
1.简单CNN改进
简单的CNN实现——MNIST手写数字识别
该部分首先对我前面的工作进行了改进,然后以此为基础构建ResNet18去实现MNIST手写数字识别。
1.改进要点:
1.利用nn.Sequential()自定义块结构,增加可读性和方便修改、复用。
2.增加 nn.BatchNorm2d() 加快收敛。
3.改用nn.Flatten()进行特征图展平。
4.设置nn.ReLU()的参数inplace = True,效率更好
改进代码如下:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Super parameter
batch_size =64
lr =0.01
momentum =0.5
epoch =10# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# Design modelclassNet(nn.Module):def__init__(self):super(Net, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(1,10,5),
nn.MaxPool2d(2),
nn.ReLU(True),
nn.BatchNorm2d(10),)
self.block2 = nn.Sequential(
nn.Conv2d(10,20,5),
nn.MaxPool2d(2),
nn.ReLU(True),
nn.BatchNorm2d(20),)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(320,10))defforward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.fc(x)return x
model = Net()# Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)# Train and Testdeftrain():for(images, target)in train_loader:
outputs = model(images)
loss = criterion(outputs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()deftest():
correct, total =0,0with torch.no_grad():for(images, target)in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct +=(predicted == target).sum().item()print('[%d / %d]: %.2f %% '%(i +1, epoch,100* correct / total))# Start train and Testprint('Accuracy on test set:')for i inrange(epoch):
train()
test()
改进后在测试集上的识别准确率:
Accuracy on test set:[1/10]:97.74%[2/10]:98.34%[3/10]:98.60%[4/10]:98.71%[5/10]:98.98%[6/10]:98.96%[7/10]:98.95%[8/10]:99.06%[9/10]:99.06%[10/10]:99.11%
结论:改进后相比于改进前收敛速度更快,且准确率得到了普遍提高。
2.利用云GPU平台,我们获得了了一个GPU,对前面的CPU版本进行改进,加快训练速度:
1.申明使用GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
2.把model放到GPU上
model.to(device)
3.把数据和标签放到GPU上
mages, target = images.to(device), target.to(device)
4.增大batch_size ,同时学习率也按相同倍数增加
5.DataLoader中设置参数
num_workers=4,pin_memory=True
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')# Super parameter
batch_size =256
lr =0.04
momentum =0.5
epoch =20# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=4,pin_memory=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False,num_workers=4,pin_memory=True)# Design modelclassNet(nn.Module):def__init__(self):super(Net, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(1,10,5),
nn.MaxPool2d(2),
nn.ReLU(True),
nn.BatchNorm2d(10),)
self.block2 = nn.Sequential(
nn.Conv2d(10,20,5),
nn.MaxPool2d(2),
nn.ReLU(True),
nn.BatchNorm2d(20),)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(320,10))defforward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.fc(x)return x
model = Net()
model.to(device)# Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)# Train and Testdeftrain():for images, target in train_loader:
images, target = images.to(device), target.to(device)
outputs = model(images)
loss = criterion(outputs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()deftest():
correct, total =0,0with torch.no_grad():for images, target in test_loader:
images, target = images.to(device), target.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct +=(predicted == target).sum().item()print('[%d / %d]: %.2f %% '%(i +1, epoch,100* correct / total))# Start train and Testprint('Accuracy on test set:')for i inrange(epoch):
train()
test()
结果如下:
Accuracy on test set:[1/20]:97.79%[2/20]:98.50%[3/20]:98.74%[4/20]:98.60%[5/20]:98.89%[6/20]:98.81%[7/20]:98.96%[8/20]:98.96%[9/20]:99.05%[10/20]:98.98%[11/20]:99.06%[12/20]:98.92%[13/20]:99.00%[14/20]:99.07%[15/20]:98.99%[16/20]:98.95%[17/20]:99.05%[18/20]:99.05%[19/20]:99.04%[20/20]:99.01%
结论:使用GPU训练相比于使用CPU,在正确的参数设置下,训练速度有了成倍的提升。
3 .可视化改进
1.利用tensorboard 进行训练过程的可视化。
2.增加一个计时器,记录训练和测试整个过程的时耗,求出平均时间
import torch
import time
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
from math import ceil
writer = SummaryWriter("tf-logs")
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')# Super parameter
batch_size =512
lr =0.04
momentum =0.5
total_epoch =20# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=4)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False,num_workers=4)# Design modelclassNet(nn.Module):def__init__(self,num_classes=10):super(Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,10,5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.BatchNorm2d(10),)
self.layer2 = nn.Sequential(
