
合合信息TextIn(Text Intelligence)团队在2023年12月31日参与了中国图象图形学学会青年科学家会议 - 垂直领域大模型论坛。在会议上,丁凯博士分享了文档图像大模型的思考与探索,完整阐述了多模态大模型在文档图像领域的发展与探索,并表达了对未来发展路径和应用场景潜力的看法。
目录
一、合合TextIn(Text Intelligence)研究团队
1.1 研究团队介绍
合合TextIn(Text Intelligence)研究团队,经过16年的专注和深耕于智能文档处理领域,已经在智能文档图像处理、文档解析与识别、版面分析与还原、文档信息抽取与理解、文档安全等全方位的智能文档处理(Intelligent Document Processing)技术上取得显著成就。这一团队不仅获得了117个国内外发明专利,还在16项顶级AI竞赛中获得了世界冠军,对智能文档领域做出了杰出贡献。他们发布的名片全能王、扫描全能王和TextIn智能文档处理云平台textin.com正为全球的用户和企业提供卓越服务。
1.2 研究方向介绍
尽管大模型技术,特别是GPT4-V Gemini等新技术的快速发展,已经极大地推动了技术界的进步,但领域内的核心问题依然存在。在智能文档处理(IDP)领域,有四个主要问题仍然是合合TextIn团队关注的重点。随着大模型技术的出现和发展,我们对技术的期望已经升级,寻求更高效、更精准的解决方案来应对这些长期存在的挑战。

