Vit极简原理+pytorch代码
Vit比它爹Transformer步骤要简单的多,需要注意的点也要少得多,最令人兴奋的是它在代码中没有令人头疼的MASK,还有许多简化的操作,容我慢慢道来。
语义分割之RandLANet深度解读
语义分割任务是计算机视觉里的一个比较基础的任务,其相比于物体检测任务主要有以下几个优点:输出的结果是稠密的,是针对于所有像素点的K分类问题,物体检测任务只输出前景类物体的信息忽略了背景点的信息在自动驾驶任务中可以实现可行驶区域的识别,大部分区域都是以背景的形式存在,而这些背景同样是非行驶区域可以输出
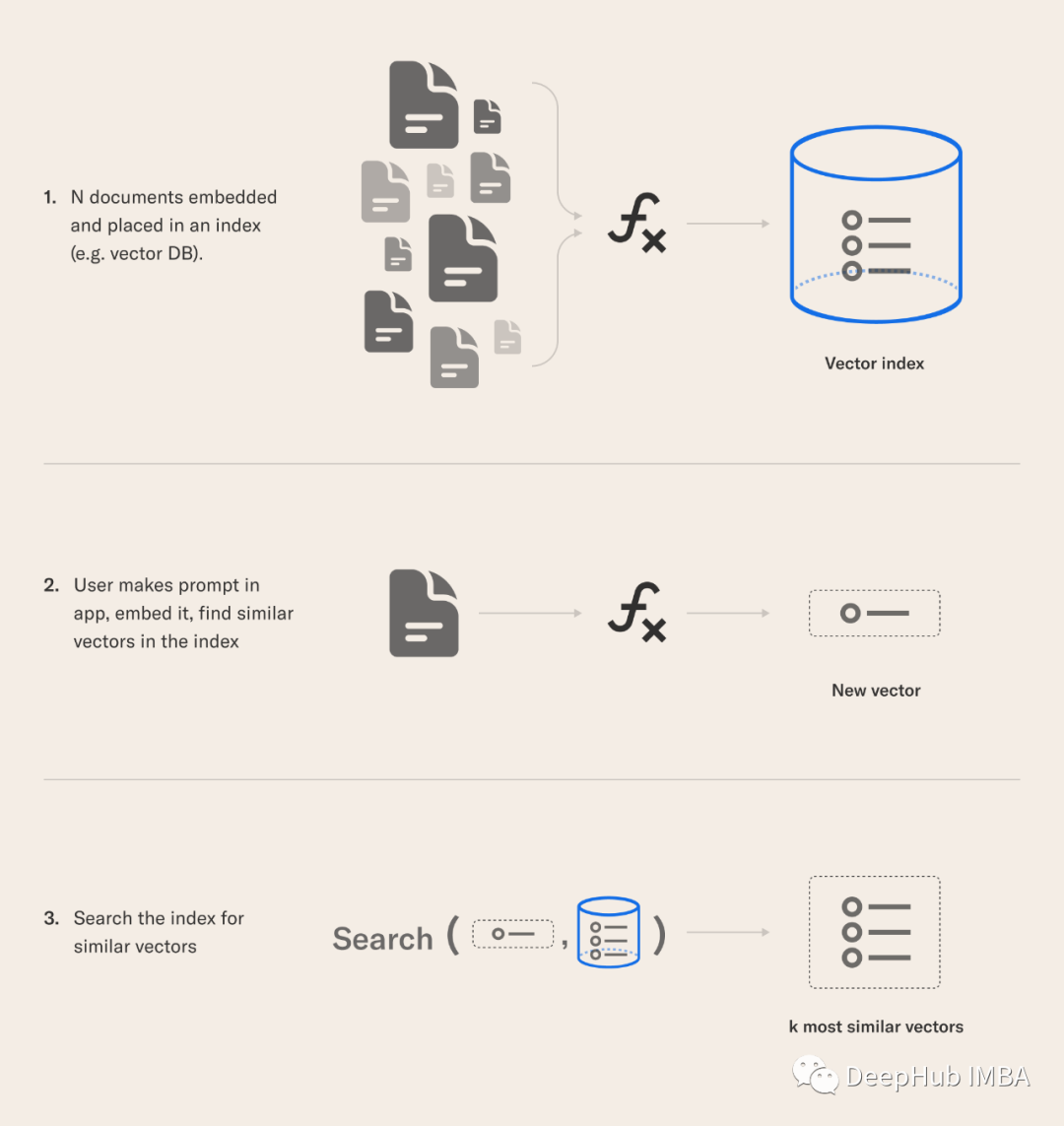
RAG应用程序的12种调优策略:使用“超参数”和策略优化来提高检索性能
本文从数据科学家的角度来研究检索增强生成(retrieve - augmented Generation, RAG)管道。讨论潜在的“超参数”,这些参数都可以通过实验来提高RAG管道的性能。
2023-2024年最全的人工智能深度学习毕业设计选题大全
这两年开始计算机毕业设计要求越来越高,有的题目甚至专业的老师和研究生也难以应对。为了各位同学以最少的精力通过毕设,为各位分享一些优质的毕业设计选题方向。深度学习,计算机视觉,目标检测,图像分割,图像分类,卷积神经网络具体课题如下:手写数字识别,手写字母识别,图片识别,水果识别,花卉识别,手势识别,安
梯度消失与梯度爆炸产生、原理和解决方案
本文章总结了梯度消失与梯度爆炸产生、原理和解决方案。
分布式版本管理系统---->Git(Linux---centos(保姆式)讲解1)
git分布式版本控制系统保姆式详解
python深度学习【transforms所有用法介绍】
python深度学习【transforms所有用法介绍】
毕设 深度学习的水果识别 opencv python
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是🚩深度学习的水果识别 opencv pyth
AI:87-基于深度学习的街景图像地理位置识别
