
1、三大经典的数据集
在计算机视觉领域中,有三个非常著名且常用的数据集,分别是ImageNet、MS COCO和PASCAL VOC
1.1 ImageNet
- 来源:由斯坦福大学的研究者李飞飞等人领导的团队创建
- 分类数量:包含1000个类别,每个类别大约有1000张图像,总共超过100万张经过标注的图像
- 用途:主要用于图像分类任务,但也被用于其他任务,如目标检测和深度学习模型的预训练
- 特点:ImageNet数据集的规模和多样性使其成为计算机视觉领域,尤其是深度学习领域中最重要的数据集之一,它推动了图像识别技术的发展,并被用于一年一度的ImageNet大规模视觉识别挑战(ILSVRC)
1.2 MS COCO
- 来源: 微软于2014年出资标注的Microsoft COCO数据集(Microsoft Common Objects in Context)
- 分类数量:包含80个类别,超过33万张图片,其中20万张有标注,整个数据集中个体的数目超过150万个,覆盖了日常生活中的常见物体
- 用途:支持多种视觉任务,包括目标检测、实例分割、语义分割和关键点检测
- 特点:MS COCO数据集以其复杂的日常场景和详尽的标注而闻名。它不仅提供了目标的边界框,还包括了目标的分割掩码和关键点标注,适合进行更高级的计算机视觉任务。
1.3 PASCAL VOC
- 来源: 由欧盟资助的PASCAL2 Network of Excellence on Pattern Analysis, Statistical Modelling and Computational Learning项目
- 分类数量:包含20个类别,11530张图片,总共27450个ROI标注对象和6929个分割标注