合合TextIn团队在智能文档处理技术领域进行了广泛而深入的研究,涵盖了文档图像分析与预处理、文档解析与识别、版面分析与还原、文档信息抽取与理解、AI安全以及知识化、存储检索和管理等多个关键技术。这些技术的研究不仅彰显了团队的专业能力,而且取得了丰富的成果,极大地推动了智能文档处理领域的发展。
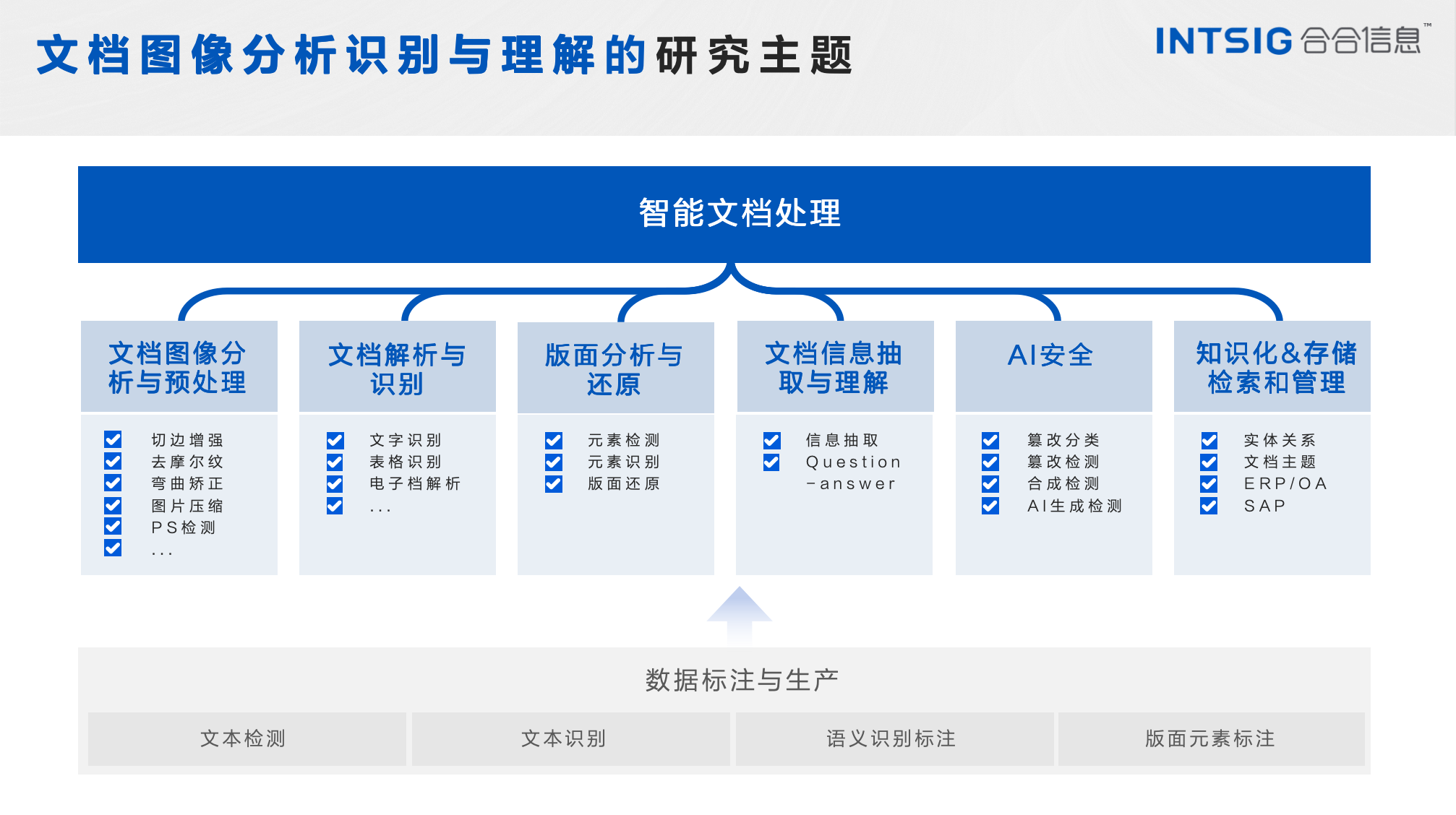
1.3 TextIn产品发布
合合TextIn团队推出了TextIn智能文档处理云平台,一个创新性的解决方案,旨在将他们的研究成果以多样化的形式提供给全球用户和企业。通过访问textin.com,用户可以体验到这个平台如何高效、智能地处理文档,从而满足各种文档管理需求。
二、合合TextIn团队对GPT-4V在文档领域的表现看法
2023年12月31日,合合TextIn团队丁凯博士参加中国图象图形学学会青年科学家会议 - 垂直领域大模型论坛,在论坛上充分展现了GPT-4V在文档领域的表现。
OpenAI最近发布了GPT-4V(ision),这是一个划时代的大型多模态模型(LMM),它代表了GPT-4在多模态交互方面的重大进步。GPT-4V不仅处理文本,还整合了图像和声音等多种数据类型的输入,显著提升了模型的理解和推理能力。