
Diffusion-GAN: 将GAN与diffusion一起训练
paper:https://arxiv.org/abs/2206.02262
code:GitHub - Zhendong-Wang/Diffusion-GAN: Official PyTorch implementation for paper: Diffusion-GAN: Training GANs with Diffusion
第一行从左向右看是diffusion forward的过程,不断由 real image 进行 diffusion,第三行从右向左看是由noise逐步恢复成fake image的过程,第二行是鉴别器D,D对每一个timestep都进行鉴别。
Figure 1: Flowchart for Diffusion-GAN. The top-row images represent the forward diffusion process of a real image, while the bottom-row images represent the forward diffusion process of a generated fake image. The discriminator learns to distinguish a diffused real image from a diffused fake image at all diffusion steps.
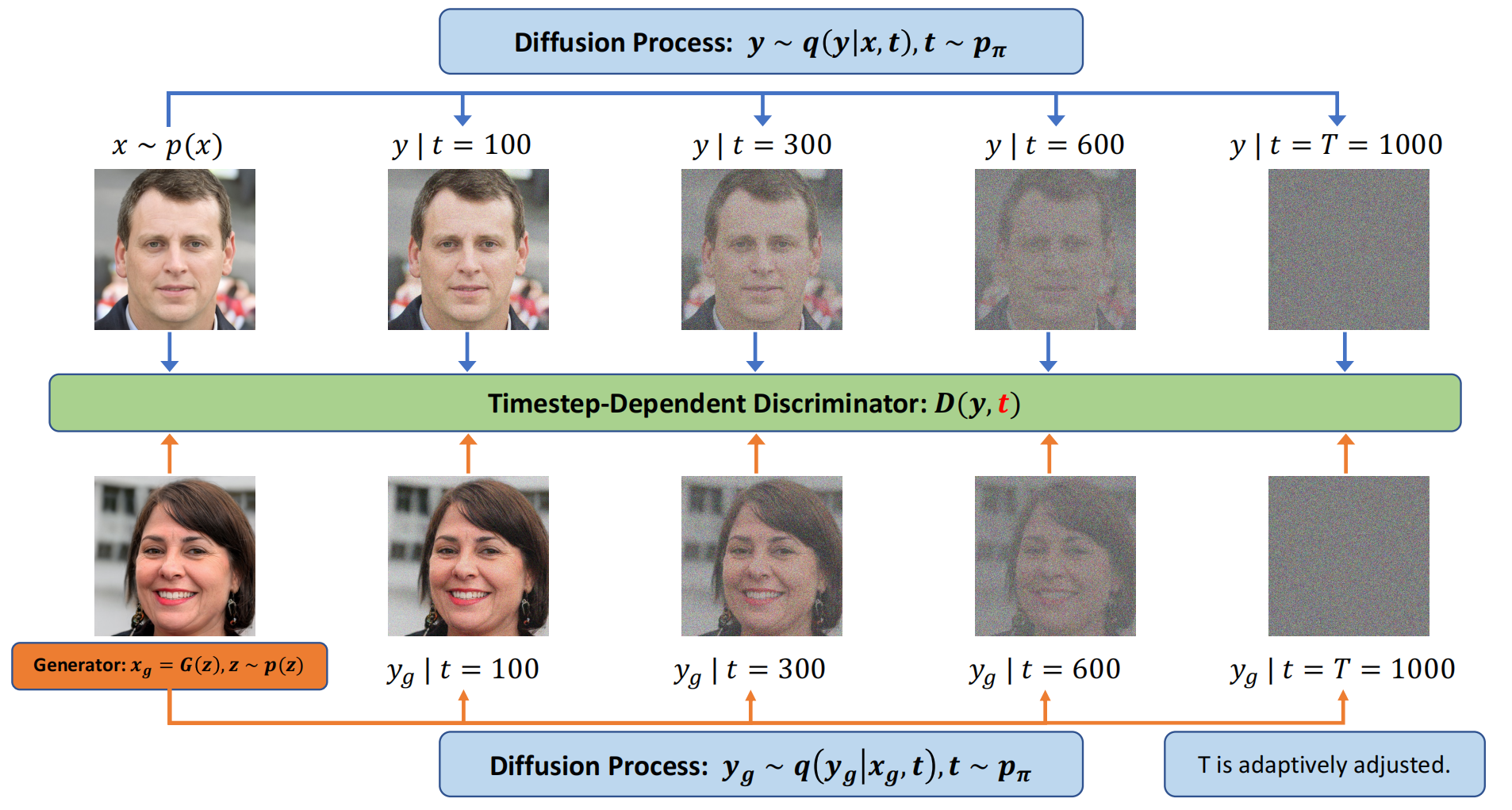
in Figure 1. In Diffusion-GAN, the input to the diffusion process is either a real or a generated image, and the diffusion process consists of a series of steps that gradually add noise to the image. The number of diffusion steps is not fixed, but depends on the data and the generator. We also design the diffusion process to be differentiable, which means that we can compute the derivative of the output with respect to the input. This allows us to propagate the gradient from the discriminator to the generator through the diffusion process, and update