AI:09-基于深度学习的图像场景分类
图像场景分类是计算机视觉领域的重要任务之一,它涉及将图像分为不同的场景类别,如城市街景、山脉风景、海滩等。本文将介绍基于深度学习的图像场景分类方法,并提供相应的代码实例,展示了深度学习在图像场景分类中的技术深度和应用前景。图像场景分类是计算机视觉中的一项关键任务,对于图像内容理解、图像检索和自动标注
17- TensorFlow中使用Keras创建模型 (TensorFlow系列) (深度学习)
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow , CNTK 或者 Theano 作为后端运行。在Keras的官方github上写着"Deep Learning for humans", 主要是因为它能简单快速的创建神经网络,而不需要像Tensorfl

在Colab上测试Mamba
本文整理了一个能够在Colab上完整运行Mamba代码,代码中还使用了Mamba官方的3B模型来进行实际运行测试。
Stable Diffusion XL webui tagger 插件Linux安装(保姆级教程)
为了使SD能生成我们想要的图像效果,往往需要对SD模型进行微调,但其权重参数太多,如果是用更新全部参数的方法来微调,会耗费大量的计算资源。那么可不可以仅需少量计算资源,对模型进行微调,也有不错的效果呢?答案是肯定的,那就是:基于LoRA对其进行微调!本文写作动机:想自己训练LoRA,需要对训练数据进
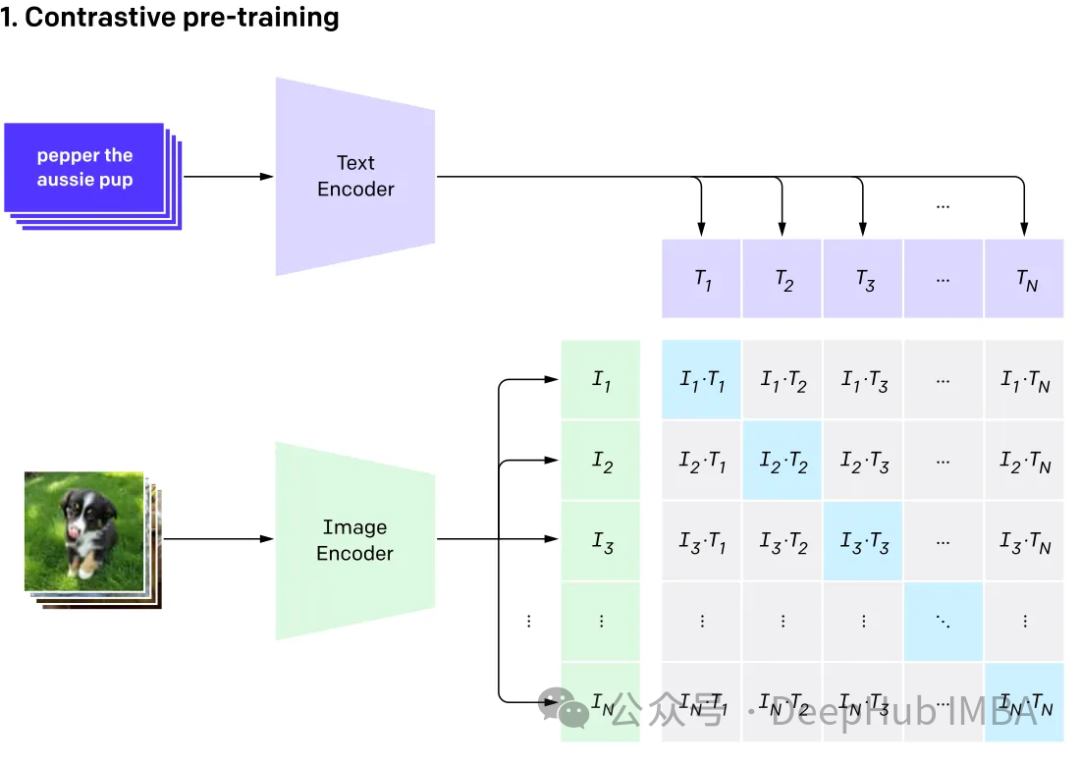
使用CLIP和LLM构建多模态RAG系统
在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。
AI:08-基于深度学习的车辆识别
基于深度学习的车型识别是一个复杂的任务,上述代码示例只是一个简单的示意,并不能涵盖所有的细节和技术深度。在实际应用中,可能还需要进行模型调优、模型融合、迁移学习等操作来提高识别的准确性和鲁棒性。
大数据深度学习长短时记忆网络(LSTM):从理论到PyTorch实战演示
LSTM的逻辑结构通过其独特的门控机制为处理具有复杂依赖关系的序列数据提供了强大的手段。其对信息流的精细控制和长期记忆的能力使其成为许多序列建模任务的理想选择。了解LSTM的这些逻辑概念有助于更好地理解其工作原理,并有效地将其应用于实际问题。我们首先定义一个LSTM类,该类使用PyTorch的nn.
探索AI技术的奥秘:揭秘人工智能的核心原理
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站今天的干货分享到这里就结束啦!如果觉得文章还可以的话,希望能给个三连支持一下,阿Q的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是作者前进的最大动力!