- 用途:最初是为了图像分类任务而创建的,后来扩展到目标检测、实例分割和语义分割任务
- 特点:PASCAL VOC数据集是计算机视觉领域较早的数据集之一,对目标检测技术的发展有重要影响,它包含的图像数量相对较少,但每个图像都经过了精心的标注,适合用于算法的验证和测试
2、三种经典的目标检测数据标注格式
目标检测的数据标注格式对于训练和评估目标检测模型至关重要,它提供了一种标准化的方式来定义图像中目标对象的位置,从而帮助模型更好地学习和识别目标物体,以此提高算法的准确性和泛化能力
常见的数据标注格式有yolo(.txt)、coco(.json)、voc(.xml)这三种,三种格式之间也可以通过一定的代码进行互相转换
2.1 YOLO格式
- 文件类型:使用
.txt文件存储标注信息 - 坐标表示:使用相对坐标,通过
cls_id, x_center, y_center, w, h表示,其中: -cls_id是类别ID-x_center, y_center是框中心点的坐标(这个坐标是一个相对坐标,即:相对于图像宽度和高度的百分比)-w, h是框的宽度和高度 - 特点:YOLO格式的相对坐标表示使得模型对图像尺寸变化更加鲁棒,适合于YOLO(You Only Look Once)目标检测算法
2.2 COCO格式
- 文件类型:使用
.json文件存储标注信息 - 坐标表示:使用原始坐标(像素值),通过
x, y, width, height表示,其中: -x, y是框中心点的坐标-width, height是框的宽度和高度 - 特点:COCO格式提供了丰富的信息,包括目标的边界框、分割掩码和关键点等,适合进行多任务学习,如目标检测、实例分割、语义分割和关键点检测
2.3 VOC格式
