“AI教父”Geoffrey Hinton:智能进化的下一个阶段
ChatGPT等大模型带来的震撼技术革新,让Geoffrey Hinton突然改变了自己的一个想法。这位75岁的“人工智能教父”意识到,数字智能优于生物智能的进程无法避免,超级智能很快就会到来,他必须要对其风险发出警示,而人类需要找到一种方法来控制AI技术的发展。而在此之前,他一直认为,智能机器人不
光流估计(二) FlowNet 系列文章解读
在上篇文章中,我们学习并解了光流(Optical Flow)的一些基本概念和基本操作,但是传统的光流估计方法计算比较复杂、成本较高。近些年来随着CNN卷积神经网络的不断发展和成熟,其在各种计算机视觉任务中取得了巨大成功(多用于识别相关任务)。于是,将光流估计与CNN深度学习相结合提出了FlowNet
通过WSL2搭建Pytorch1.10+CUDA11.4+NVIDIA Driver深度学习框架
通过WSL2搭建Pytorch1.10+CUDA11.4+NVIDIA Driver深度学习框架
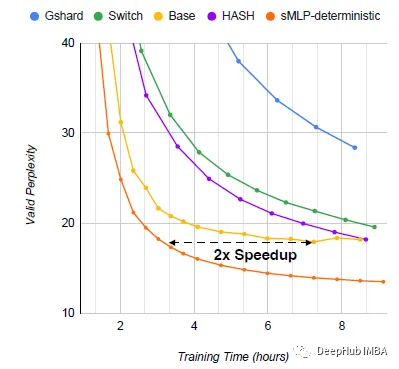
sMLP:稀疏全mlp进行高效语言建模
论文提出了sMLP,通过设计确定性路由和部分预测来解决下游任务方面的问题。
AI时代再进化!GitHub上热门AI工具大PK!
作为如今备受推崇的开发者技术社区,GitHub 近来涌现出众多令人激动的 AI 工具。这些工具都有一些共同的特质:它们不仅简单易用,高效便捷,而且融入了引人注目的创新元素,能够显著提升您个人的工作效率和生产力。今天,我将带您深入了解一些备受欢迎的 GitHub 上的 AI 工具,这些工具将成为您日常
YOLOv5算法进阶改进(3)— 引入深度可分离卷积C3模块 | 轻量化网络
深度可分离卷积是一种卷积神经网络中的卷积操作,可以大大减少计算量和参数数量,从而提高模型的效率和准确性。本节课就给大家介绍一下如何在YOLOv5主干网络中引入深度可分离卷积C3模块,希望大家学习之后能够有所收获~!🌈
用CHAT如何写视频剪辑思路?
2. 呈现故事流程:国学充满智慧和故事,你可以考虑将课程内容制作成故事形式,让观众在享受故事的同时学习到知识。3. 利用图标和动画解释复杂概念:对于抽象的国学理论,可以用图标和动画进行解释,让观众更易理解。5. 适当使用音乐和声音效果:恰当的背景音乐和声音效果能够增强表达情感,制造紧张或轻松的氛围。
【端到端图像压缩】CompressAI运行记录
期末作业要求运行端到端的图像压缩代码,过程中学习了csdn上诸多教程。这里将运行的过程分享出来。
图像数据增强算法汇总(Python)
数据增强是一种通过使用已有的训练样本数据来生成更多训练数据的方法,可以应用于解决数据不足的问题。数据增强技术可以用来提高模型的泛化能力,减少过拟合现象。比如在狗猫识别项目中,通过随机旋转、翻转和裁剪等数据增强方法,可以使模型具有对不同角度和尺寸的狗猫图像的识别能力。增加训练样本数量:通过生成新样本,
Pycharm报错torch.cuda.OutOfMemoryError: CUDA out of memory.