丁凯博士在介绍中强调,与传统方法相比,GPT-4V能够进行更全面的文档和图像分析。它不依赖预定义的规则,而是通过学习大量数据来捕捉复杂的上下文关系和特征表示。这种方法在理解和处理多模态内容方面表现出优越性,能够同时处理文本和图像信息,提供更全面和准确的结果。此外,GPT-4V的架构和训练方式具有高度的灵活性和可扩展性,可根据不同任务和需求进行调整。相比之下,传统的数据处理方法往往局限于特定的算法和流程,难以适应多变的应用场景。GPT-4V的推出不仅标志着OpenAI在多模态技术领域的新突破,也为推动通用智能的发展开辟了新道路。

2.1 很强
GPT4-V多模态大模型大幅度提升了AI技术在文档分析与识别领域的能力边界,端到端实现了文档的识别到理解的全过程。支持端到端解决识别和理解问题,认知能力强,支持识别和理解的文档元素类型远超传统IDP算法。
丁凯博士在会议中展示了GPT-4V在智能文档处理(IDP)领域的强大表现:
支持多种场景的文字识别

支持手写和公式识别

支持表格识别

支持卡证、票据识别

2.2 但还不够
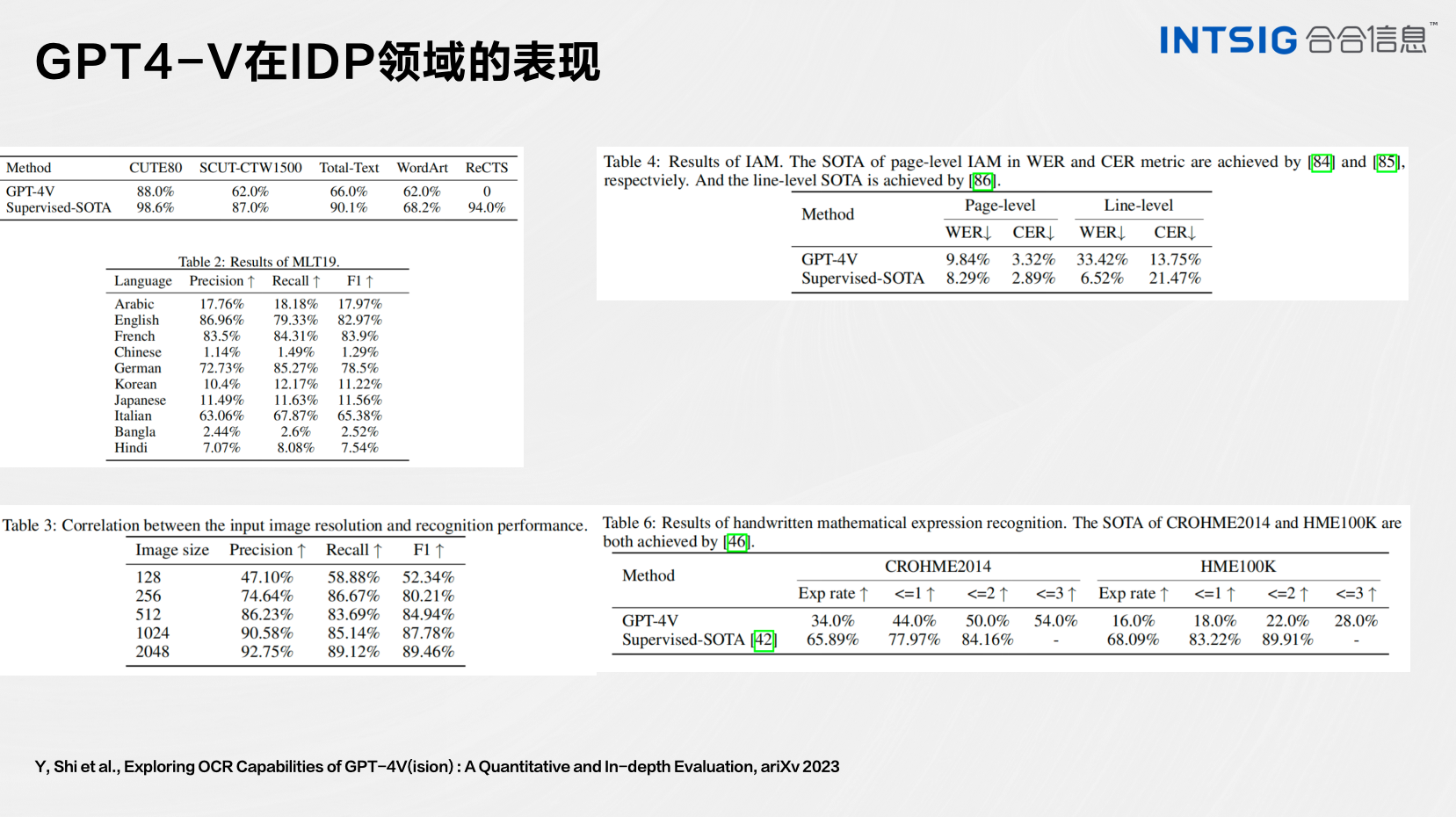
丁凯博士在会议中展示了GPT-4V在IDP领域的评测结果,表达虽然看到了其强大的能力,但是在OCR精度距离SOTA有较大差距,以及长文档依赖外部的OCR/文档解析引擎。