- 文件类型:使用
.xml文件存储标注信息 - 坐标表示:使用绝对坐标(像素值),通过
xmin, ymin, xmax, ymax表示,其中: -xmin, ymin表示左上角的坐标-xmax, ymax表示右下角的坐标 - 特点:这种格式简单直观,易于理解和使用,是PASCAL VOC挑战赛中使用的标准格式
3、数据标注工具
尽管有上面这些标准的数据标注格式,但在标注数据时,我们通常并不是直接在标注文件中手写内容,而是通过一些可视化的工具来进行标注,让工具帮我们生成对应的标注文件内容
数据标注的可视化工具有很多,比如: labelimg、makesense、x-anylabeling等等,下面将以labelimg为例,对其安装和使用的方法进行介绍
3.1 LabelImg的安装
由于labelimg是一个很早之前就被研发出来的工具,故其对python解释器的版本有一定的要求,即:最新支持到python3.8版本
所以,我们需要安装python3.8版本的解释器,才能顺畅地进行使用
为了便于管理自己电脑的python解释器,本文将通过anacoda来进行操作演示:
Step1: 以管理员模式打开anaconda prompt
Step2: 执行如下命令,创建python3.8的环境:
conda create --name py38 python=3.8
Step3: 执行如下命令,进入刚创建的python3.8环境:
conda activate py38

Step4: 执行如下命令,安装/升级labelimg:
pip install labelimg -U
Step5: 执行如下命令,退出python3.8环境,返回base环境:
conda deactivate

