【网络结构设计】11、E-LAN | 通过梯度传输路径来设计网络结构
本文主要介绍 E-LAN
数据挖掘(6.1)--神经网络
神经网络是一种计算模型,它受到人脑处理信息的生物神经网络过程的启发。人工神经网络(ANN)一般也称为神经网络(Neural Network,NN)。神经网络是由多个神经元组成的,每个神经元都有一个输入和一个输出,它们之间通过权重进行连接。当输入数据经过多个神经元后,输出结果就是由这些神经元的输出加权
【模型+代码/保姆级教程】使用Pytorch实现手写汉字识别
保姆级教程,手把手用Pytorch搭建神经网络,识别3755类手写汉字,模型参数、项目完整源码、预处理数据集全部公开。
技术干货 | 一文弄懂差分隐私原理!
图1 随机算法在邻近数据集上的概率差分隐私有两个重要的优点:差分隐私假设攻击者能够获得除目标记录以外的所有其他记录信息,这些信息的总和可以理解为攻击者能够掌握的最大背景知识,在这个强大的假设下,差分隐私保护无需考虑攻击者所拥有的任何可能的背景知识。差分隐私建立在严格的数学定义上,提供了可量化评估的方

谷歌发布一个免费的生成式人工智能课程
谷歌推出了一个生成式人工智能学习课程,课程涵盖了生成式人工智能入门、大型语言模型、图像生成等主题。
【人工智能】期末复习 重点知识点总结
人工智能期末复习考点
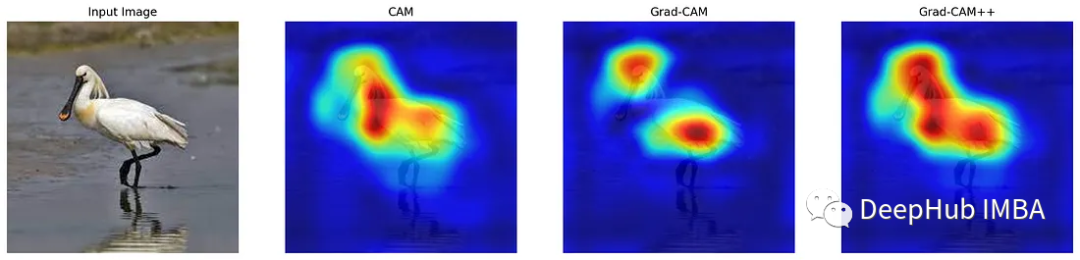
CAM, Grad-CAM, Grad-CAM++可视化CNN方式的代码实现和对比
理解CNN的方法主要有类激活图(Class Activation Maps, CAM)、梯度加权类激活图(Gradient Weighted Class Activation Mapping, Grad-CAM)和优化的 Grad-CAM( Grad-CAM++)。
煤炭行业生命周期分析,煤炭行业周期性特征
一、价值分析影响股价的长期走势产出和投入之比所形成的价值,即通过价值思维的分析,判断出的股价的产出与投入比,决定着股价的长期走势,二、基本面分析影响股价的中期走势基本面分析即宏观经济的分析,也就是经济形势的好坏,增长速度的高低、快慢,影响整个宏观经济发展的运行态势技术分析是对于股价的长期上涨和下跌所
【代码复现】5秒训练NeRF!英伟达instan-ngp在windows成功复现
主要介绍了在WINDOWS10下运行instant-ngp的方法,并且介绍了自定义数据集创建和运行的方法。
机器学习题目汇总
机器学习题目
【数据分类】GRNN数据分类 广义回归神经网络数据分类【Matlab代码#30】
GRNN数据分类 广义回归神经网络数据分类
DHVT:在小数据集上降低VIT与卷积神经网络之间差距,解决从零开始训练的问题
VIT在归纳偏置方面存在空间相关性和信道表示的多样性两大缺陷。所以论文提出了动态混合视觉变压器(DHVT)来增强这两种感应偏差。在空间方面,采用混合结构,将卷积集成到补丁嵌入和多层感知器模块中,迫使模型捕获令牌特征及其相邻特征。在信道方面,引入了MLP中的动态特征聚合模块和多头注意力模块中全新的“”
卷积神经网络每一层输出的形状、通道数、特征图数量以及过滤器数量的理解与计算。
卷积神经网络中的一些易混淆概念
BP神经网络原理
BP神经网络(Back Propagation Neural Network)是一种基于误差反向传播算法(Back Propagation Algorithm)的人工神经网络,也是应用最广泛的神经网络之一。它可以用来解决分类、回归、模式识别、数据挖掘等多种问题。BP神经网络由输入层、隐层和输出层组成
CNN经典网络模型(三):VGGNet简介及代码实现(PyTorch超详细注释版)
CNN经典网络模型之一:VGGNet,本文包含其简介及代码,在PyTorch中实现,进行超详细注释,适合新生小白阅读学习~

七篇深入理解机器学习和深度学习的读物推荐
在这篇文章中将介绍7篇机器学习和深度学习的论文或者图书出版物,这些内容都论文极大地影响了我对该领域的理解,如果你想深入了解机器学习的内容,哪么推荐阅读。
人工智能神经网络概念股,神经网络芯片概念股
人工智能包含硬件智能、软件智能和其他。硬件智能包括:汉王科技、康力电梯、慈星股份、东方网力、高新兴、紫光股份。软件智能包括:金自天正、科大讯飞。其他类包括:中科曙光、京山轻机。谷歌人工智能写作项目:小发猫1、苏州科达:苏州科达科技股份有限公司是领先的视讯与安防产品及解决方案提供商,致力于以视频会议、
机器学习特征重要性分析
特征选择
基于MindSpore复现UNet—语义分割
U-Net: Convolutional Networks for Biomedical Image Segmentation
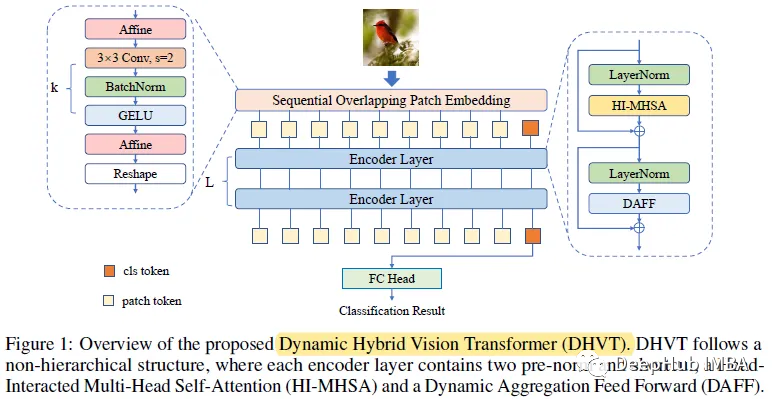
DHVT:在小数据集上降低VIT与卷积神经网络之间差距,解决从零开始训练的问题
VIT在归纳偏置方面存在空间相关性和信道表示的多样性两大缺陷。所以论文提出了动态混合视觉变压器(DHVT)来增强这两种感应偏差。