nn.Conv2d(10,20,5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.BatchNorm2d(20),)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(320, num_classes))defforward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.fc(out)return out
model = Net().to(device)# Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)# Train and Testdeftrain(epoch):for i ,(images, labels)inenumerate(train_loader):
correct, total =0,0
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()# Visualization of training
_, predicted = torch.max(outputs.data, dim=1)
total = labels.size(0)
correct =(predicted == labels).sum().item()
batch_num = ceil(len(train_dataset)/batch_size)*epoch+i
writer.add_scalar("acc_train/batch_num",100*correct / total,batch_num)deftest():
model.eval()
correct, total =0,0with torch.no_grad():for i ,(images, labels)inenumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct +=(predicted == labels).sum().item()print('[%d]: %.2f %%'%(epoch +1,100* correct / total))# Start train and Testprint('Accuracy on test set(epoch=%d):'%(total_epoch))
start=time.time()for epoch inrange(total_epoch):
train(epoch)
test()
end = time.time()print('Average time per epoch:%.2f s'%((end-start)/total_epoch))
writer.close()
结果:
Accuracy on test set(epoch=20):[1]:97.29%[2]:97.88%[3]:98.44%[4]:98.46%[5]:98.55%[6]:98.81%[7]:98.75%[8]:98.69%[9]:98.61%[10]:98.95%[11]:99.03%[12]:98.84%[13]:98.86%[14]:98.95%[15]:98.20%[16]:98.91%[17]:98.90%[18]:98.96%[19]:99.01%[20]:99.00%
Average time per epoch:5.77 s

4.突破0.995
1.数据增强
2.dropout
3.加深网络
4.动态学习率
5.权重初始化
import torch
import time
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
from math import ceil
from torch.optim import lr_scheduler
writer = SummaryWriter("tf-logs")
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')# Super parameter
batch_size =512
lr =0.001
momentum =0.5
total_epoch =100# Prepare dataset
transform = transforms.Compose([transforms.RandomAffine(degrees=0, translate=(0.1,0.1)),
transforms.RandomRotation((-10,10)),
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4,pin_memory=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4,pin_memory=True)defweight_init(m):ifisinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')# Design modelclassNet(nn.Module):def__init__(self, num_classes=10):super(Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,32,5),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32,32,5),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.MaxPool2d(2,2),
nn.Dropout(0.25))
self.layer2 = nn.Sequential(
nn.Conv2d(32,64,3),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64,64,3),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2,2),
nn.Dropout(0.25))
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(64*3*3,256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256,num_classes))defforward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.fc(out)return out
model = Net().to(device)
model.apply(weight_init)# Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.RMSprop(model.parameters(),lr=lr,alpha=0.99,momentum = momentum)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=3, verbose=True, threshold=0.00005, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)# Train and Testdeftrain(epoch):for i,(images, labels)inenumerate(train_loader):
correct, total =0,0
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()# Visualization of training
_, predicted = torch.max(outputs.data, dim=1)
total = labels.size(0)
correct =(predicted == labels).sum().item()
batch_num = ceil(len(train_dataset)/ batch_size)* epoch + i
writer.add_scalar("acc_train/batch_num",100* correct / total, batch_num)deftest():
model.eval()
correct, total =0,0with torch.no_grad():for i,(images, labels)inenumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct +=(predicted == labels).sum().item()print('[%d]: %.2f %%'%(epoch +1,100* correct / total))# Start train and Testprint('Accuracy on test set(epoch=%d):'%(total_epoch))
start = time.time()for epoch inrange(total_epoch):
train(epoch)
test()
end = time.time()print('Average time per epoch:%.2f s'%((end - start)/ total_epoch))
writer.close()
Accuracy on test set(epoch=100):...[80]:99.34%[81]:99.26%[82]:99.24%[83]:99.26%[84]:99.31%[85]:99.51%[86]:99.37%[87]:99.30%[88]:99.35%[89]:99.29%[90]:99.29%[91]:99.35%[92]:99.40%[93]:99.20%[94]:99.42%[95]:99.37%[96]:99.31%[97]:99.31%[98]:99.41%[99]:99.34%[100]:99.30%
Average time per epoch:6.89 s
结论:可以看到我们在第85轮训练中达到了0.9951的测试集准确度!
