如何计算神经网络参数的个数?
神经网络随着层数的加深,网络参数的个数会越来越多,小的网络有成千上万个参数,大的可以达到千万个网络参数。这里我们介绍一下如何计算神经网络参数的个数图像分类的神经网络,包含两个部分:特征提取层+ 分类层特征提取层就是将提取图像中的特征,这里的特征就是图像的细节,例如边缘、关键点等等。类似于人在识别物体
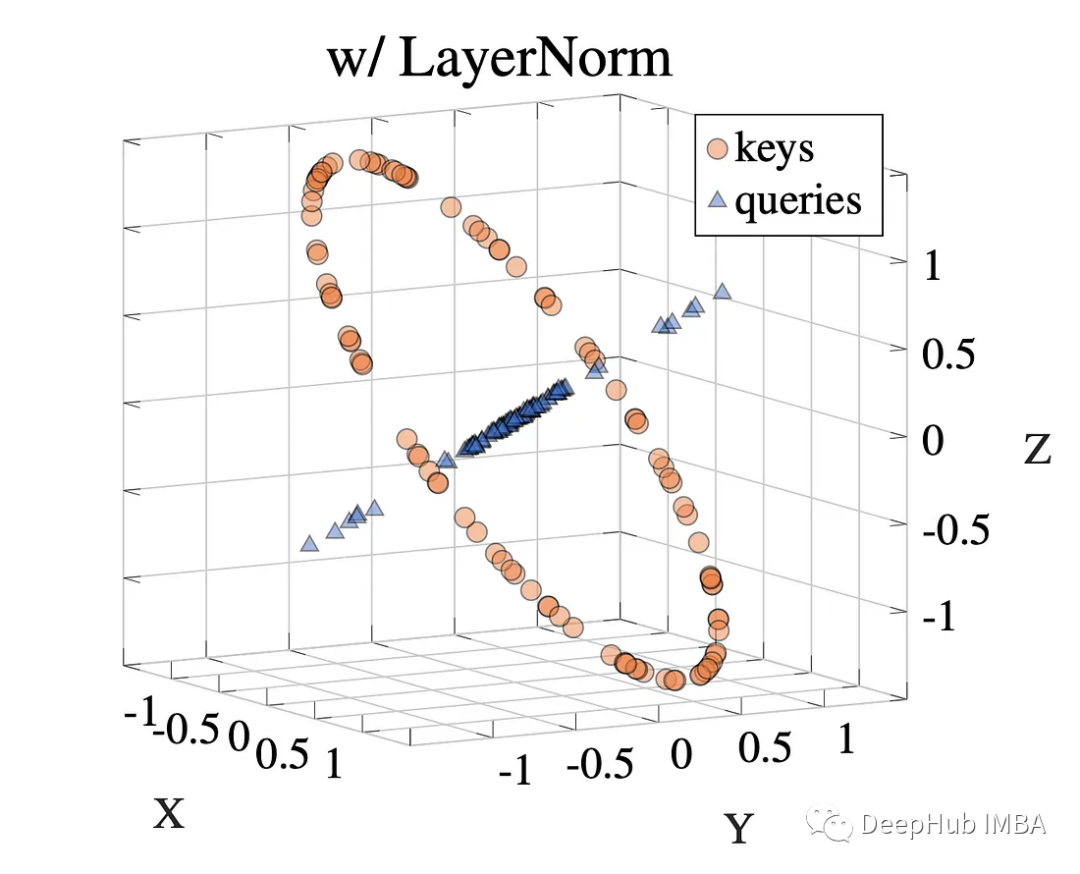
LayerNorm 在 Transformers 中对注意力的作用研究
LayerNorm 一直是 Transformer 架构的重要组成部分。如果问大多人为什么要 LayerNorm,一般的回答是:使用 LayerNorm 来归一化前向传播的激活和反向传播的梯度。
什么是预训练模型?
什么是预训练模型?
