聊聊关于分类和分割的损失函数:nn.CrossEntropyLoss()
解释分类和分割中,CrossEntropyLoss 交叉熵损失函数的作用
AI:105-基于深度学习的手术操作监控与辅助
AI:105-基于深度学习的手术操作监控与辅助随着人工智能技术的飞速发展,深度学习作为其重要组成部分,在医学领域取得了显著的成就。其中,基于深度学习的手术操作监控与辅助系统成为医学界的研究热点。本文将深入探讨深度学习在手术领域的应用,重点关注手术操作的实时监控与辅助技术,并提供一个简单的代码实例来说
神经网络卷积反卷积及池化计算公式、特征图通道数(维度)变化实例
神经网络卷积反卷积及池化计算公式、特征图通道数(维度)变化实例
OpenCV | 告别人工目检:深度学习技术引领工业品缺陷检测新时代
本书专注于介绍OpenCV4在工业领域的常用模块,通过合理的章节设置构建了阶梯式的知识点学习路径。化繁就简、案例驱动,注重算法原理、代码演示及在相关场景的实际使用。本书还介绍了必备的深度学习知识与开发技巧,拓展OpenCV开发者技能。全书共16章,分为3篇。● 基础篇(第1~4章):主要介绍Open
huggingface下载的.arrow数据集读取与使用说明
huggingface下载的arrow数据集读取与使用说明
AI:05- - 基于深度学习的道路交通信号灯的检测与识别
随着人工智能的快速发展,基于深度学习的视觉算法在道路交通领域中起到了重要作用。本文将探讨如何利用深度学习技术实现道路交通信号灯的检测与识别,通过多处代码实例展示技术深度。道路交通信号灯是指示交通参与者行驶和停止的重要信号。准确地检测和识别交通信号灯对于智能交通系统和自动驾驶技术的发展至关重要。传统的
Swin Transformer详解
Vit出现后虽然让大家看到了Transformer在视觉领域的潜力,但并不确定Transformer可以做掉所有视觉任务。Swin Transformer可以作为一个通用的骨干网络。面对的挑战:1、多尺度。2、高像素。移动窗口提高效率,并通过Shifted操作变相达到全局建模能力。层次结构:灵活,可
Anaconda安装及配置(简单清晰版)
Anaconda安装与配置
大数据毕业设计 深度学习垃圾图像分类系统 - opencv python
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是🚩opencv python 深度学习垃圾分
【古诗生成AI实战】之四——模型包装器与模型的训练
中存储的正是这些词的概率。为了生成文本,我们提取每个位置上概率最高的词的索引,然后根据这些索引在词典中查找对应的词。此外,为了提高配置的灵活性和可维护性,我们将所有的配置项(如批量大小、数据集地址、训练周期数、学习率等)抽取出来,统一放置在一个名为。为此,我们采取了进一步的措施:在模型外面再套上一个
RoSA: 一种新的大模型参数高效微调方法
随着语言模型不断扩展到前所未有的规模,对下游任务的所有参数进行微调变得非常昂贵,PEFT方法已成为自然语言处理领域的研究热点。PEFT方法将微调限制在一小部分参数中,以很小的计算成本实现自然语言理解任务的最先进性能。