GPT-4V,尽管在认知领域展现潜能,却在智能文档处理任务中遭遇技术障碍。丁凯博士强调,该模型面临“幻觉现象”——不当地将文字内容与图像细节相结合,导致判断失误和内容产生偏差,特别是在处理手写中文诗歌时尤为明显。一项对GPT-4V在光学字符识别(OCR)能力的综合评估表明,尽管它能有效处理拉丁字符并适应不同分辨率的图像,但在解析多语言文本和复杂视觉场景时仍面临挑战。此外,模型运行的高成本和持续迭代的复杂性也对其广泛应用构成了阻碍。因此,专用OCR系统在这一领域仍具备关键价值。
多模态大型模型在密集文本领域的应用受限,主要由于其侧重于基于文本的语义分析,而在视觉数据解析方面能力不足。例如,面对细粒度文本处理(如细小的签名、复杂的古文字),由于受视觉感知和文字辨识能力的限制,传统的语言模型无法有效应对。为了突破这些限制,需要进一步的研究探索和技术创新。
三、合合TextIn团队在文档图像多模态大模型领域最新研究成果
合合信息与华南理工大学联合实验室共同研究,针对多模态大模型目前针对OCR仍无法达到SOTA的问题,提出了两个在文档图像多模态大模型上的研究成果。
3.1 像素级OCR统一模型 UPOCR: Towards Unified Pixel-Level OCR Interface
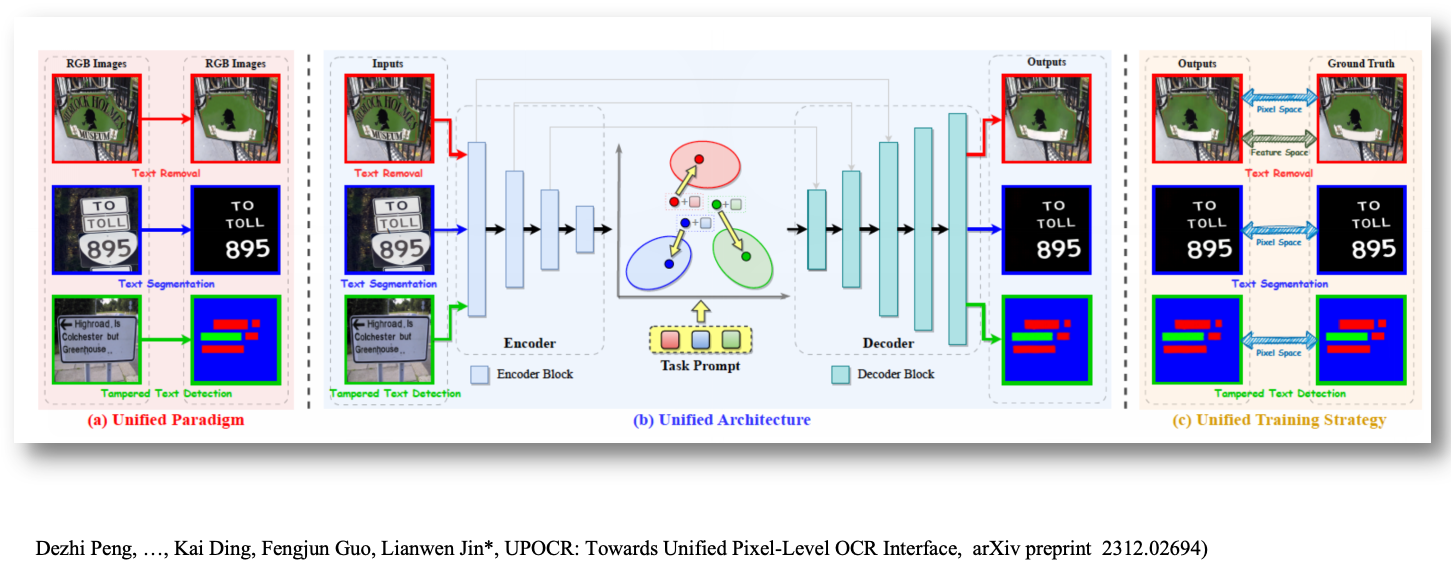
