【机器学习】李宏毅-食物图像分类器
卷积层,256个channel,512个filter,每个filter大小3*3,stride=1,padding=1,输入256*16*16,输出512*16*16。卷积层,512个channel,512个filter,每个filter大小3*3,stride=1,padding=1,输入512*
【深度学习:Few-shot learning】理解深入小样本学习中的孪生网络
Meta Learning (元学习)中,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。Meta Learning,又称为learning
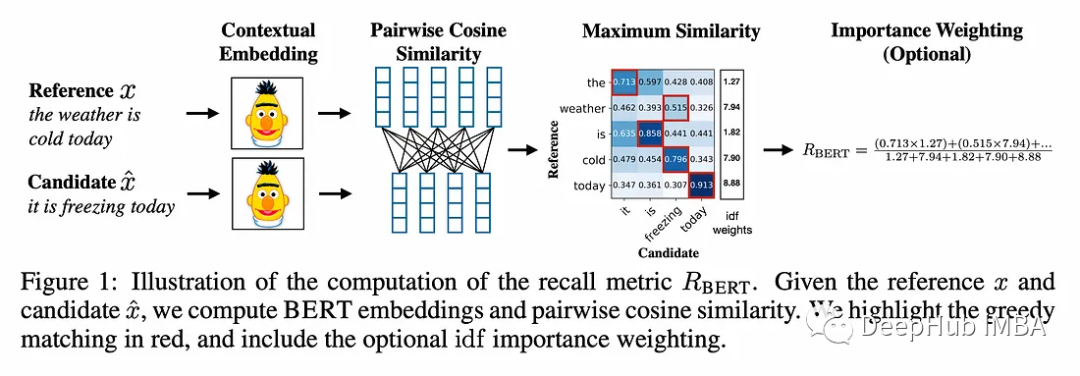
如何避免LLM的“幻觉”(Hallucination)
生成式大语言模型(LLM)可以针对各种用户的 prompt 生成高度流畅的回复。然而,大模型倾向于产生幻觉或做出非事实陈述,这可能会损害用户的信任。
【torch.nn.init】初始化参数方法解读
稀疏矩阵:将2D输入张量填充为稀疏矩阵,其中非零元素将从正态分布N ( 0 , 0.01 ) N(0,0.01)N(0,0.01)中提取。正态分布:从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量。xavier_normal 分布:用一个正态分布生成值,填充输入的张
基于注意力的时空图卷积网络交通流预测
由于图信号的卷积运算等于通过图傅里叶变换变换到谱域的这些信号的乘积,因此上式可以理解为分别将gθ和x进行傅里叶变换到谱域,然后将它们的变换结果相乘,进行傅里叶反变换,得到卷积运算的最终结果。因此,周周期分量的设计是为了捕捉交通数据中的周周期特征。时间维度卷积:图卷积操作在空间维度捕获图上每个节点的相
Pycharm搭建CUDA,Pytorch教程(匹配版本,安装,搭建全保姆教程)
最近训练模型跑代码需要用到nvidia的cuda架构加速,结果网上几乎找不到什么能直接解决问题的教程,最后东拼西凑了几个小时才搭建完成,所以想整理出这篇集百家之精华的教程,防止自己以后太久不用忘记了。
大数据深度学习Pytorch 最全入门介绍,Pytorch入门看这一篇就够了
本文通过详细且实践性的方式介绍了 PyTorch 的使用,包括环境安装、基础知识、张量操作、自动求导机制、神经网络创建、数据处理、模型训练、测试以及模型的保存和加载。这篇文章通过详细且实践性的方式介绍了 PyTorch 的使用,包括环境安装、基础知识、张量操作、自动求导机制、神经网络创建、数据处理、
注意力机制(一):注意力提示、注意力汇聚、Nadaraya-Watson 核回归
目录注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语音识别等领域,注意力机制已经得到了广泛的应用。注意力机制的主要思想是,在对序列数据进行处理时,通过给不同位置的输入信
基于CNN卷积神经网络 猫狗图像识别
基于CNN卷积神经网络 猫狗图像识别
【机器学习项目实战10例】(七):基于逻辑回归方法完成垃圾邮件过滤任务