forward函数——浅学深度学习框架中的forward
forward函数是深度学习框架中常见的一个函数,用于定义神经网络的前向传播过程。在训练过程中,输入数据会被传入神经网络的forward函数,然后经过一系列的计算和变换,最终得到输出结果。具体来说,forward函数的作用是将输入数据经过网络中各个层的计算和变换后,得到输出结果。在forward函数

视觉大模型DINOv2:自我监督学习的新领域
本文将介绍DINOv2是如何改进的,以及这些进步可能对整个领域有什么影响。
Topsis算法实践:比较LSTM算法与BP神经网络算法,以chickenpox_dataset为例
本文用Topsis算法以chickenpox_dataset为例比较LSTM算法与BP神经网络算法,发现LSTM算法预测相比与BP神经网络预测结果并不理想,希望得到解释。
强化学习——多智能体强化学习
文章目录前言多智能体系统的设定合作关系设定下的多智能体系统策略学习的目标函数合作关系下的多智能体策略学习算法MAC-A2C前言本文总结《深度强化学习》中的多智能体强化学习相关章节,如有错误,欢迎指出。多智能体系统的设定多智能体系统包含有多个智能体,多个智能体共享环境,智能体之间相互影响。一个智能体的
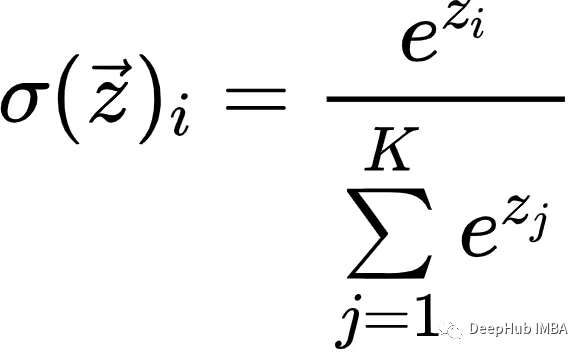
Softmax简介
Softmax是一种数学函数,通常用于将一组任意实数转换为表示概率分布的实数。
基于随机森林的特征选择-降维-回归预测——附代码
可以看到,使用两个特征进行预测的准确度为85.2077,与使用所有特征进行预测的准确度相差不大,这表明随机森林特征选择方法有效的选择出了最重要的特征,实现了从大量特征到少数重要特征的特征降维筛选,极大的降低了特征的冗余性。当随机森林评价完成特征的重要性后,还需要对各个特征变量之间的相关性进行评估,以
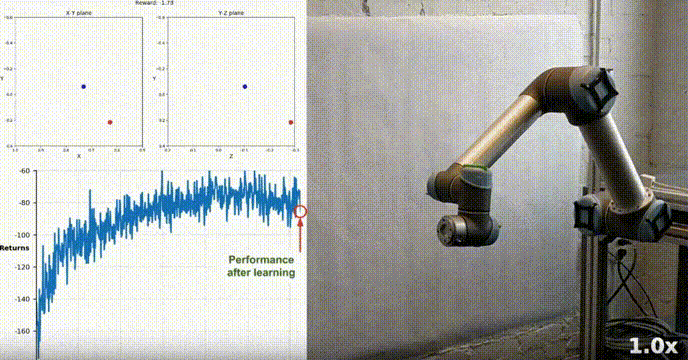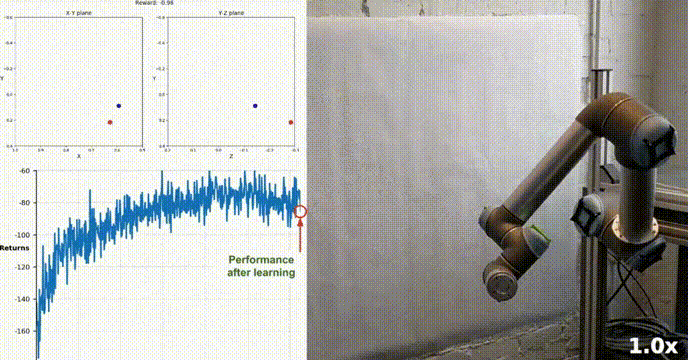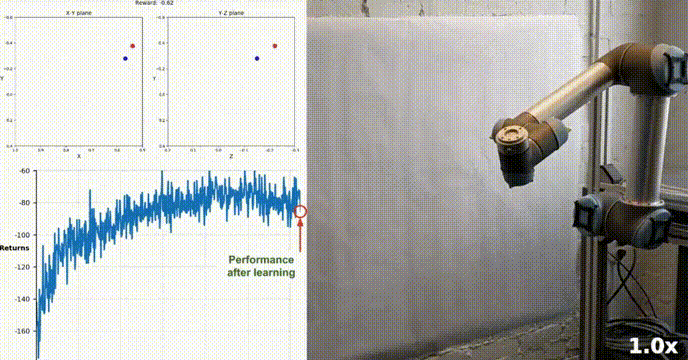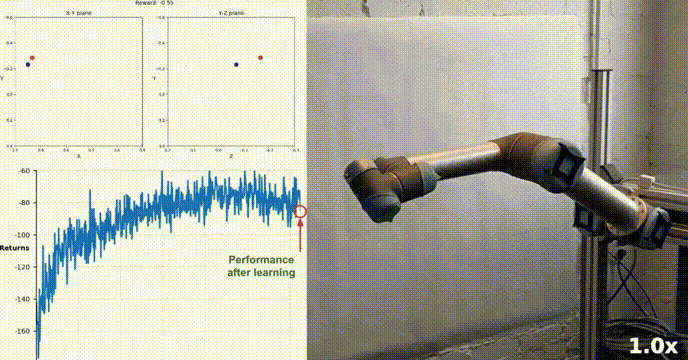
使用Actor-Critic的DDPG强化学习算法控制双关节机械臂
在本文中,我们将介绍在 Reacher 环境中训练智能代理控制双关节机械臂
语义分割系列15-UPerNet(pytorch实现)
本文介绍了UPerNet论文思想,介绍了UPerNet作者如何创建Multi-task数据集以及如何设计UPerNet网络和检测头来解决Multi-task任务。本文对于UPerNet语义分割部分的模型进行单独复现,所有代码基于pytorch框架,并在Camvid数据集上进行训练和测试。......
