DDPM代码详细解读(1):数据集准备、超参数设置、loss设计、关键参数计算
Diffusion Models专栏文章汇总:入门与实战前言:大部分DDPM相关的论文代码都是基于《Denoising Diffusion Probabilistic Models》和《Diffusion Models Beat GANs on Image Synthesis》贡献代码基础上小改动的
Vision Transformer 论文 + 详解( ViT )
Vision Transformer 论文 + 详解
超详细!手把手带你轻松用 MMSegmentation 跑语义分割数据集
本文主要讲解了数据集相关的内容,包括目前学术界主流的语义分割数据集在 MMSegmentation中的实现,以及如何用 MMSegmentation 跑自己的数据集。希望可以帮助大家快速上手使用 MMSegmentation 代码库进行实验。.........
深度强化学习-DQN算法原理与代码
DQN算法是DeepMind团队提出的一种深度强化学习算法,在许多电动游戏中达到人类玩家甚至超越人类玩家的水准,本文就带领大家了解一下这个算法,论文的链接见下方。论文:https://www.nature.com/articles/nature14236.pdf代码:后续会将代码上传到Github上
【魔改YOLOv5-6.x(4)】结合EIoU、Alpha-IoU损失函数
文章目录前言EIoU论文简介加入YOLOv5Alpha-IoU论文简介加入YOLOv5References前言本文使用的YOLOv5版本为v6.1,对YOLOv5-6.x网络结构还不熟悉的同学,可以移步至:【YOLOv5-6.x】网络模型&源码解析想要尝试改进YOLOv5-6.1的同学,可以
GANs系列:DCGAN原理简介与基础GAN的区别对比
参考了DCGAN论文,对论文逐步解读,将论文精华部分进行了概括提取,包括原理、应用以及训练过程。在基础的生成式对抗神经网络的基础上,进一步介绍DCGAN深度卷积生成对抗神经网络。
Python 实现朴素贝叶斯代码演示
朴素贝叶斯可以细分为三种方法:分别是伯努利朴素贝叶斯、高斯朴素贝叶斯和多项式朴素贝叶斯。下文就这三种方法进行详细讲解和演示。目录一、伯努利朴素贝叶斯方法1.1 例子解答1.1.1 代码:1.1.2 结果:二、高斯朴素贝叶斯方法2.1 解题2.1.1 代码:2.1.2 结果:2.2 检查高斯朴素贝叶斯
翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need
它们是用于计算和思考注意力的抽象概念。一旦你继续阅读下面的注意力是如何计算的,你就会知道几乎所有你需要知道的关于每个向量所扮演的角色。计算self-attention的第二步是计算一个分数。假设我们正在计算本例中第一个单词“Thinking”的自注意力。我们需要根据这个词对输入句子的每个词进行评分。
图像风格迁移
风格迁移指的是两个不同域中图像的转换,具体来说就是提供一张风格图像,将任意一张图像转化为这个风格,并尽可能保留原图像的内容
YOLOV5更换轻量级的backbone:mobilenetV2
如何更换YOLOV5的backbone
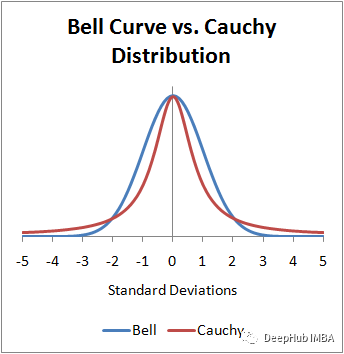
PyTorch常用5个抽样函数
在本文中,我们将介绍PyTorch中的常见抽样函数。抽样是一个统计过程,它从总体中提取一个子集,通过子集来研究整个总体。
语义分割系列15-UPerNet(pytorch实现)
本文介绍了UPerNet论文思想,介绍了UPerNet作者如何创建Multi-task数据集以及如何设计UPerNet网络和检测头来解决Multi-task任务。本文对于UPerNet语义分割部分的模型进行单独复现,所有代码基于pytorch框架,并在Camvid数据集上进行训练和测试。......
