

01、实例:DIEN 模拟兴趣演化的序列网络
深度兴趣演化网络(Deep Interest Evolution Network,DIEN)是阿里巴巴团队在2018年推出的另一力作,比DIN 多了一个Evolution,即演化的概念。
在DIEN 模型结构上比DIN 复杂许多,但大家丝毫不用担心,我们将DIEN 拆解开来详细地说明。首先来看从DIEN 论文中截下的模型结构图,如图1所示。
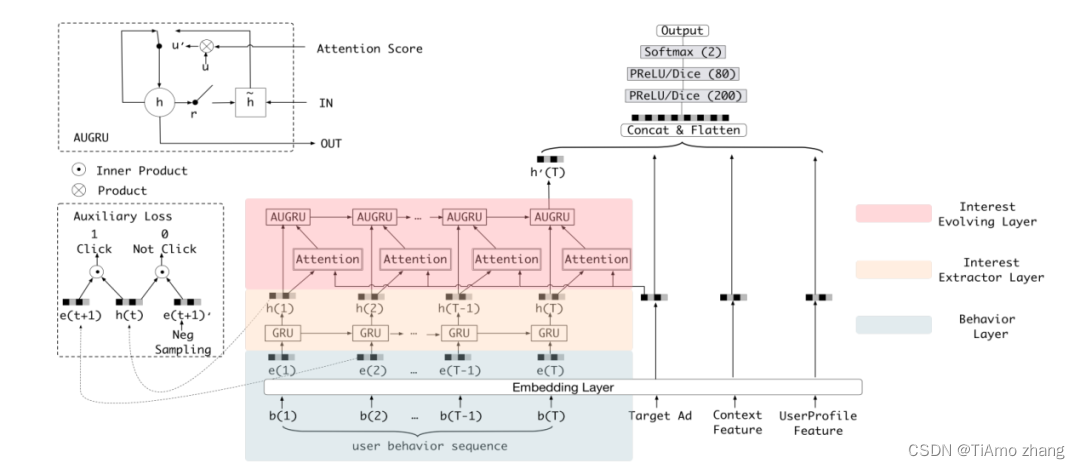
■ 图1 DIEN模型结构全图
这张图初看之下很复杂,但可从简单到难一点点来说明。首先最后输出往前一段的截图如图2所示。
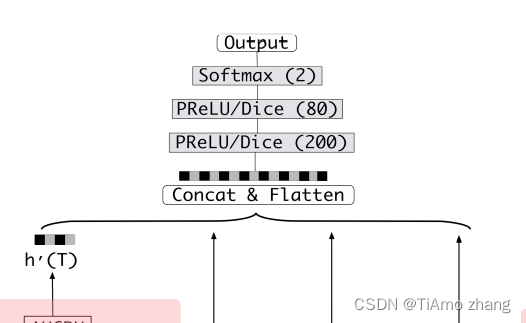
■ 图2 DIEN模型结构局部图(1)
这部分很简单,是一个MLP,下面一些箭头表示经过处理的向量。这些向量会经一个拼接层拼接,然后经几个全连接层,全连接层的激活函数可选择PReLU 或者Dice。最后用了一个Softmax(2)表示二分类,当然也可用Sigmoid进行二分类任务。
对输出端了解过后,再来看输入端,将输入端的部分放大后截图如图3所示。
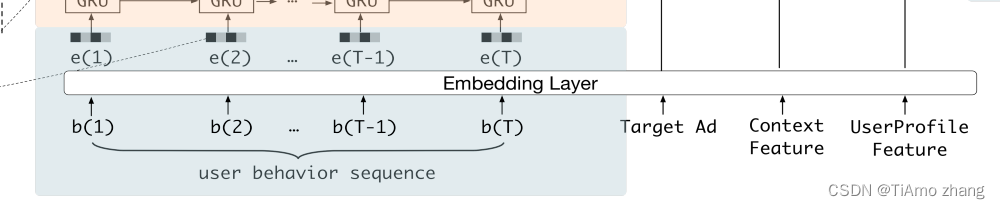
■ 图3 DIEN模型结构局部图(2)
从右往左看,UserProfile Feature 指用户特征,Context Feature指内容特征,Target Ad指目标物品,其实这3个特征表示的无非是随机初始化一些向量,或者通过特征聚合的方式量化表达各种信息。
DIEN 模型的重点就在图3的user behavior sequence区域。user behavior sequence代表用户行为序列,通常利用用户历史交互的物品代替。图4展示了这块区域的全貌。
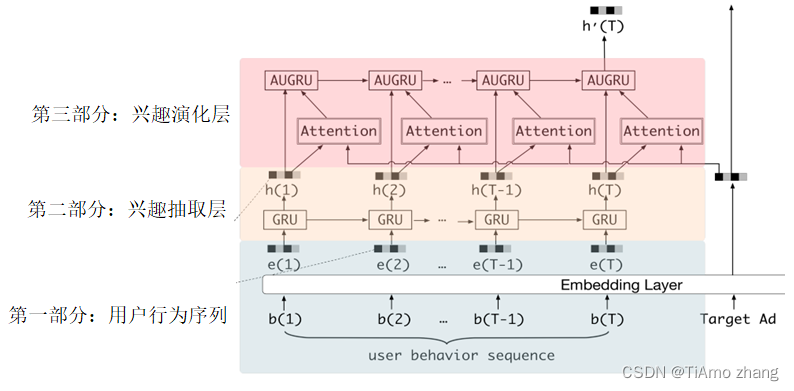
■ 图4 DIEN模型结构局部图(3)
这部分是DIEN 算法的核心:
第一部分: 用户行为序列,是将用户历史交互的物品序列经Embedding层初始化物品序列向量准备输入下一层,代码如下:
#recbyhand\chapter3\s34_DIEN.py
#初始化embedding
items = nn.Embedding( n_items, dim, max_norm = 1 )
#[batch_size, len_seqs, dim]
item_embs = items(history_seqs)#history_seqs指用户历史物品序列id
所以输出的是一个[批次样本数量,序列长度,向量维度]的张量。