3.2 LabelImg的使用
3.2.1 准备工作
在自然界中,万事万物都有类别,而我们的数据标注通常是针对具体的业务场景,业务场景中不会包含万事万物的识别
因此,我们需要先定义所需要识别的目标类别,使得我们可以在labelimg标注目标时,选择对应的类别
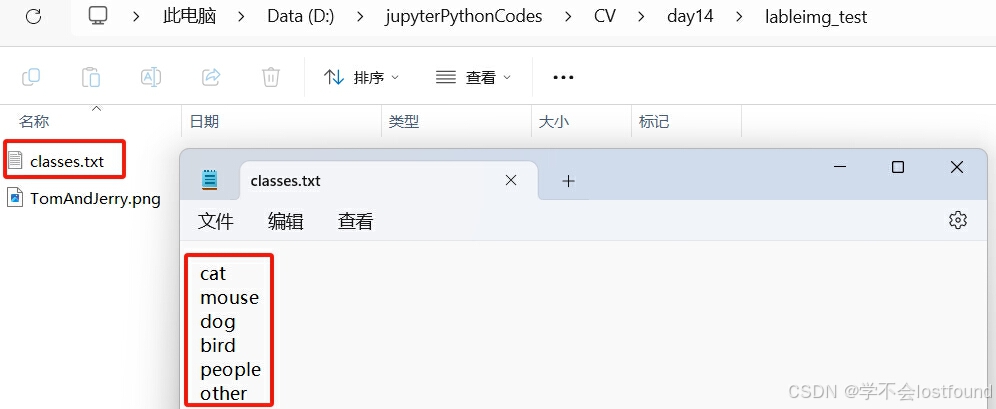
对于labelimg而言,类别的可选项,通常需要放到一个txt文件中,并将每个类别独占一行
以《猫和老鼠》这个动画片为例,里面经常出现汤姆猫、杰瑞鼠、斯派克狗、啄木鸟、汤姆猫的主人等生物(猫、鼠、狗、鸟、人、其他),我们可以定义一个类别标识文件(classes.txt),并填入这些类别,如下图所示:
3.2.2 开始使用
Step1: 以管理员模式打开anaconda prompt
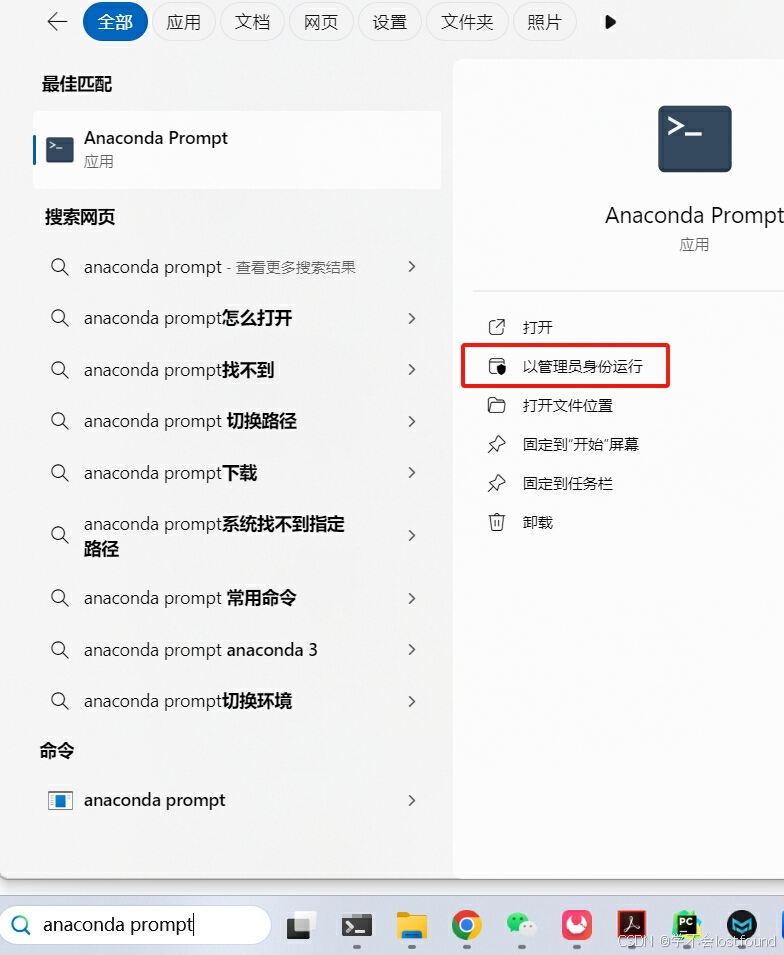
Step2: 执行如下命令,进入之前创建的python3.8环境:
conda activate py38

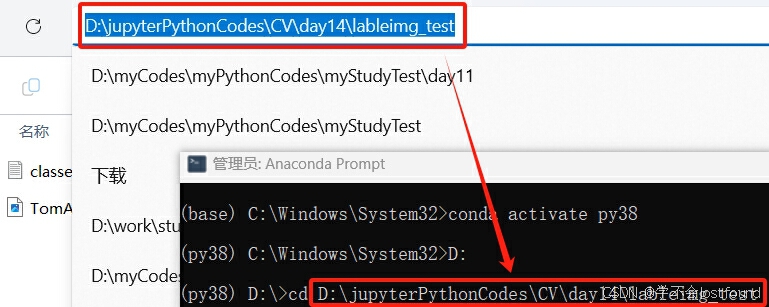
Step3: 执行如下命令,进入classes.txt文件对应的目录中:
由于anaconda prompt打开后默认是在C盘,如果我们的文件在D盘(比如我的示例文件在D:\jupyterPythonCodes\CV\day14\lableimg_test),那么就需要先切换盘符,再进入对应的目录中(即:依次执行以下命令)
D:
cd D:\jupyterPythonCodes\CV\day14\lableimg_test
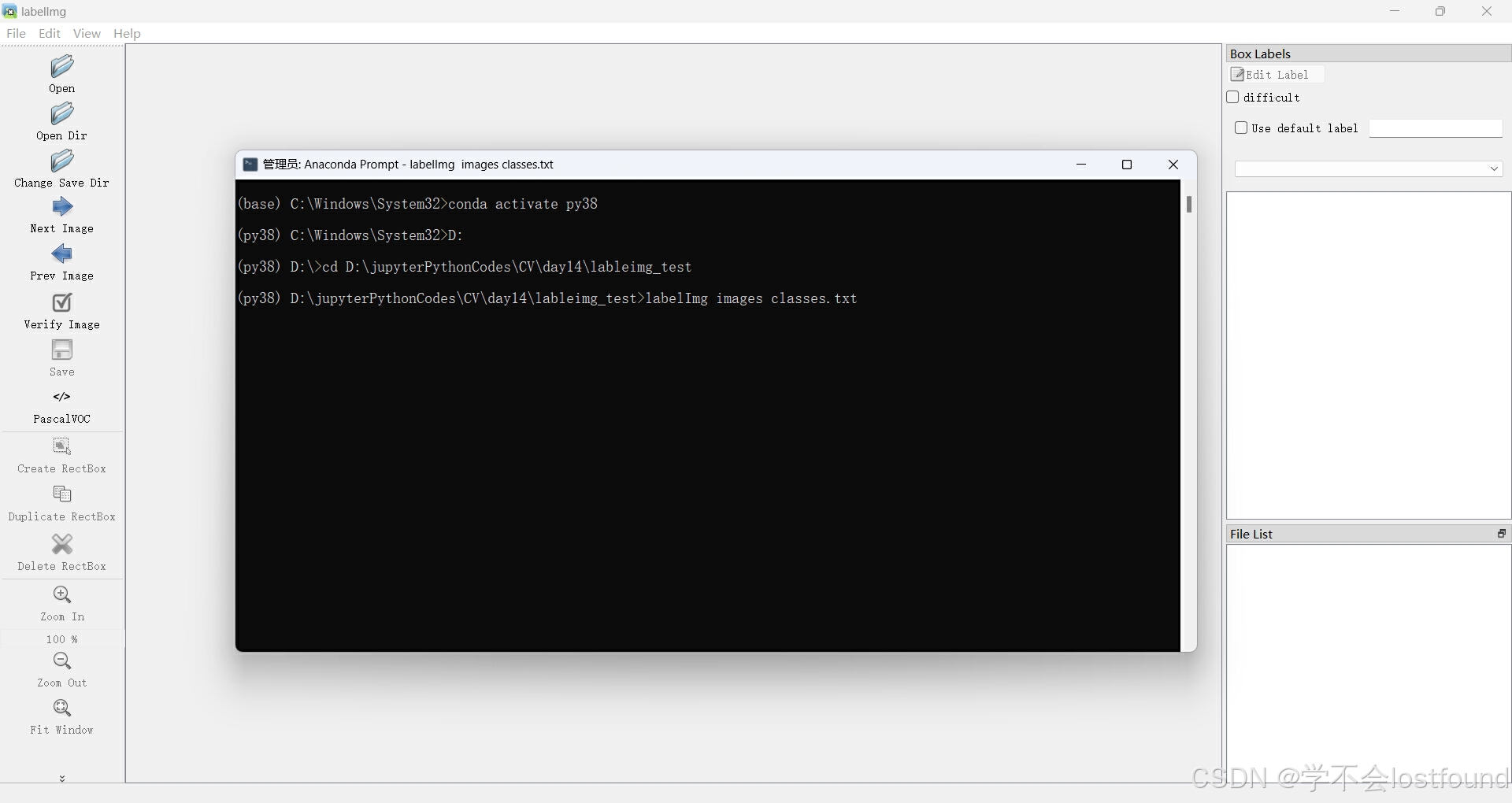