大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解
卷积神经网络是一种前馈神经网络,它的人工神经元可以响应周围单元的局部区域,从而能够识别视觉空间的部分结构特征。卷积层: 通过卷积操作检测图像的局部特征。激活函数: 引入非线性,增加模型的表达能力。池化层: 减少特征维度,增加模型的鲁棒性。全连接层: 在处理空间特征后,全连接层用于进行分类或回归。卷积
从零开始使用MMSegmentation训练Segformer
写在前面:最新想要用最新的分割算法如:Segformer or SegNeXt 在自己的数据集上进行训练,但是有不是搞语义分割出身的,而且也没有系统的学过MMCV以及MMSegmentation。所以就折腾了很久,感觉利用MMSegmentation搭建框架可能比较系统,但是对于不熟悉的或者初学者非
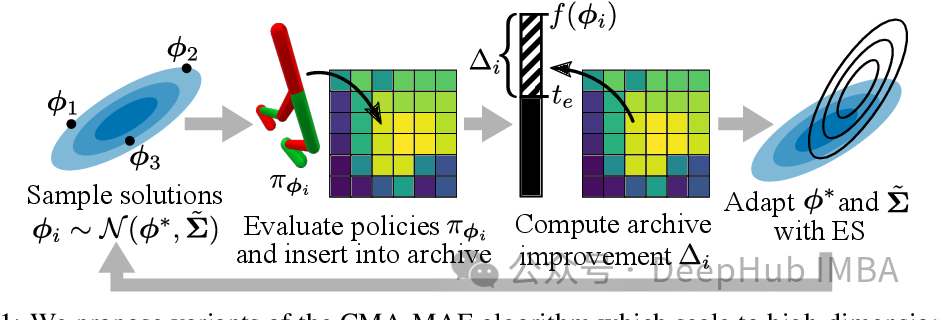
基于协方差矩阵自适应演化策略(CMA-ES)的高效特征选择
特征选择是指从原始特征集中选择一部分特征,以提高模型性能、减少计算开销或改善模型的解释性。
YOLOv5改进 | 注意力篇 | CGAttention实现级联群体注意力机制 (全网首发改进)
本文给大家带来的改进机制是实现级联群体注意力机制,其主要思想为增强输入到注意力头的特征的多样性。与以前的自注意力不同,它为每个头提供不同的输入分割,并跨头级联输出特征。这种方法不仅减少了多头注意力中的计算冗余,而且通过增加网络深度来提升模型容量,亲测在我的25个类别的数据上,大部分的类别均有一定的涨
人工智能详细笔记:深度学习解决图像分割问题(FCN Unet Deeplab)
图像分割是指将一幅数字图像分成若干个部分或者对象的过程。该任务的目标是将图像中的每个像素分配给其所属的对象或者部分,因此它通常被视为一种像素级别的图像分析。
Transformer模型详解
transformer结构是google在2017年的Attention Is All You Need论文中提出,在NLP的多个任务上取得了非常好的效果,可以说目前NLP发展都离不开transformer。最大特点是抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。 由于
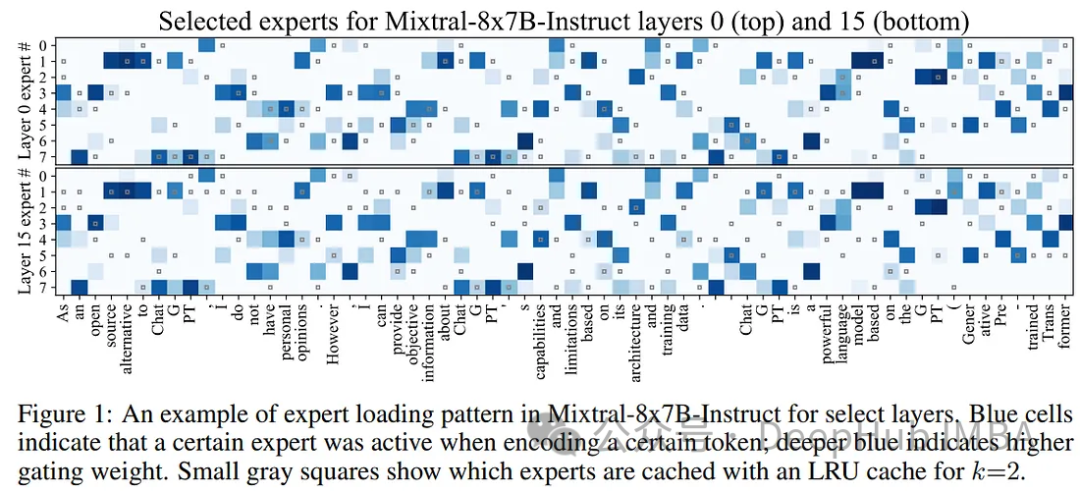
使用Mixtral-offloading在消费级硬件上运行Mixtral-8x7B
在本文中,将解释Mixtral-offloading的工作过程,使用这个框架可以节省内存并保持良好的推理速度,我们将看到如何在消费者硬件上运行Mixtral-8x7B,并对其推理速度进行基准测试。
AI安全初探——利用深度学习检测DNS隐蔽通道
DNS 通道是隐蔽通道的一种,通过将其他协议封装在DNS协议中进行数据传输。由于大部分防火墙和入侵检测设备很少会过滤DNS流量,这就给DNS作为隐蔽通道提供了条件,从而可以利用它实现诸如远程控制、文件传输等操作,DNS隐蔽通道也经常在僵尸网络和APT攻击中扮演着重要的角色。
【深度学习框架-torch】torch.norm函数详解用法
torch版本1.6