使用LSTM预测结果为一条直线原因总结
使用LSTM预测结果为一条直线原因总结
优化改进YOLOv5算法之添加SE、CBAM、CA模块(超详细)
本文主要是在YOLOv5算法中加入SE、CBAM和CA注意力机制模块,通过实验验证对比,加入CBAM和CA注意力机制后的效果均有所提升
四种类型自编码器AutoEncoder理解及代码实现
慢慢的会设计自己的编码器和解码器。全部都将其搞定都行啦的回事与打算。慢慢的全部都将其搞定都行啦的回事与打算。
chatgpt3接口 国内版免费使用
目前OpenAI公司提供了GPT-3的API服务,允许开发者通过调用API接口,使用GPT-3的功能。总的来说,GPT-3的API接口是一个非常方便和高效的自然语言处理工具,可以帮助您快速解决自然语言处理问题,例如生成文本、回答问题等任务。但需要注意的是,API使用需要遵从OpenAI公司的相关规定
Torch 模型 onnx 文件的导出和调用
OpenNeuralNetworkExchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移Torch所定义的模型为动态图,其前向传播是由类方法定义和实现的但是Python代码的效率是比较底下的,试想把动态图转化为静态图,模型的推理速度应当有
BP神经网络
BP(Back Propagation) 算法是神经网络深度学习中最重要的算法之一,了解BP算法可以让我们更理解神经网络深度学习模型训练的本质,属于内功修行的部分。
NLP自然语言处理简介
NLP自然语言处理简介
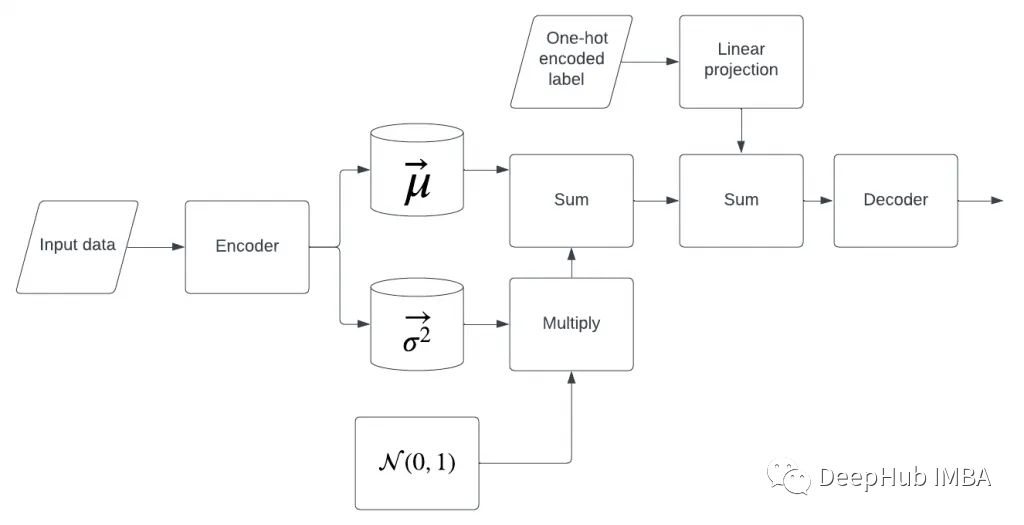
从零开始实现VAE和CVAE
扩散模型可以看作是一个层次很深的VAE(变分自编码器)本文将用python从头开始实现VAE和CVAE,来增加对于它们的理解。
图注意力网络——Graph attention networks (GAT)
文章目录摘要引言摘要 图注意力网络,一种基于图结构数据的新型神经网络架构,利用隐藏的自我注意层来解决之前基于图卷积或其近似的方法的不足。通过堆叠层,节点能够参与到邻居的特征,可以(隐式地)为邻域中的不同节点指定不同的权值,而不需要任何代价高昂的矩阵操作(如反转),也不需要预先知道图的结构。通过这种