第二部分: 兴趣抽取层,是一个GRU 网络,将上一层的输出在这一层输入。GRU 是RNN 的一个变种,在PyTorch里有现成模型,所以只有以下两行代码。
#recbyhand\chapter3\s34_DIEN.py
#初始化gru网络,注意正式写代码时,初始化动作通常写在__init__() 方法里
GRU = nn.GRU( dim, dim, batch_first=True)
outs, h = GRU(item_embs)
和RNN 网络一样,会有两个输出,一个是outs,是每个GRU 单元输出向量组成的序列,维度是[批次样本数量,序列长度,向量维度],另一个h 指的是最后一个GRU 单元的输出向量。在DIEN 模型中,目前位置处的h 并没有作用,而outs却有两个作用。一个作用是作为下一层的输入,另一个作用是获取辅助loss。
什么是辅助loss,其实DIEN 网络是一个联合训练任务,最终对目标物品的推荐预测可以产生一个损失函数,暂且称为Ltarget,而这里可以利用历史物品的标注得到一个辅助损失函数,此处称为Laux。总的损失函数的计算公式为
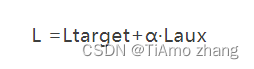
其中,α 是辅助损失函数的权重系数,是个超参。DIEN 给出的方法是一个二分类预测,如图5所示。
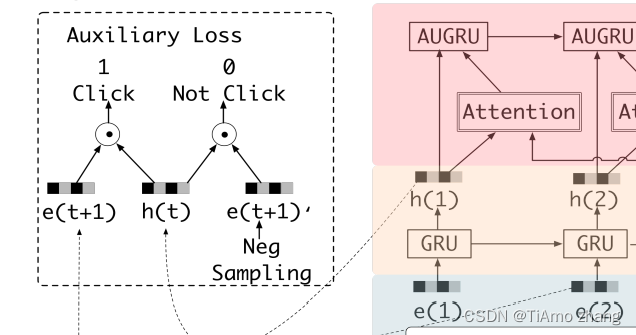
■ 图5 DIEN模型结构局部图(4)
历史物品标注指的是用户对对应位置的历史物品交互的情况,通常由1和0组成,1表示“感兴趣”,0则表示“不感兴趣”,如图5所示,将GRU 网络输出的outs与历史物品序列的Embedding输入一个二分类的预测模型中即可得到辅助损失函数,代码如下:
#recbyhand\chapter3\s34_DIEN.py
#辅助损失函数的计算过程
def forwardAuxiliary( self, outs, item_embs, history_labels ):
'''
:param item_embs: 历史序列物品的向量 [ batch_size, len_seqs, dim ]
:param outs: 兴趣抽取层GRU网络输出的outs [ batch_size, len_seqs, dim ]
:param history_labels: 历史序列物品标注 [ batch_size, len_seqs, 1 ]
:return: 辅助损失函数
'''
#[ batch_size * len_seqs, dim ]
item_embs = item_embs.reshape( -1, self.dim )