下载下来的数据集是csv格式的,每条数据有两列,分别是文本内容和对应的标签(ham or spam)。我们首先利用python的pandas库读取csv文件中的数据,然后先对数据进行简单分析,然后对数据进行预处理,最后是将文本内容向量化,文本向量化后才可以利用算法模型进行文本分类任务。(1)读取数据
28. 深度学习进阶 - LSTM
后来大家就发现了一种改进的LSTM,其中门控机制允许细胞状态窥视现前的细胞状态的信息,而不仅仅是根据当前时间步的输入和隐藏状态来决定。对于RNN来说,它有一个很严重的问题,就是之前说过的,它的vanishing和exploding的问题会很明显, 也就是梯度消失和爆炸问题。这节课,我们就着上一节课的
Jeston NANO 配置并安装 torch+ torchvision
由于nano的arm64架构,所以用它进行深度学习配置部署时会与用普通电脑(x86)有所不同
Pytorch入门(五)使用ResNet-18网络训练常规状态下的CIFAR10数据集
本文介绍了如何使用Pytorch+ResNet-18+CIFAR-10进行深度学习训练,并使用训练好的权重进行预测,ResNet是一个非常优秀的神经网络,ResNet 在图像分类任务中表现出色。
经典文献阅读之--NeRF-SLAM(单目稠密重建)
NeRF 是 2020 年 ECCV 上获得最佳论文荣誉提名的工作,其影响力是十分巨大的,不论是后续的学术论文还是商业落地,都引起了大量从业人员的关注。NeRF 将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景,在新视角合成这一任务上的表现是非
OSTrack的一些代码执行命令讲解
执行如下命令可以生成路径文件,分别会在OSTrack/lib/train/admin目录和OSTrack/lib/test/evaluation目录下生成local.py文件,里面是各种路径的默认设置。配置文件为OSTrack/experiments/ostrack/vitb_256_mae_ce_

使用LOTR合并检索提高RAG性能
RAG结合了两个关键元素:检索和生成。本文将介绍使用使用Merge retriver改进RAG的性能
人工智能生成文本检测在实践中使用有效性探讨
本文介绍了关于如何检测ai生成文本的思路。可以使用的主要指标是生成文本的困惑度。还介绍了这种方法的一些缺点,包括误报的可能性。希望这有助于理解检测人工智能生成文本背后的细节。但是当我们讨论检测人工智能生成文本的技术时,这里的假设都是整个文本要么是人类编写的,要么是人工智能生成的。但是实际上文本往往部
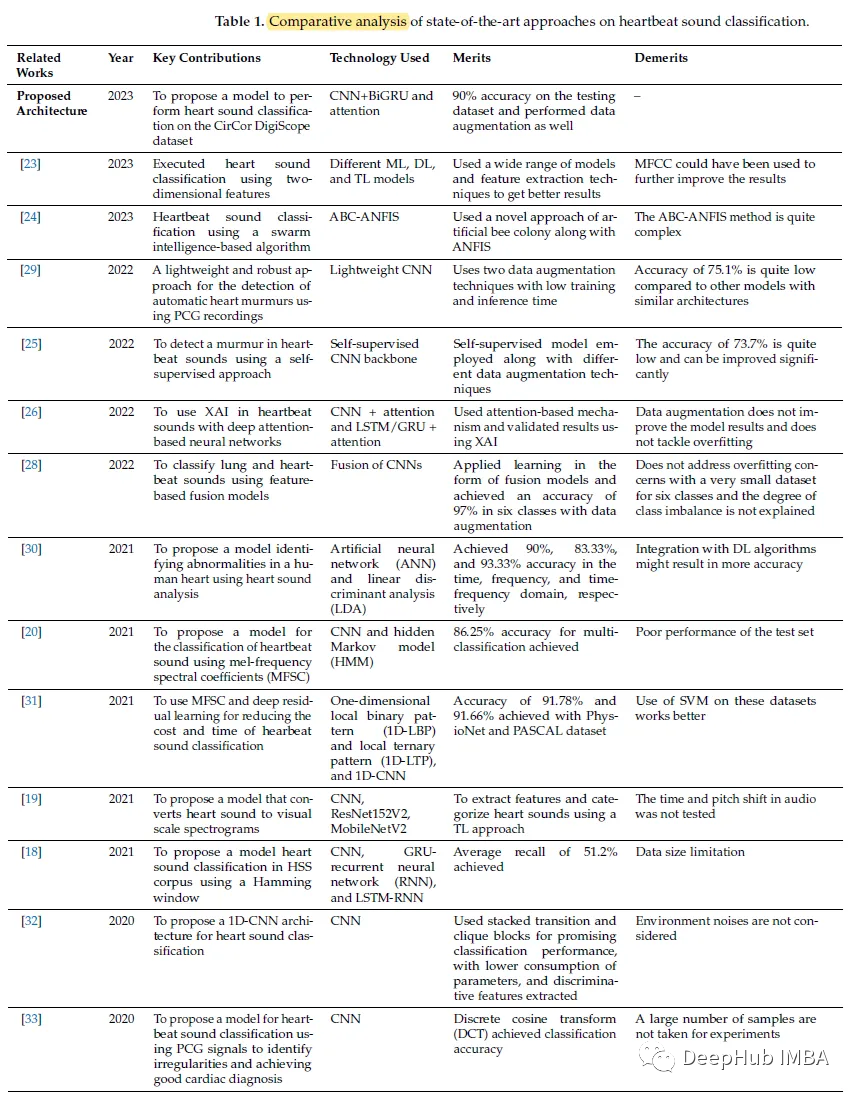
基于CNN和双向gru的心跳分类系统
论文,提出了基于卷积神经网络和双向门控循环单元(CNN + BiGRU)注意力的心跳声分类,论文不仅显示了模型还构建了完整的系统。
基于VGG16的猫狗分类实战
基于VGG16的猫狗分类实战
基于Transformer的多变量风电功率预测TF2
Transformer目前大火,作为一个合格的算法搬运工自然要跟上潮流,本文基于tensorflow2框架,构建transformer模型,并将其用于多变量的风电功率负荷预测。实验结果表明,相比与传统的LSTM,该方法精度更高,缺点也很明显,该方法需要更多的数据训练效果才能超过传统方法,而且占用很高