the generator accordingly. Unlike vanilla GANs, which compare the real and generated images directly, Diffusion-GAN compares the noisy versions of them, which are obtained by sampling from the Gaussian mixture distribution over the diffusion steps, with the help of our timestep-dependent discriminator. This distribution has the property that its components have different noise-to-data ratios, which means that some components add more noise than others. By sampling from this distribution, we can achieve two benefits: first, we can stabilize the training by easing the problem of vanishing gradient, which occurs when the data and generator distributions are too different; second, we can augment the data by creating different noisy versions of the same image, which can improve the data efficiency and the diversity of the generator. We provide a theoretical analysis to support our method, and show that the min-max objective function of Diffusion-GAN, which measures the difference between the data and generator distributions, is continuous and differentiable everywhere. This means that the generator in theory can always receive a useful gradient from the discriminator, and improve its performance.【G可以从D收到有用的梯度,从而提升G的性能】
主要贡献:
- We show both theoretically and empirically how the diffusion process can be utilized to provide a model- and domain-agnostic differentiable augmentation, enabling data-efficient and leaking-free stable GAN training.【稳定了GAN的训练】
- Extensive experiments show that Diffusion-GAN boosts the stability and generation performance of strong baselines, including StyleGAN2 , Projected GAN , and InsGen , achieving state-of-the-art results in synthesizing photo-realistic images, as measured by both the Fréchet Inception Distance (FID) and Recall score.【diffusion提升了原始只有GAN组成的框架的性能,例如styleGAN2,Projected GAN】
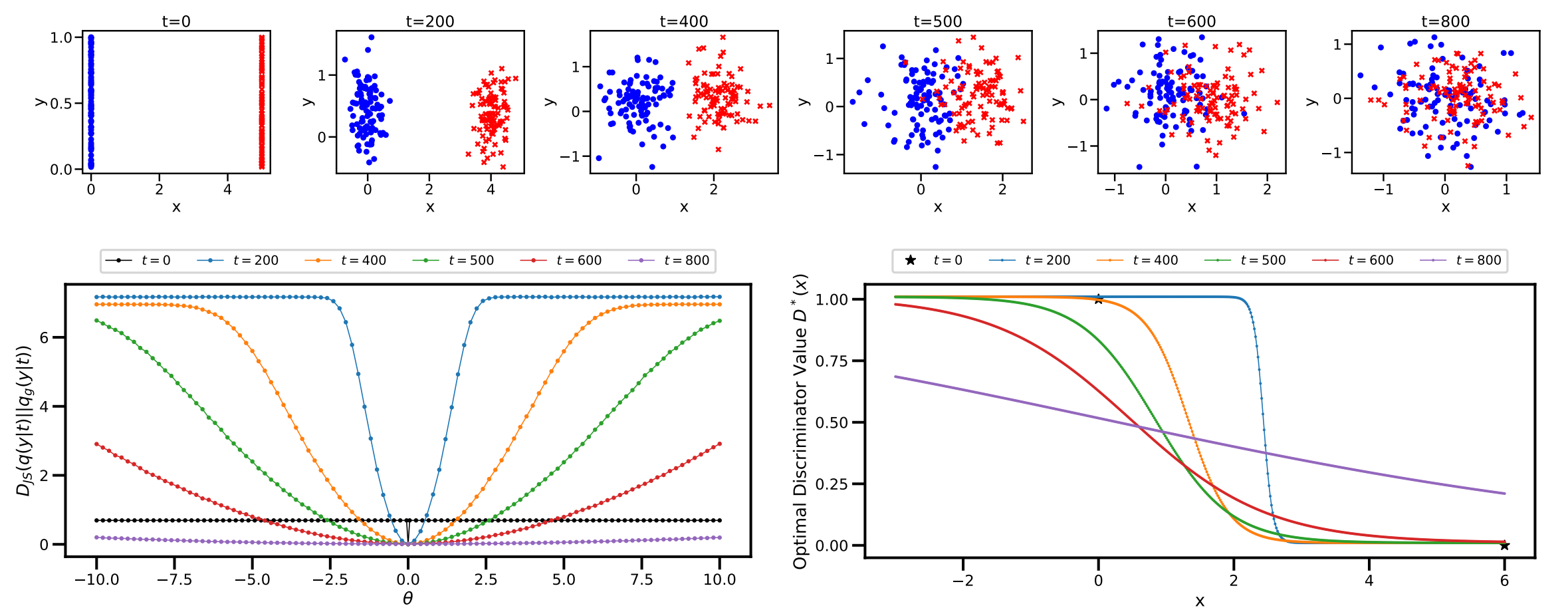
Figure 2: The toy example inherited from Arjovsky et al. [2017]. The first row plots the distributions of data with diffusion noise injected for t. The second row shows the JS divergence and the optimal discriminator value with and without our noise injection.
Figure 4: Plot of adaptively adjusted maximum diffusion steps T and discriminator outputs of Diffusion-GANs.
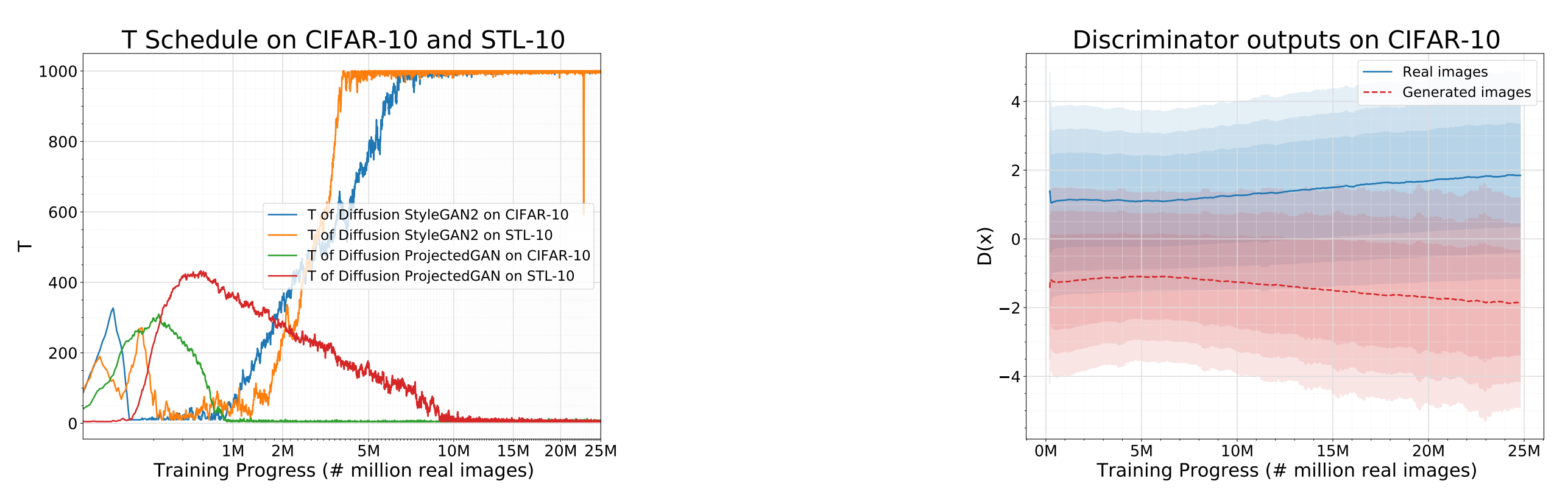
To investigate how the adaptive diffusion process works during training, we illustrate in Figure 4 the convergence of the maximum timestep T in our adaptive diffusion and discriminator outputs.