第一个研究成果是UPOCR,一种文档图像像素级多任务处理的统一模型。模型如图所示,UPOCR是一个通用的OCR模型,引入可学习的Prompt来指导基于ViT的编码器-解码器架构,统一了不同像素级OCR任务的范式、架构和训练策略。 UPOCR的通用能力在文本去除、文本分割和篡改文本检测任务上得到了广泛验证,显著优于现有的专门模型。
- UPOCR是一个通用的OCR模型,统一了不同像素级OCR任务的范式、架构和训练策略
- 引入可学习的任务提示来指导基于ViT的编码器-解码器架构
- UPOCR的通用能力在文本擦除、文本分割和篡改文本检测任务上得到了广泛验证,显著优于现有的专门模型
这是文本擦除、分割、及篡改检测与现有子任务的SOTA方法的可视化对比图,可见方法取得了更优异的效果
3.2 OCR大一统模型相关研究
丁凯博士在会议中展示了另外一个研究成果,针对OCR大一统模型相关的研究范式概述,以及近期OCR大一统模型相关的研究成果
- 将文档图像识别分析的各种任务定义为序列预测的形式
- 文本,段落,版面分析,表格,公式等等
- 通过不同的prompt引导模型完成不同的OCR任务
- 支持篇章级的文档图像识别分析,输出Markdown/HTML/Text等标准格式
- 将文档理解相关的工作交给LLM去做
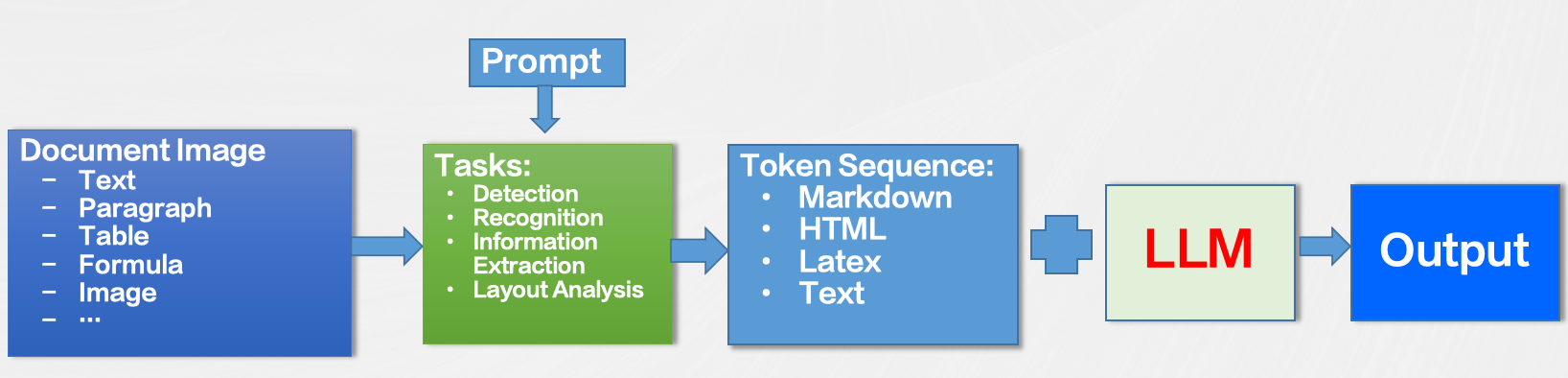
四、合合TextIn团队对LLM在文档领域应用的探索