#[ batch_size * len_seqs, dim ]
outs = outs.reshape( -1, self.dim )
#[ batch_size * len_seqs ]
out = torch.sum( outs * item_embs, dim = 1 )
#[ batch_size * len_seqs, 1 ]
out = torch.unsqueeze( torch.sigmoid( out ), 1 )
#[ batch_size * len_seqs,1 ]
history_labels = history_labels.reshape( -1, 1 ).float()
return self.BCELoss( out, history_labels )
调整张量形状后做点乘,Sigmoid激活后与历史序列物品标注做二分类交叉熵损失函数(BCEloss)。
以上是第二部分兴趣抽取层所做的事情,最后来看最关键的第三部分。
第三部分: 兴趣演化层,主要由一个叫作AUGRU 的网络组成,AUGRU 是在GRU 的基础上增加了注意力机制。全称叫作GRU With Attentional Update Gate。AUGRU 的细节结构如图6所示。
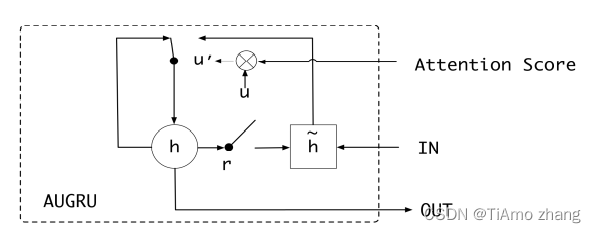
■ 图6 AUGRU 单元细节
02、图书推荐
在大数据时代背景下,统计学作为数据分析领域的基础,被应用于各行各业,其方法发挥着重要作用。为了更广泛地普及统计学知识,培养更多的统计学人才,本书应运而生。

本书融合大量情景案例,轻松理解统计知识;零基础起步商务统计,培养数据价值思维。入门级统计学教程,培养数据价值思维。
作为入门级图书,本书内容安排如下。第1章从不确定性出发,讲述统计学和不确定性的关系,以及统计学中用于描述不确定性的各种概率模型。第2章是参数估计,系统讲述统计学中矩估计和极大似然估计两种常用的参数估计方法,并基于两种方法介绍各种常见概率分布中参数的点估计和区间估计。第3章是假设检验,首先从不确定性的角度探讨实际中的各种决策问题,帮助读者理解假设检验的思想和应用场景,然后系统介绍假设检验的方法论及各种常见推广。第4章是回归分析,首先介绍回归分析的思想和广泛的应用场景,然后系统地介绍各类常用模型,从线性回归到广义线性回归,最终落脚到两种机器学习算法(决策树、神经网络)。
本书特别强调实际应用,因此各个章节都辅以大量的实际案例,在介绍统计学基础知识的同时培养读者使用统计学方法解决实际问题的能力。
版权归原作者 TiAmo zhang 所有, 如有侵权,请联系我们删除。