We see that T is adaptively adjusted: The T for Diffusion StyleGAN2 increases as the training goes while the T for Diffusion ProjectedGAN first goes up and then goes down. Note that the T is adjusted according to the overfitting status of the discriminator. The second panel shows that trained with the diffusion-based mixture distribution, the discriminator is always well-behaved and provides useful learning signals for the generator, which validates our analysis in Section 3.4 and Theorem 1.
如图4左所示,随着训练过程的变化,扩散的timestep T也会自适应的改变(T通过鉴别器D过拟合的状态而改变);
如图4右所示,用基于扩散的混合分布训练的鉴别器总是表现良好,并为生成器G提供有用的学习信号。
Effectiveness of Diffusion-GAN for domain-agnostic augmentation(未知域增强的有效性)
25-Gaussians Example.
We conduct experiments on the popular 25-Gaussians generation task. The 25-Gaussians dataset is a 2-D toy data, generated by a mixture of 25 two-dimensional Gaussian distributions. Each data point is a 2-dimensional feature vector. We train a small GAN model, whose generator and discriminator are both parameterized by multilayer perceptrons (MLPs), with two 128-unit hidden layers and LeakyReLu nonlinearities.
Figure 5: The 25-Gaussians example. We show the true data samples, the generated samples from vanilla GANs, the discriminator outputs of the vanilla GANs, the generated samples from our Diffusion-GAN, and the discriminator outputs of Diffusion-GAN.

(1)groundtruth数据集的数据分布,在25个Gaussians example均匀分布;
(2)vanilla GANs的输出结果产生了mode collapsing,只在几个model上生成数据;
(3)vanilla GANs鉴别器输出很快就会彼此分离。这意味着发生了鉴别器的强烈过拟合,使得鉴别器停止为发生器提供有用的学习信号。
(4)Diffusion-GAN在25个example上均匀分布,意味着它在所有的model上学到了采样分布;
(5)Diffusion-GAN的鉴别器输出,D在持续的为G提供有用的学习信号
我们从两个角度来解释这种改进:
首先,non-leaking augmentation(无泄漏增强)有助于提供关于数据空间的更多信息;第二,自适应调整的基于扩散的噪声注入,鉴别器表现良好。
关于 Difffferentiable augmentation. (可微分增强)
As Diffusion-GAN transforms both the data and generated samples before sending them to the discriminator, we can also relate it to differentiable augmentation proposed for data-efficient GAN training. Karras et al introduce a stochastic augmentation pipeline with 18 transformationsand develop an adaptive mechanism for controlling the augmentation probability. Zhao et al. [2020] propose to use Color + Translation + Cutout as differentiable augmentations for both generated and real images.
While providing good empirical results on some datasets, these augmentation methods are developed with domain-specific knowledge and have the risk of leaking augmentation into generation [Karras et al., 2020a]. As observed in our experiments, they sometime worsen the results when applied to a new dataset,** likely because the risk of augmentation leakage overpowers the benefits of enlarging the training set, which could happen especially if the training set size is already sufficiently large**.(在数据量足够大的情况下,数据增强带来的负面效果可能大于正面效果)
By contrast, Diffusion-GAN uses a differentiable forward diffusion process to stochastically transform the data and can be considered as both a domain-agnostic and a model-agnostic augmentation method. In other words, Diffusion-GAN can be applied to non-image data or even latent features, for which appropriate data augmentation is difficult to be defined, and easily plugged into an existing GAN to improve its generation performance. Moreover, we prove in theory and show in experiments that augmentation leakage is not a concern for Diffusion-GAN. Tran et al. [2021] provide a theoretical analysis for deterministic non-leaking transformation with differentiable and invertible mapping functions. Bora et al. [2018] show similar theorems to us for specific stochastic transformations, such as Gaussian Projection, Convolve+Noise, and stochastic Block-Pixels, while our Theorem 2 includes more satisfying possibilities as discussed in Appendix B.
版权归原作者 马鹏森 所有, 如有侵权,请联系我们删除。