丁凯博士在会议分享的最后,展示了合合TextIn团队对于多模态大模型在文档领域应用的范式与应用洞见,该范式包含以下几个关键步骤:
新闻简报:
- 文档图像输入:技术首先处理文档的图像形式,包括扫描的纸质文件、拍照的照片,或电子文档的页面图像。
- 文档识别与版面分析:在此阶段,系统会识别文档中的文字、图片、表格等元素,并分析版面布局。这包括标题、段落、页眉和页脚,有助于理解文档的总体结构和内容组织。
- 文档切分和召回:技术将文档切分,分离不同部分的内容以便进一步处理。此外,实施召回策略来检索和提取特定元素,如标题、关键字和段落内容。
- 大语言模型问答应用:最后阶段,大语言模型问答用于文档中信息提取的问答任务。通过训练模型理解文档内容,实现智能理解和交互式查询,以回答用户提出的问题。
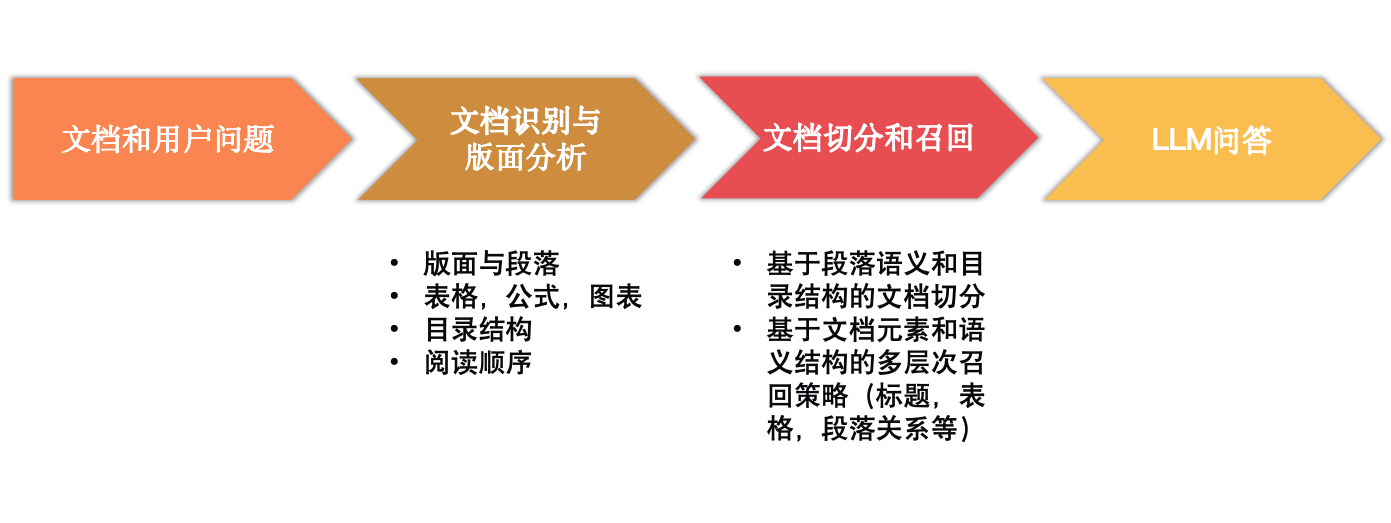
4.1 检索增强生成(RAG)和文档问答是LLM在文档领域最常见和最广泛的应用之一
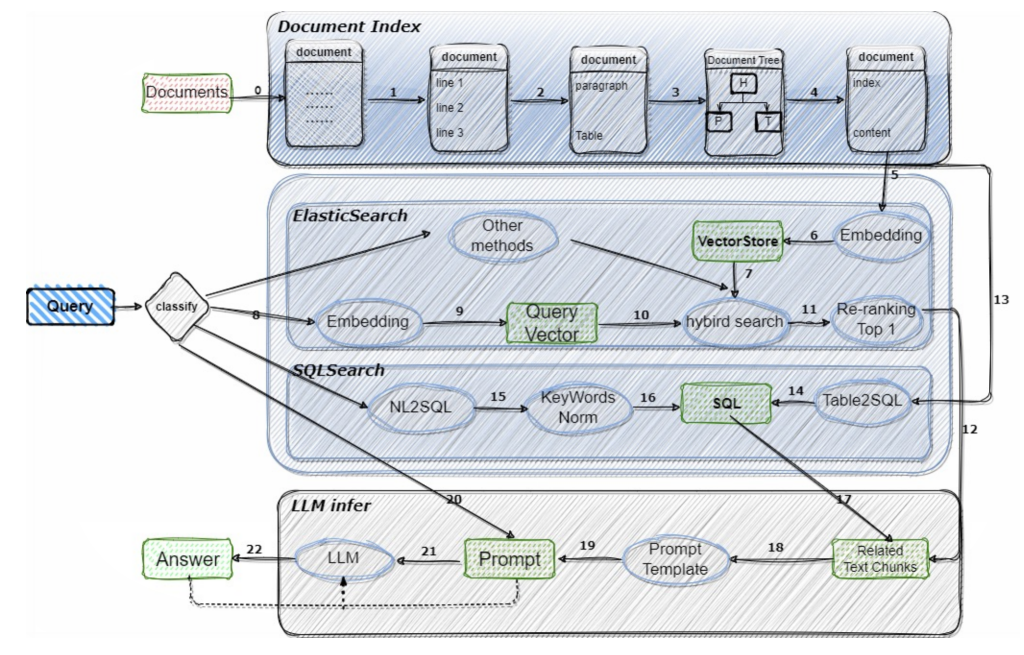
4.2 合合TextIn团队文档图像识别与分析产品发布
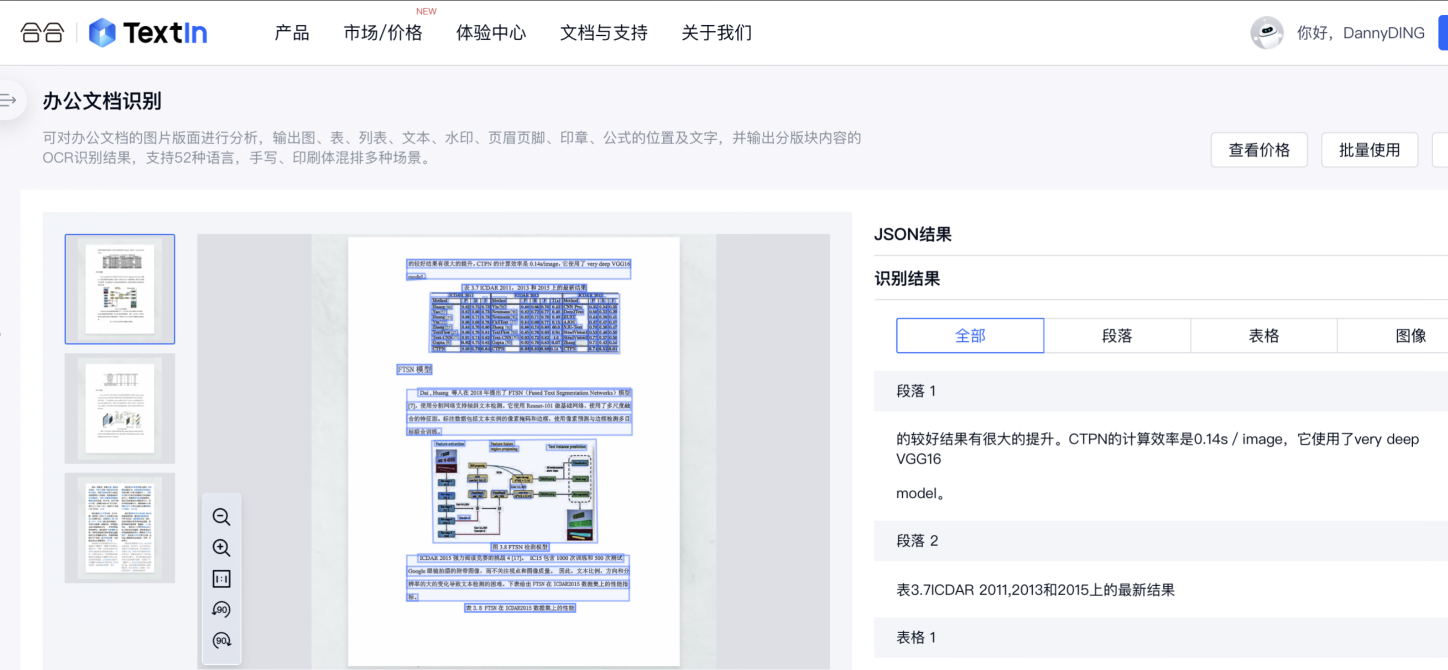
