【计算机视觉】ViT:代码逐行解读
【计算机视觉】ViT:代码逐行解读
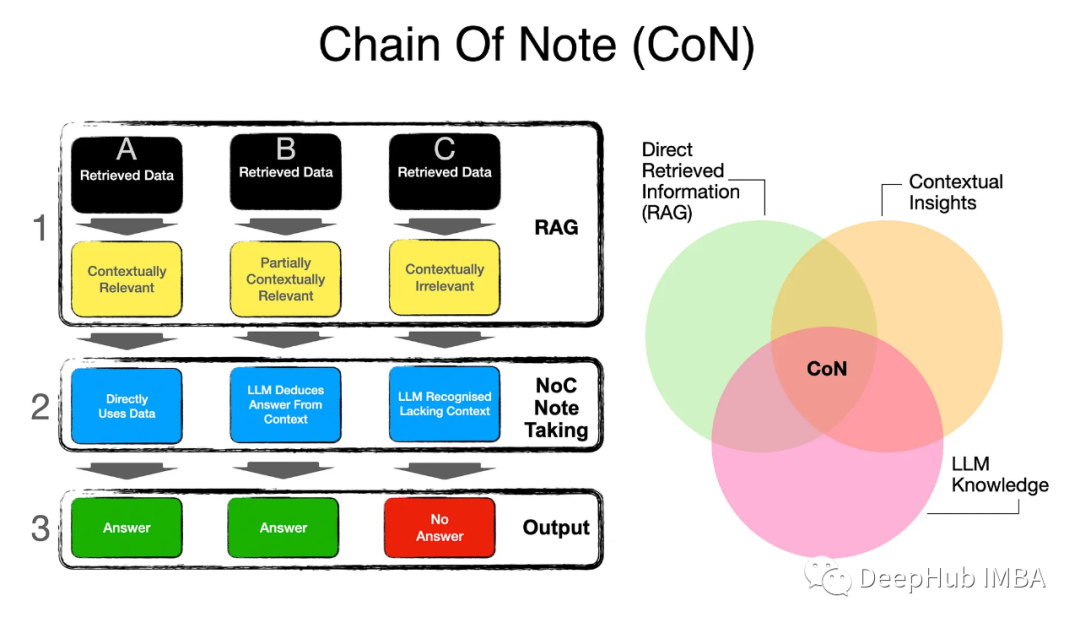
Chain-Of-Note:解决噪声数据、不相关文档和域外场景来改进RAG的表现
这是腾讯实验室在11月最新发布的一篇论文,CoN的核心思想是生成连续的阅读笔记对于检索到的文档,能够对其与给出问题并综合这些信息来形成最终的答案,提高了RAG的表现。
使用冻结层进行迁移学习
使用冻结层进行迁移学习
Swin-transformer详解
这篇论文提出了一个新的 Vision Transformer 叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络.但是直接把Transformer从 NLP 用到 Vision 是有一些挑战的,这个挑战主要来自于两个方面一个就是尺度上的问题。因为比如说现在有
【简单作业向】【Pytorch】猫狗分类
【作业向】根据给定的猫狗分类数据集,对比不同训练方法的差异,并生成的模型的正向传播图。
pytorch加载模型和模型推理常见操作
pth文件可以保存模型的拓扑结构和参数,也可以只保存模型的参数,取决于model.save()中的参数。
多模态情感识别-MISA: baseline解读
不同模态数据分布的异质性使得模态融合的难度较高
关于迁移学习的方法
迁移学习的具体实现
“私密离线聊天新体验!llama-gpt聊天机器人:极速、安全、搭载Llama 2,尽享Code Llama支持!”
“私密离线聊天新体验!llama-gpt聊天机器人:极速、安全、搭载Llama 2,尽享Code Llama支持!”
