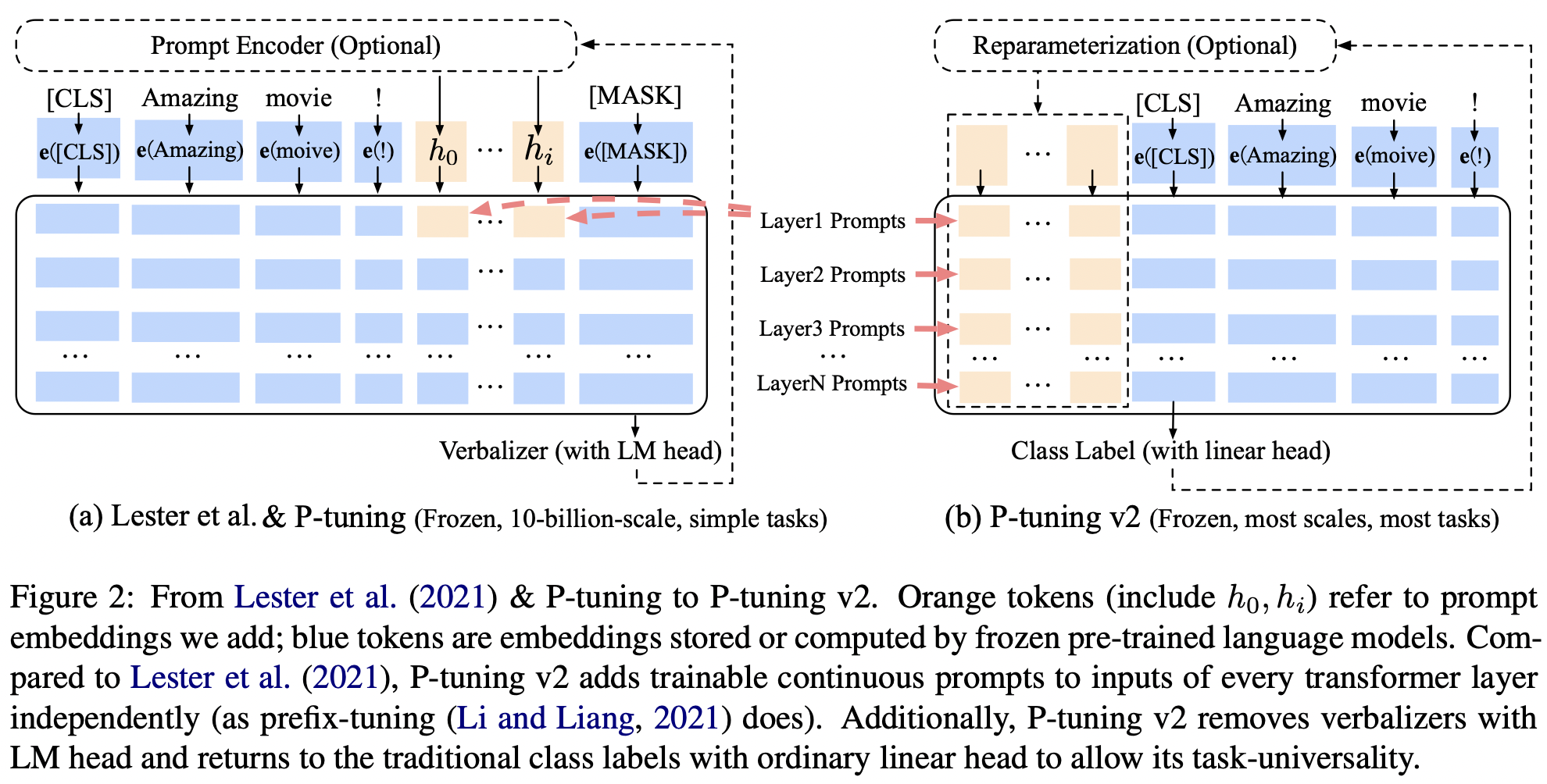
P-Tuning v2 相比于 P-Tuning,区别在于:
取消 Reparameterization:以前的方法利用重参数化功能来提高训练速度和鲁棒性(例如,用于 Prefix-Tuning 的 MLP 和用于 P-Tuning 的 LSTM)。在 P-Tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现
Multi-task Learning:Deep Prompt Tuning 的优化难题可以通过增加额外的任务数据或者无标注数据来缓解,同时可微调的 Prefix Continuous Prompt 也可以用来做跨任务的知识共享。例如在 NER 中,可以同时训练多个数据集,不同数据集使用不同的顶层 Classifier,但是 Prefix Continuous Prompt 是共享的
取消 verbalizer:v2 取消了标签映射,完全变为生成模型,可以在 [CLS] 部分输出句子级别的标签(Sentence-level label),也可以在每个 token 位置输出 token 级别的标签(Token-level label),直接输出真实标签
这里说一下我的理解:
首先是 v1 版本的 LSTM 实际上引入 LSTM 目的是为了帮助「模板」生成的 token(某种程度上)更贴近自然语言 或者说 token 之间的语义更流畅 但更自然的方法应该是在训练下游任务的时候 不仅预测下游任务的目标 token(例如 great terrible),还应该同时做其他 token 的预测
比如 如果是 MLM 模型 那么也随机 MASK 掉其它的一些 token 来预测 如果是 LM 模型 则预测完整的序列 而不单单是目标词 这样做的理由是:因为我们的 MLM/LM 都是经过自然语言预训练的 所以我们认为它能够很好的完成序列的重构 即便一开始不能 随着迭代轮数的增加 模型也能很好完成这项任务 所以这本质上是让模型进行「负重训练」
最后一个点
为什么要引入 Prompt?
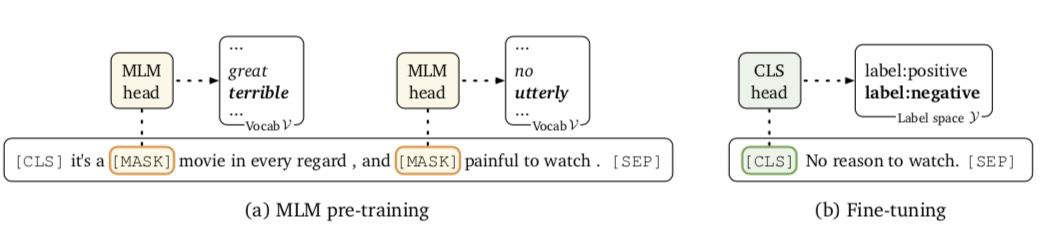
在标准的 Fine-tune 过程中(如上图 b 所示) 新引入的参数量可能会很大(独立于原始预训练模型外的参数) 例如基于 RoBERTa-large 的二分类任务会新引入 2048 个参数(1024, 2)如果你仅有例如 64 个标注数据这样的小样本数据集 微调就会非常困难
为解决这一问题 Prompt 应运而生(如上图 a 所示) 直接将下游任务转换为输出空间有限的 MLM 任务 但是上述方法在预训练参数的基础上进行微调 并且没有引入任何新参数 同时还减少了微调和预训练任务之间的差距 总的来说 这可以更有效地用于小样本场景
tips:上述提到的论文我基本上都提供了超链接 如果还想了解更多细节可以阅读原作者论文//
版权归原作者 Lyttonkeepgoing 所有, 如有侵权,请联系我们删除。