2.模型设计与实现
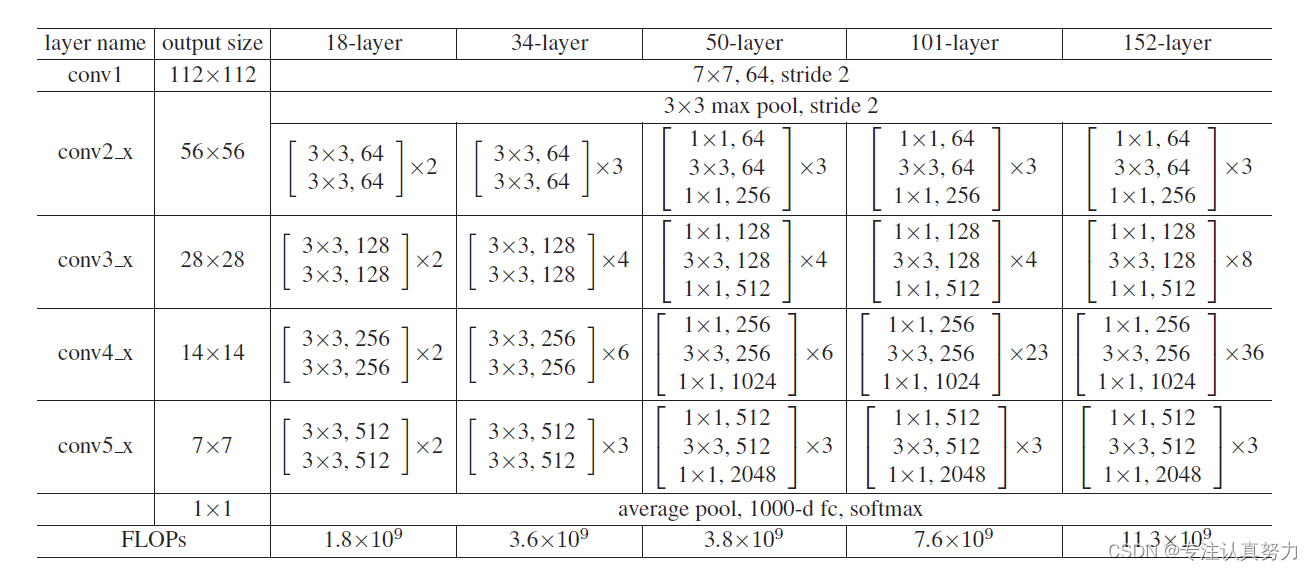
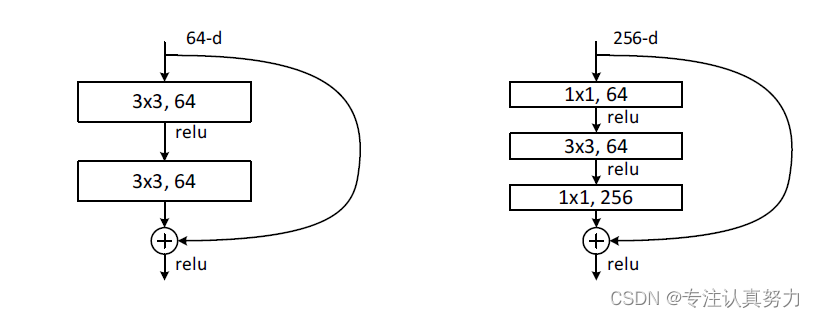
按照模型结构设计如下代码实现ResNet18:
import time
import torch
import torch.nn as nn
import torchvision.models as models
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
from math import ceil
writer = SummaryWriter("tf-logs")
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')# Super parameter
batch_size =512
lr =0.04
momentum =0.5
total_epoch =20# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)defconv3x3(in_channels, out_channels, stride=1):return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=True)classResidualBlock(nn.Module):def__init__(self, in_channels, out_channels, stride=1, downsample=None):super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
defforward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)return out
classResNet(nn.Module):def__init__(self, block, layers, num_classes=10):super(ResNet, self).__init__()
self.in_channels =16
self.conv = conv3x3(1,16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block,16, layers[0], stride=1)
self.layer2 = self.make_layer(block,32, layers[1],2)
self.layer3 = self.make_layer(block,64, layers[2],2)
self.avg_pool = nn.AvgPool2d(8)
self.fc1 = nn.Linear(3136,128)
self.normfc12 = nn.LayerNorm((128), eps=1e-5)
self.fc2 = nn.Linear(128, num_classes)defmake_layer(self, block, out_channels, blocks, stride=1):
downsample =Noneif(stride !=1)or(self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels))