基于深度学习的街景图像地理位置识别随着深度学习技术的飞速发展,人工智能在各个领域展现出强大的潜力。其中,基于深度学习的街景图像地理位置识别成为近年来备受关注的研究方向之一。本文将深入探讨深度学习在街景图像地理位置识别中的应用,介绍相关算法和技术,并附上实际代码示例。街景图像地理位置识别是指通过分析街
Transformer中的注意力机制及代码
transformer注意力机制实现过程整理。
【自监督】系列(二)-代理任务(Pretext Task)
本系列第二弹就来学习下代理任务(pretext task),Pretext可以理解为是一种为达到特定训练任务而设计的间接任务。
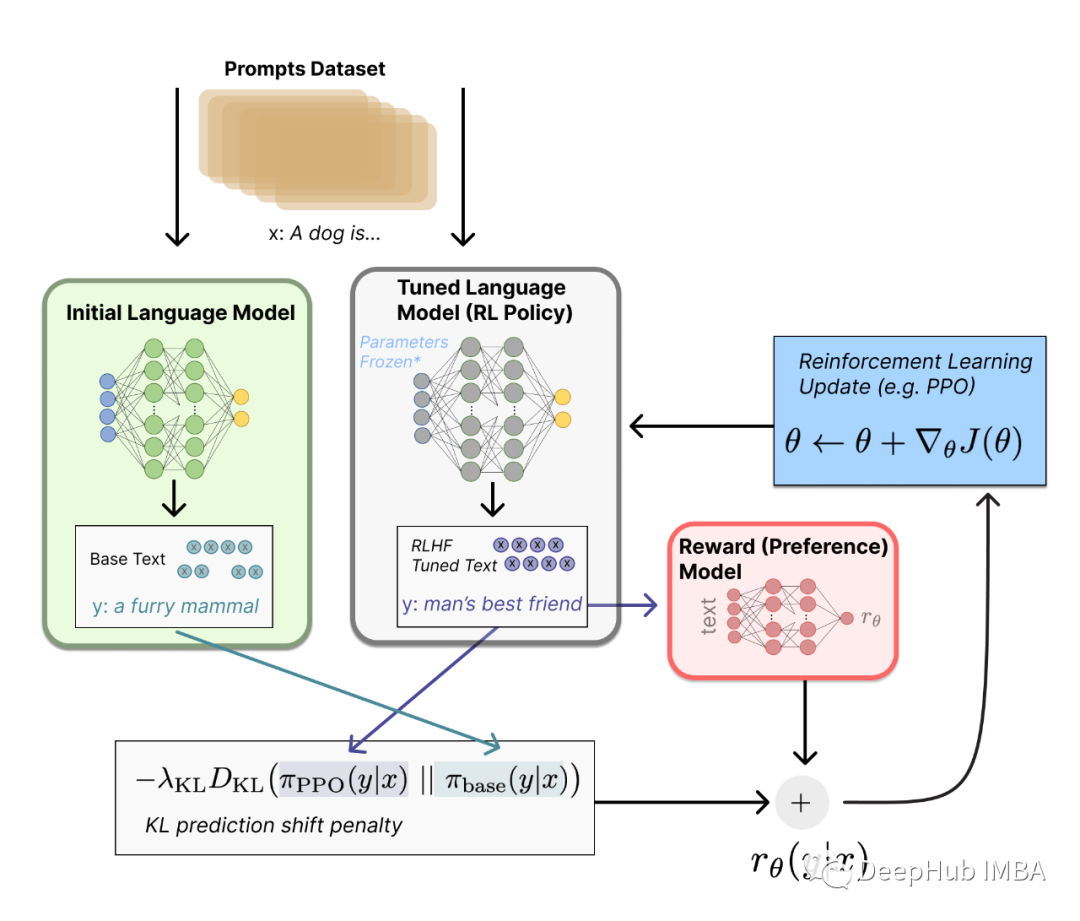
使用Huggingface创建大语言模型RLHF训练流程的完整教程
在本文中,我们将使用Huggingface来进行完整的RLHF训练。
Anaconda Navigator 无法打开解决办法
Anaconda Navigator 时不时出现打不开,或者点击图标无反应的情况。
机器学习|优化算法 | 评估方法|分类模型性能评价指标 | 正则化
机器学习|正则化|评估方法|分类模型性能评价指标|吴恩达学习笔记(哔哩哔哩视频and课堂PPT笔记梳理)
神经网络的类型分类和结构理解
神经网络按照不同的分类方式,会有多种形式的划分。第一种分类方式是按照类型来分,包含两种类型,分别为前馈神经网络和反馈神经网络。掌握神经网络层与层之间的结构后,会有助于我们对神经网络的理解,从而更好的理解参数模型,找到算法合适的参数。
人工智能 - 人脸识别:发展历史、技术全解与实战
本文全面探讨了人脸识别技术的发展历程、关键方法及其应用任务目标,深入分析了从几何特征到深度学习的技术演进。

11月推荐阅读的12篇大语言模型相关论文
现在已经是12月了,距离2024年只有一个月了,本文总结了11月的一些比较不错的大语言模型相关论文
文本识别CRNN模型介绍以及pytorch代码实现
文本识别CRNN pytorch
人工智能概论报告-基于PyTorch的深度学习手写数字识别模型研究与实践
CQUPT人工智能概论的课程大作业实践应用报告,供大家参考,如果有需要word版的可以私信我,或者在评论区留下邮箱,我会逐个发。word版是我最后提交的,已经调整统一了全文格式等。希望能给大家提供一些参考。如果起到作用请给我点个赞哦,嘿嘿嘿嘿