可与LLM做上下游的衔接和应用。该产品可对文档的图片版面进行分析,输出图、表、列表、文本、水印、页眉页脚、印章、公式的位置及文字,并输出分版块内容的OCR识别结果,支持52种语言,手写、印刷体混排多种场景。访问链接:https://www.textin.com/market/detail/document
五、文档图像多模态大模型发展未来趋势
最新技术动态显示,以GPT4-V为代表的多模态大模型技术在文档识别与分析领域取得了显著进展,为传统的图像文档处理技术带来了重大挑战。虽然大模型技术极大地推进了该领域的发展,但仍有许多待解决的问题,需要进一步的研究和探索。这些问题包括如何更好地结合大模型的能力来优化图像文档处理。展望未来,感知与认知的结合预计将为用户带来更智能化、高效率和个性化的文档处理体验。随着技术的不断进步,这种结合在商业、教育、科研等多个领域的应用将变得越来越重要。我们期待合合信息在模式识别、深度学习、图像处理和自然语言处理等领域的深入发展,以技术创新惠及更广泛的人群。
- GPT4-V 为代表的多模态大模型技术极大的推进了文档识别与分析领域的技术进展,也给传统的IDP技术带来了挑战
- 大模型并没有完全解决IDP领域面临的问题,很多问题值得我们研究
- 如何结合大模型的能力,更好的解决IDP的问题,值得我们做更多的思考和探索
六、京东卡抽奖!
填写问卷抽奖!赠送10人50元京东卡!合合TextIn团队提供给大家福利!

版权归原作者 TechLead KrisChang 所有, 如有侵权,请联系我们删除。