Step4: 执行如下命令,打开labelimg界面:
labelImg images classes.txt
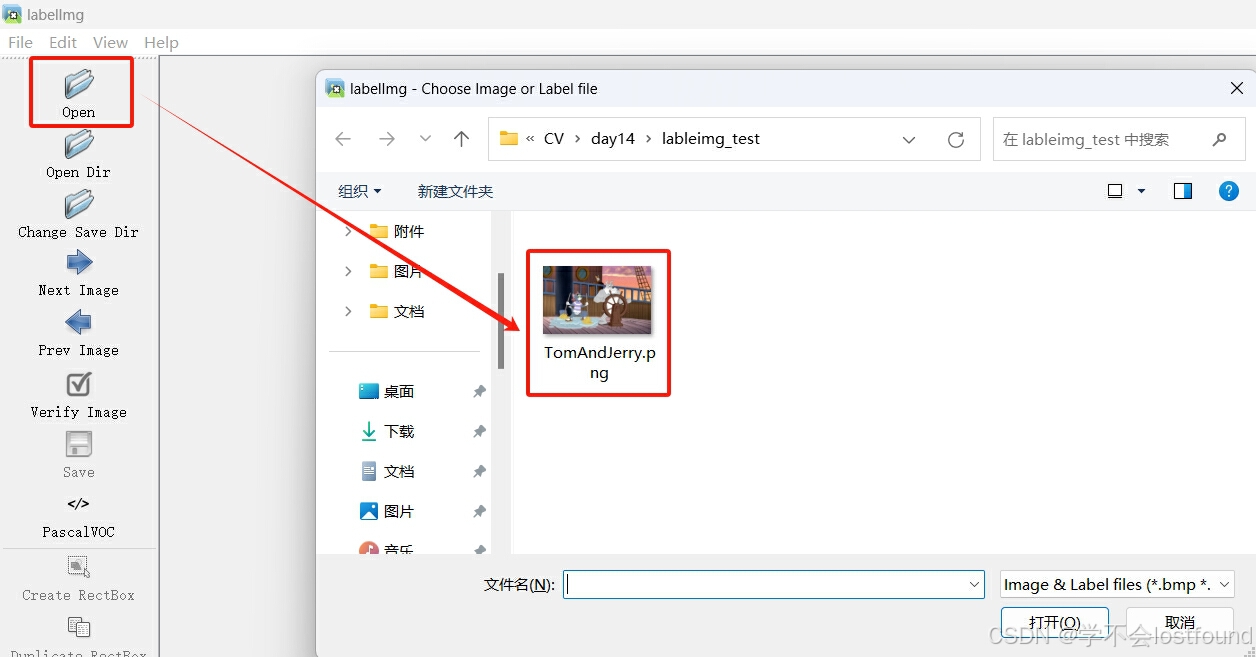
Step5: 通过【Open】按钮,打开需要进行标注的图片
Step6: 通过【Create RectBox】按钮,对图片中的目标物进行边框标注,并选择对应的标签
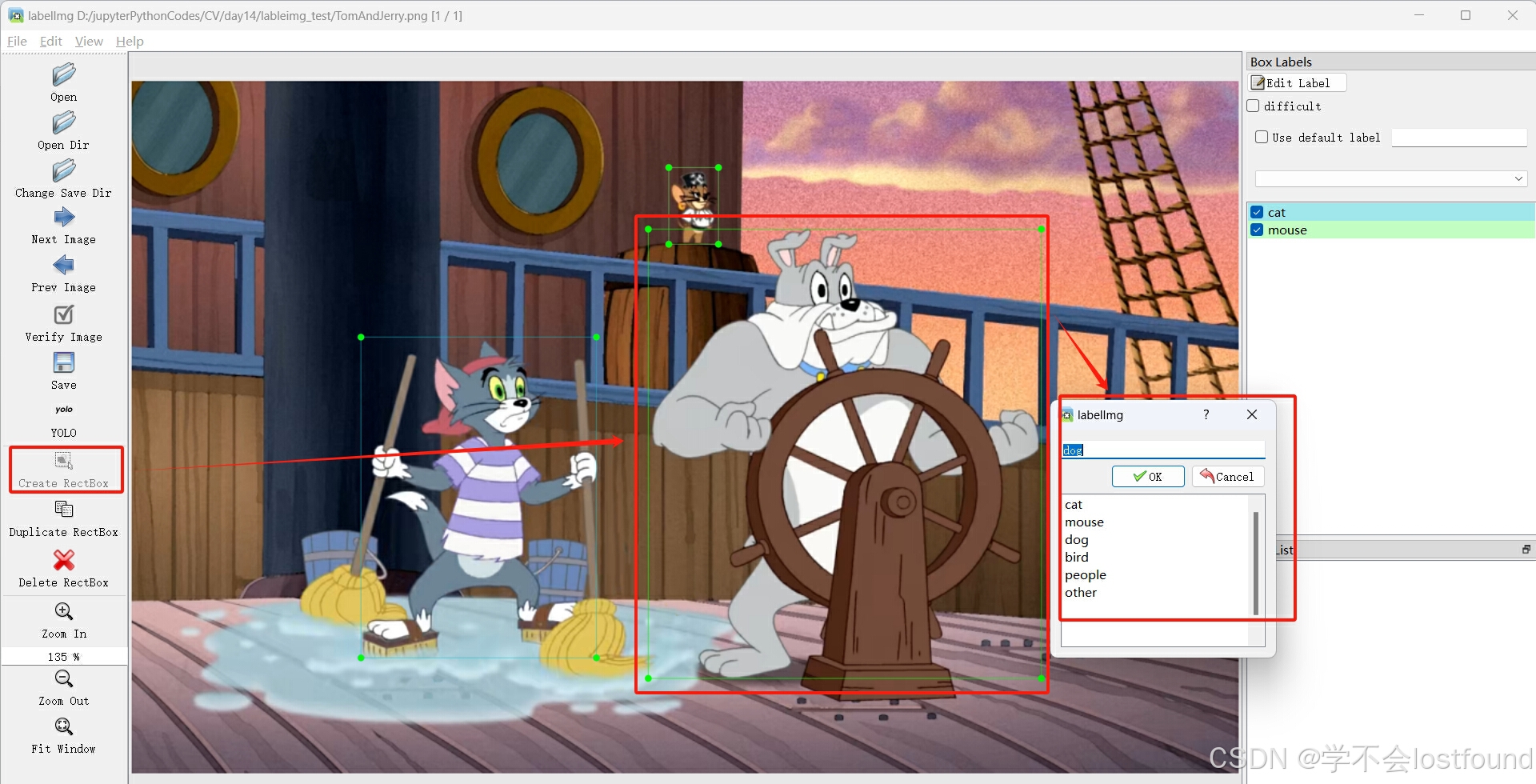
Step7: 通过【Save】按钮,将标注格式文件保存至所需目录
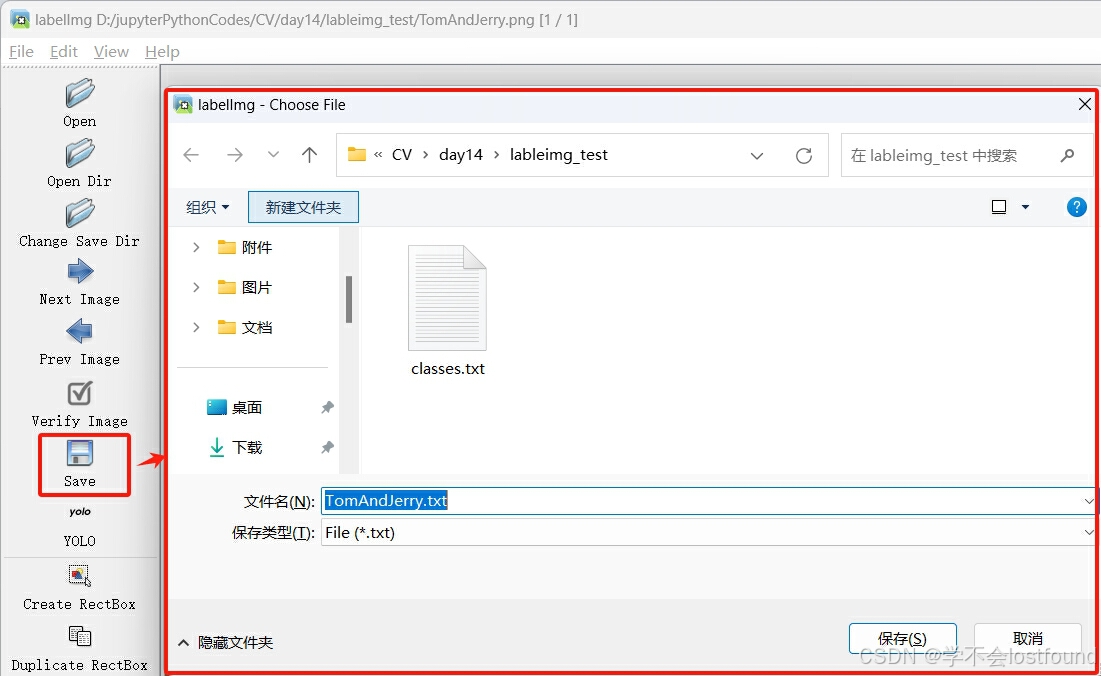
备注:做目标检测的数据标注,通常产生的是与图片相对应的标注格式文件,而不是产生标注后的图片,一般都是通过【原图】+【与之相对应的标注格式文件】进行项目开发
3.3.3 常用功能
labelimg的常用功能说明如下图所示

4、三种经典的目标检测数据标注格式的内容查看
假设我们已经通过labelimg工具将一张名为《TomAndJerry.png》的图片进行了标注,并生成了TomAndJerry.txt、TomAndJerry.json、TomAndJerry.xml三种数据标注格式文件
4.1 YOLO(.txt)格式的内容查看
代码:
# 1、构建类别id与类别名称的对应关系字典
idx2label = {}
with open("classes.txt", "r", encoding="utf-8") as f1:
for index, line in enumerate(f1):
class_name = line.strip()
idx2label[index] = class_name