火星探测器背后的人工智能:从原理到实战的强化学习
本文详细探讨了强化学习在火星探测器任务中的应用。从基础概念到模型设计,再到实战代码演示,我们深入分析了任务需求、环境模型构建及算法实现,提供了一个全面的强化学习案例解析,旨在推动人工智能技术在太空探索中的应用。
PyCharm切换虚拟环境
为了满足不同任务需要不同版本的包,可以在Anaconda或者Miniconda创建多个虚拟环境文件夹,并在PyCharm下切换虚拟环境。格式:conda create -n 虚拟环境名字 python=3.8。至此,切换虚拟环境完成,接下来可以根据项目的不同下载不同版本的包。
注意力机制——Convolutional Block Attention Module(CBAM)
其中通道注意力模块通过对输入特征图在通道维度上进行最大池化和平均池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个通道注意力权重向量。空间注意力模块则通过对输入特征图在通道维度上进行平均池化和最大池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个空间注意力权重张量。CBAM 模块
航空大数据——项目资源汇总及开源(四)
ADS-B项目开源大礼包
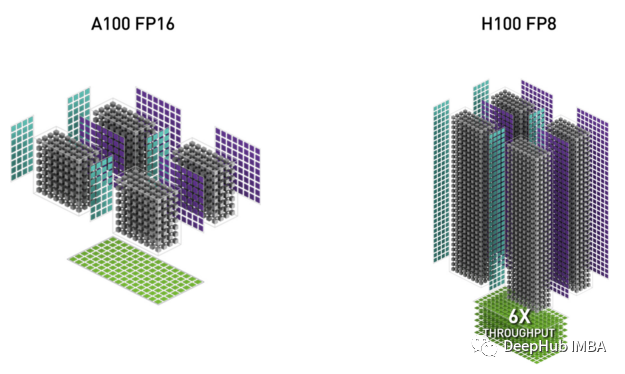
使用FP8加速PyTorch训练
在这篇文章中,我们将介绍如何修改PyTorch训练脚本,利用Nvidia H100 GPU的FP8数据类型的内置支持。
PyTorch深度学习环境安装(Anaconda、CUDA、cuDNN)及关联PyCharm
TytorchPython机器学习库,基于Torch,用于自然语言处理等应用程序Anaconda:是默认的python包和环境管理工具,安装了anaconda,就默认安装了condaCUDACUDA是一种由显卡厂商NVIDIA推出的通用并行计算架构,该架构使GPU能解决复杂的计算问题,可用来计算深度
nnUNet原创团队全新力作!MedNeXt:医学图像分割新SOTA
MedNeXt是nnUNet原创团队于2023年3月17日上传至arxiv上的新作品,该模型受ConNeXt启发,根据Transformer改进了现有的卷积网络,实现了医学图像分割领域的SOTA。除了用Transformer改造UNet之外,MedNeXt还改进了上采样和下采样块、提出了一个用小卷积
【论文笔记】用于图像拼接的基于深度学习的图像矩形化算法
图像拼接矩形化的目的是解决图像拼接后产生不规则边界的问题。现有的图像拼接矩形化方法通常分为两个阶段:第一个阶段是搜索一个初始网格,也就是在拼接图像上放置一个规则的网格,用来描述图像上每个点的位置;第二个阶段是优化一个目标网格,也就是在初始网格的基础上进行一些变形,使得网格边缘尽可能地与矩形边界对齐。
用TrackEval评测自己的数据集
跑通代码最重要的就是路径问题, 为此我写了两个config模板, 让配置路径更简单.
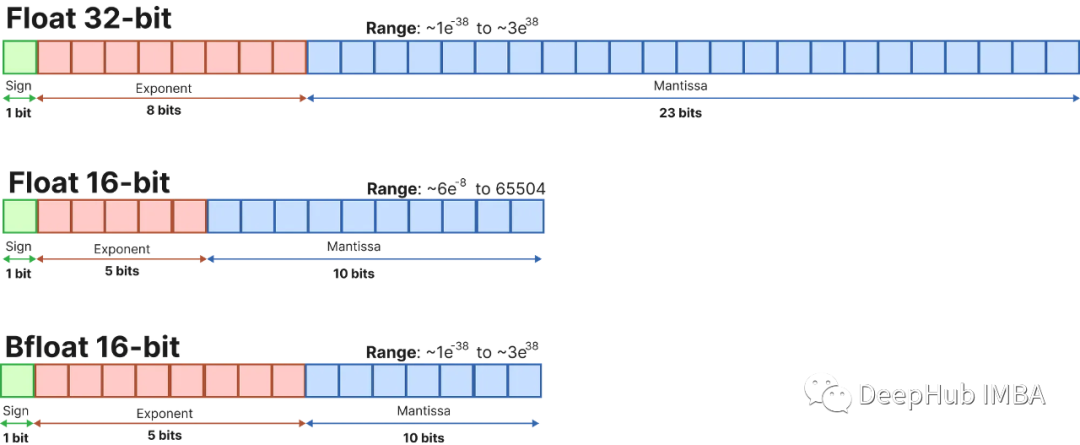
大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
深度学习之图像分割—— SegNet基本思想和网络结构以及论文补充
也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,对于上图的6来说,6在粉色2x2 filter中的位置为(1,1)(index从0开始),黄色的3的index为(0,0)。,即卷积后保持图像原始尺寸;在网络框架中,SegNet,最后一个卷积层会输出所有的类别