layers =[]
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for i inrange(1, blocks):
layers.append(block(out_channels, out_channels))return nn.Sequential(*layers)defforward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0),-1)
out = self.fc1(out)
out = self.normfc12(out)
out = self.relu(out)
out = self.fc2(out)return out
# [2,2,2]表示的是不同in_channels下的恒等映射数目
model = ResNet(ResidualBlock,[2,2,2]).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)# Train and Testdeftrain(epoch):for i,(images, labels)inenumerate(train_loader):
correct, total =0,0
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()# Visualization of training
_, predicted = torch.max(outputs.data, dim=1)
total = labels.size(0)
correct =(predicted == labels).sum().item()
batch_num = ceil(len(train_dataset)/ batch_size)* epoch + i
writer.add_scalar("acc_train/batch_num",100* correct / total, batch_num)deftest():
model.eval()
correct, total =0,0with torch.no_grad():for i,(images, labels)inenumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct +=(predicted == labels).sum().item()print('[%d]: %.2f %%'%(epoch +1,100* correct / total))# Start train and Testprint('Accuracy on test set(epoch=%d):'%(total_epoch))
start = time.time()for epoch inrange(total_epoch):
train(epoch)
test()
end = time.time()print('Average time per epoch:%.2f s'%((end - start)/ total_epoch))
writer.close()
输出结果如下:
Accuracy on test set(epoch=20):[1]:98.39%[2]:96.72%[3]:98.31%[4]:97.88%[5]:98.70%[6]:98.57%[7]:98.18%[8]:98.99%[9]:99.21%[10]:99.06%[11]:98.88%[12]:99.12%[13]:99.22%[14]:99.13%[15]:98.82%[16]:99.00%[17]:99.24%[18]:99.20%[19]:99.26%[20]:99.30%
Average time per epoch:14.43 s
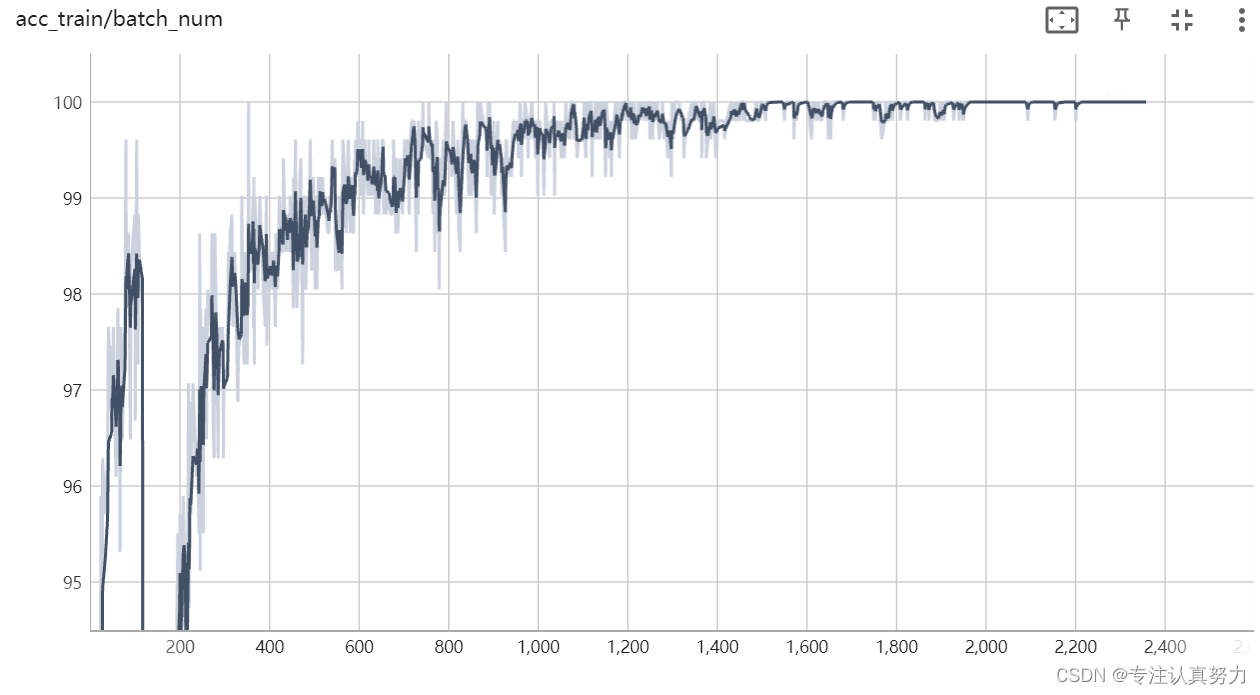
3.torchvision实现的resnet18
我们知道 学习过程 = 数据集 + 模型 + 训练测试,三个部分的耦合性很低,可以模块化。
现在我们将自己实现的resnet18模型替换为torchvision实现的,要注意的点只有一个,就是这个模型接收的是三通道的图片,而我们的MNIST数据集是单通道的,所以在需要进行预处理
images = images.expand(-1, 3, -1, -1)
,然后其他两个模块基本不需要改变。
import time
import torch
import torch.nn as nn
import torchvision.models as models
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
from math import ceil
writer = SummaryWriter("tf-logs")
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')# Super parameter
batch_size =512
lr =0.001
momentum =0.5
total_epoch =50# Prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)# Construct model
model = models.resnet18().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)# Train and Testdeftrain(epoch):for i,(images, labels)inenumerate(train_loader):
correct, total =0,0
images = images.expand(-1,3,-1,-1)
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()# Visualization of training
_, predicted = torch.max(outputs.data, dim=1)
total = labels.size(0)
correct =(predicted == labels).sum().item()
batch_num = ceil(len(train_dataset)/ batch_size)* epoch + i
writer.add_scalar("acc_train/batch_num",100*round(correct / total,4), batch_num)deftest():