损失函数 - 二元交叉熵损失函数 nn.BCELoss() 与 torch.nn.BCEWithLogitsLoss()
二元交叉熵损失函数 nn.BCELoss() 与 torch.nn.BCEWithLogitsLoss()
感知与认知的碰撞,大模型时代的智能文档处理范式
第十九届中国图象图形学学会青年科学家会议上,合合信息带来了关于多模态大模型赋能文档处理的相关内容,欢迎感兴趣的同学了解~
AI:02-基于深度学习的动物图像检索算法的研究
本文介绍了一种基于深度学习的动物图像检索算法,采用ResNet50作为特征提取器,通过计算特征向量之间的相似度,实现了高效准确的图片检索。我们提供了相应的代码实现,供读者参考。首先,该算法的核心思想是使用深度学习模型提取图片的特征向量,然后通过计算这些特征向量之间的相似度,实现对于动物图片的快速检索
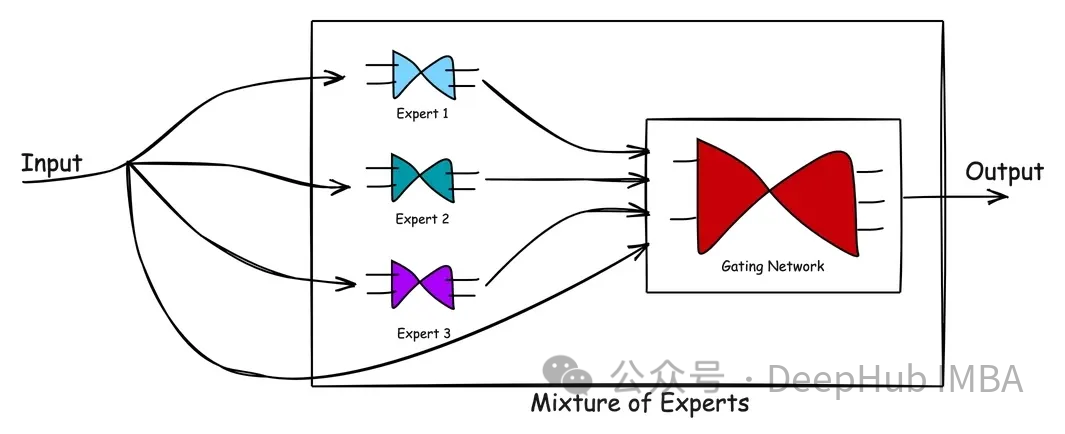
使用PyTorch实现混合专家(MoE)模型
在本文中,我将使用Pytorch来实现一个MoE模型。在具体代码之前,我们先简单介绍混合专家的体系结构。
经典神经网络论文超详细解读(八)——ResNeXt学习笔记(翻译+精读+代码复现)
ResNeXt论文(《Aggregated Residual Transformations for Deep Neural Networks》)超详细解读。翻译+总结。文末有代码复现
MobileOne(CVPR 2023)原理与代码解析
针对移动设备的高效深度学习架构的设计和部署已经取得了很大进展,很多轻量模型在减少浮点操作(floating-point operations, FLOPS)和参数量(parameter count)的同时不断提高精度。但是就延迟latency而言,这些指标没有很好的与模型的效率关联起来,像FLOPs
深度学习-瓶颈结构(Bottleneck)
深度学习-瓶颈结构(Bottleneck)
人脸识别实战之基于开源模型搭建实时人脸识别系统(二):人脸检测概览与模型选型
进行人脸识别首要的任务就是要定位出画面中的人脸,这个任务就是人脸检测。人脸检测总体上算是目标检测的一个特殊情况,但也有自身的特点,比如角度多变,表情多变,可能存在各类遮挡。早期传统的方法有Haar Cascade、HOG等,基本做法就是特征描述子+滑窗+分类器,随着2012年Alexnet的出现,慢
AI数字人:语音驱动人脸模型Wav2Lip
2020年,来自印度海德拉巴大学和英国巴斯大学的团队,在ACM MM2020发表了的一篇论文《A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild 》,在文章中,他们提出一个叫做Wav2Lip的AI模型,
探索人工智能:深度学习、人工智能安全和人工智能编程(文末送书)
对人工智能三个方向的应用进行探讨,介绍机器人技术的历史、技术及应用。讲解一些更高级的计算机博弈技术,包括跳棋、国际象棋和其他博弈游戏。
毕业设计-基于深度学习的行人车辆闯红灯实时检测算法系统 YOLO python 卷积神经网络 人工智能
毕业设计-基于深度学习的行人和机动车闯红灯检测算法的毕业设计系统。该系统利用YOLOv5目标检测算法来实时监测交通场景中的行人和机动车,并通过红绿灯分类模型判断是否存在闯红灯行为。设计系统具有高效准确的检测能力,并能及时提供违规行为的警示。该算法系统不仅为交通管理提供了重要的辅助工具,也为实现智慧城
【多模态】4、Chinese CLIP | 专为中文图文匹配设计
本文主要介绍 Chinese CLIP