做深度学习相关的实验,可以看到我的显卡内存很小(哭了,不过我有时候是在别的电脑上做的,那个电脑比这个好用),网上搜到的说的 max_split_size_mb:128 这个方法我贴到我代码上之后没有效果。因为我在这个电脑上做的是主实验后面的一些对比实验,也就是代码中很多张量很多数据是不需要的。所
用最通俗的方式理解LSTM和重要参数
LSTM---长短期记忆递归神经网络是一个非常常用的神经网络,其特点在于该网络引入了长时记忆和短时记忆的概念,因而适用于一些有着上下文语境的回归和分类,诸如温度预测或是语义理解。从利用pytorch来构造模型的角度来看,该模型相比于一般的模型会有一些不同的地方,尤其是在参数的设置上,本文尝试以一个相
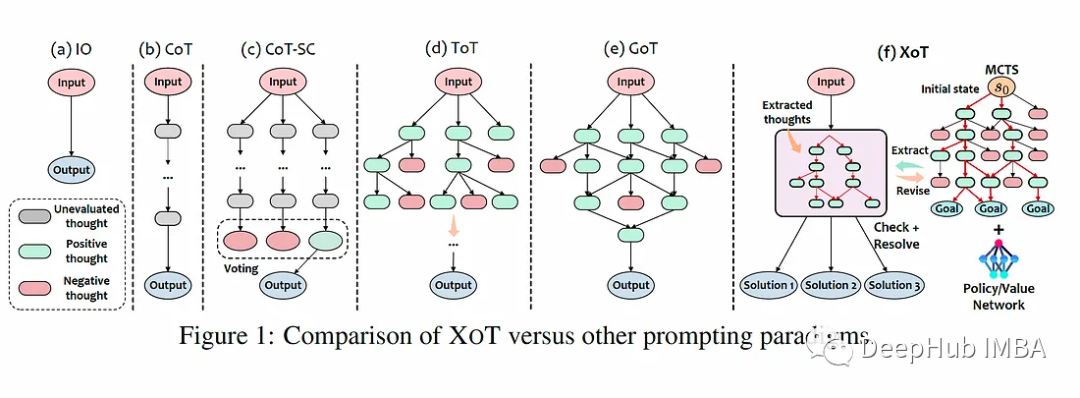
XoT:一种新的大语言模型的提示技术
这是微软在11月最新发布的一篇论文,它增强了像GPT-3和GPT-4这样的大型语言模型(llm)解决复杂问题的潜力。
常用的数据集网站
常用数据集网站
卷积总结篇(普通卷积、转置卷积、膨胀卷积、分组卷积和深度可分离卷积)
卷积总结篇(普通卷积、转置卷积、膨胀卷积、分组卷积和深度可分离卷积),分别从概念、背景、原理、参数量、计算量、感受野、各种卷积的优点以及在网络的应用展开讲解。
AI数字人:最强声音驱动面部表情模型VideoReTalking
VideoReTalking是一个强大的开源模型,是目前语音驱动面部表情的模型中效果最好的一个。此模型是由西安电子科技大学、腾讯人工智能实验室和清华大学联合开发的。
YoloV8改进策略:将FasterNet与YoloV8深度融合,打造更快更强的检测网络
我们尝试了三种改进方法,测试结果也是基于我自己选择的数据集,在其他的数据集中表现怎么样还是需要自己尝试才行!
Pytorch学习笔记(8):正则化(L1、L2、Dropout)与归一化(BN、LN、IN、GN)
Pytorch学习笔记(8):正则化(L1、L2、Dropout)与归一化(BN、LN、IN、GN)超级详细!
【人工智能概论】 变分自编码器(Variational Auto Encoder , VAE)
变分自编码器(Variational Auto Encoder , VAE)
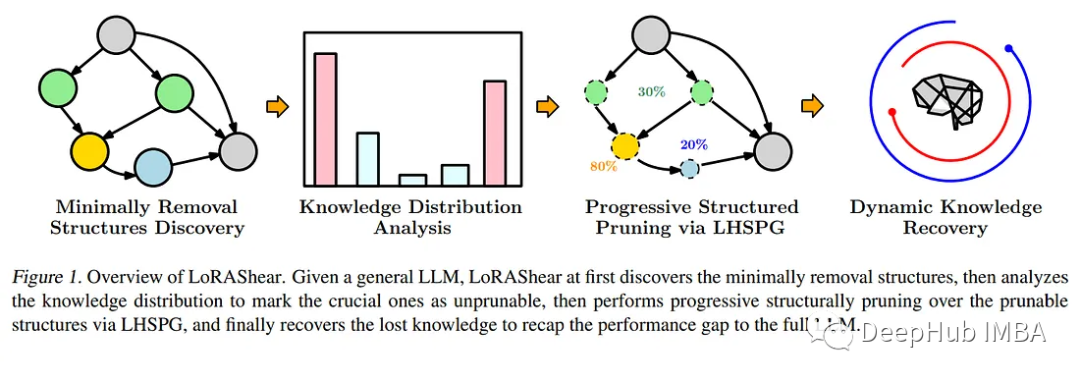
LoRAShear:微软在LLM修剪和知识恢复方面的最新研究
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。
人工智能概览
1.人工智能定义2.人工智能发展历史3.人工智能产业生态4.人工智能落地挑战5.人工智能发展趋势