model.eval()
correct, total =0,0with torch.no_grad():for i,(images, labels)inenumerate(test_loader):
images, labels = images.to(device), labels.to(device)
images = images.expand(-1,3,-1,-1)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct +=(predicted == labels).sum().item()print('[%d]: %.2f %%'%(epoch +1,100* correct / total))# Start train and Testprint('Accuracy on test set(epoch=%d):'%(total_epoch))
start = time.time()for epoch inrange(total_epoch):
train(epoch)
test()
end = time.time()print('Average time per epoch:%.2f s'%((end - start)/ total_epoch))
writer.close()
输出结果:
Accuracy on test set(epoch=50):...[30]:98.28%[31]:98.28%[32]:98.25%[33]:98.26%[34]:98.29%[35]:98.28%[36]:98.26%[37]:98.27%[38]:98.34%[39]:98.27%[40]:98.34%[41]:98.32%[42]:98.33%[43]:98.33%[44]:98.32%[45]:98.30%[46]:98.30%[47]:98.34%[48]:98.31%[49]:98.35%[50]:98.36%
Average time per epoch:6.75 s
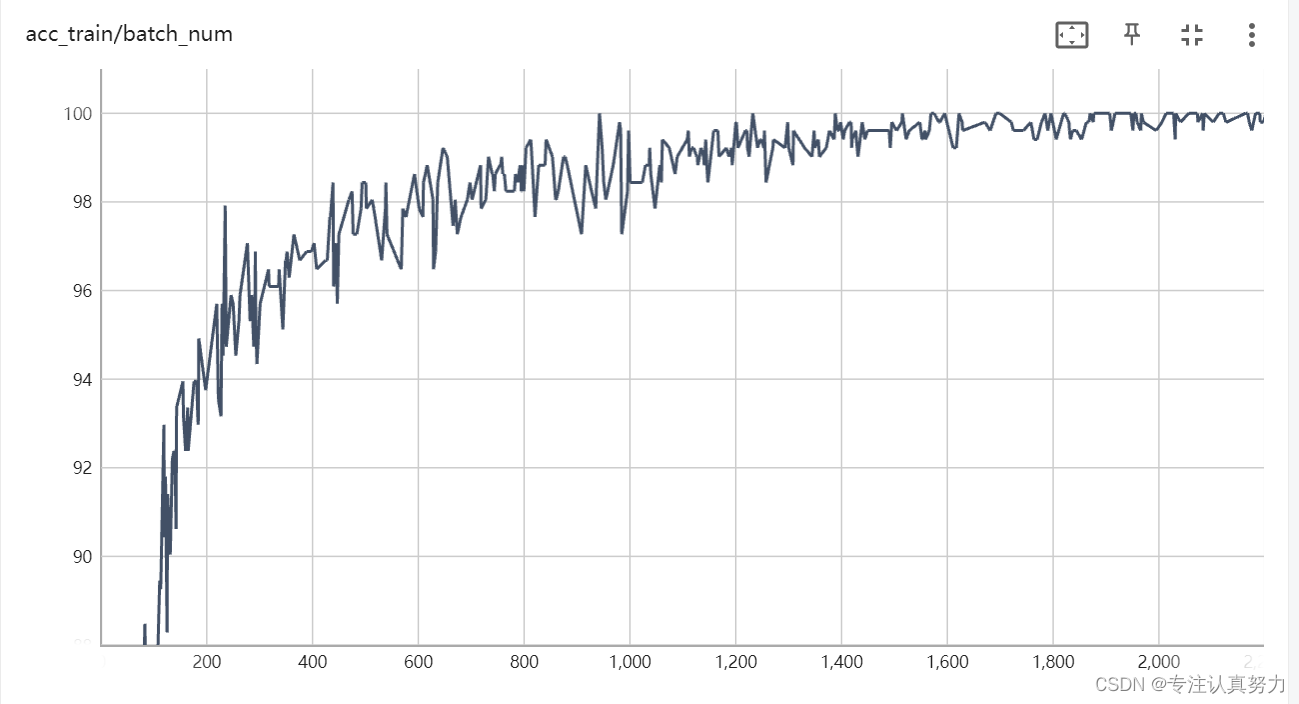
替换为resnet101,锻炼一下GPU。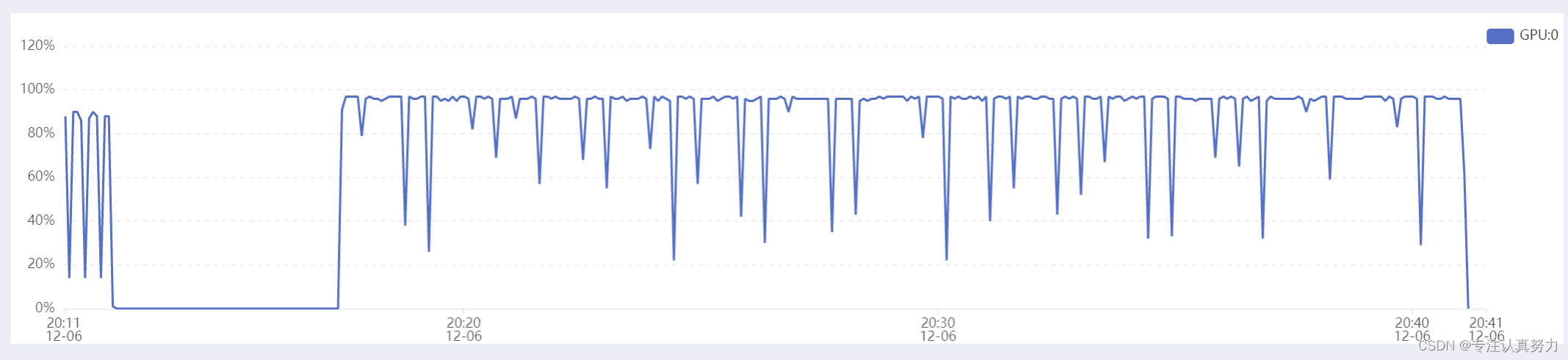
输出结果如下:
Accuracy on test set(epoch=50):...[30]:97.49%[31]:97.52%[32]:97.48%[33]:97.47%[34]:97.48%[35]:97.50%[36]:97.49%[37]:97.50%[38]:97.50%[39]:97.52%[40]:97.49%[41]:97.49%[42]:97.51%[43]:97.49%[44]:97.51%[45]:97.51%[46]:97.51%[47]:97.50%[48]:97.50%[49]:97.50%[50]:97.50%
Average time per epoch:28.44 s
本文转载自: https://blog.csdn.net/m0_46692607/article/details/128184809
版权归原作者 专注认真努力 所有, 如有侵权,请联系我们删除。
版权归原作者 专注认真努力 所有, 如有侵权,请联系我们删除。