# 2、查看YOLO格式的标注文件内容
with open(file="TomAndJerry.txt", mode="r", encoding="utf8") as f:
lines = f.readlines()
for line in lines:
# 分割每一行的数据,YOLO格式通常是 "class x_center y_center width height"
parts = line.strip().split()
# 检查分割后的数据是否包含足够的部分
if len(parts) != 5:
# 如果不包含5个部分,跳过这一行
continue
# 获取类别ID和边界框坐标
class_id, x_center, y_center, width, height = parts
# 将字符串转换为浮点数
class_id = int(class_id)
x_center = float(x_center)
y_center = float(y_center)
width = float(width)
height = float(height)
# 打印类别ID和边界框坐标
print(f"Class ID: {class_id}, Class Name: {idx2label[class_id]}")
print(f"Coordinates (x_center, y_center, width, height): ({x_center}, {y_center}, {width}, {height})")
print("-" * 80)
输出:

4.2 COCO(.json)格式的内容查看
代码:
import json
with open(file="TomAndJerry.json", mode="r", encoding="utf8") as f:
data = json.loads(s=f.read())
objs = data[0]
for obj in objs["annotations"]:
label = obj["label"]
coordinates = obj["coordinates"]
print(label)
print(coordinates)
print("-" * 80)
输出:
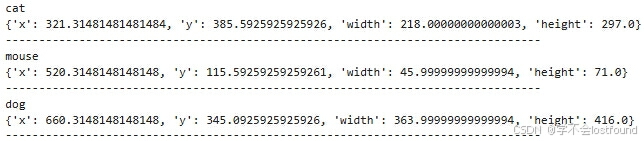
4.3 VOC(.xml)格式的内容查看
代码:
from xml.etree import ElementTree
tree = ElementTree.parse(source="TomAndJerry.xml")
root = tree.getroot()
for obj in root.findall(path="object"):
print(obj.find("name").text)
xmin = float(obj.find("bndbox").find("xmin").text)
ymin = float(obj.find("bndbox").find("ymin").text)
xmax = float(obj.find("bndbox").find("xmax").text)
ymax = float(obj.find("bndbox").find("ymax").text)
print(xmin, ymin, xmax, ymax)
print("-" * 80)
输出:

版权归原作者 学不会lostfound 所有, 如有侵权,请联系我们删除。