YOLOV5-断点训练/继续训练
yolov5-断点训练/继续训练
TransUnet官方代码测试自己的数据集(已训练完毕)
首先参考上一篇的训练过程,这是测试过程,需要用到训练过程的权重。1. TransUnet训练完毕之后,会生成权重文件(默认保存位置如下),snapshot_path为保存权重的路径。权重文件2. 修改test.py文件调整数据集路径。训练和测试时的图像设置相同大小。配置数据集相关信息。手动添加权重。
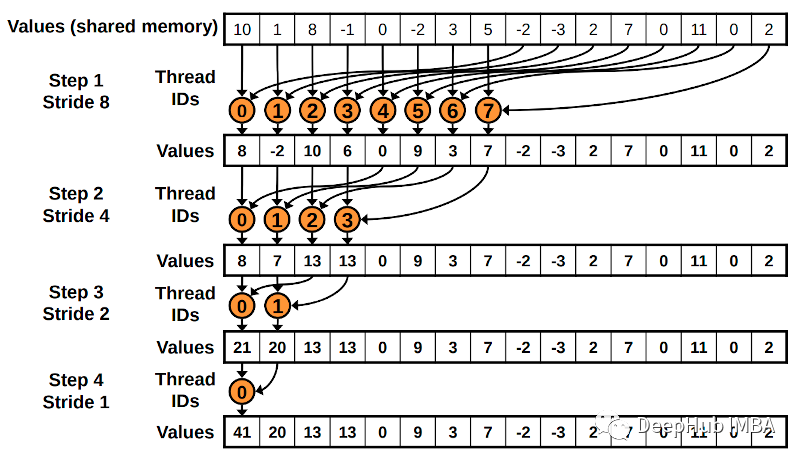
从头开始进行CUDA编程:线程间协作的常见技术
在本篇文章我们将介绍一些允许线程在计算中协作的常见技术。
NLP(自然语言处理)
目前存在的问题有两个方面:一方面,迄今为止的语法都限于分析一个孤立的句子,上下文关系和谈话环境对本句的约束和影响还缺乏系统的研究,因此分析歧义、词语省略、代词所指、同一句话在不同场合或由不同的人说出来所具有的不同含义等问题,尚无明确规律可循,需要加强语用学的研究才能逐步解决。对大规模文档进行索引。自
Transformer模型入门详解及代码实现
本文对Transformer模型的基本原理做了入门级的介绍,意在为读者描述整体思路,而并非拘泥于细微处的原理剖析,并附上了基于PYTORCH实现的Transformer模型代码及详细讲解。
clip预训练模型综述
CLIP是一个预训练模型,就像BERT、GPT、ViT等预训练模型一样。首先使用大量无标签数据训练这些模型,然后训练好的模型就能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。CLIP和BERT、GPT、ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面内容,而B
yolov5模型压缩之模型剪枝
稀疏剪枝
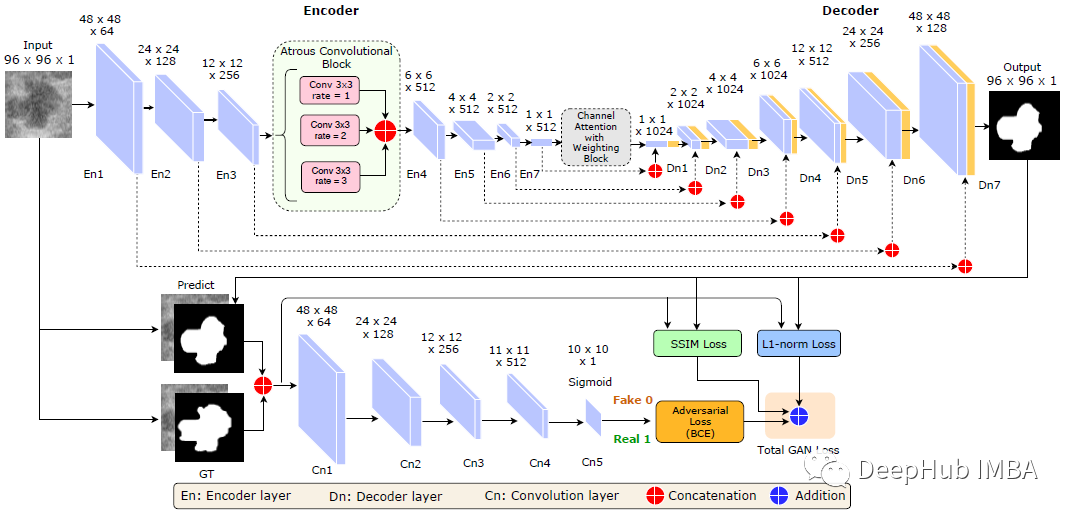
论文推荐:基于深度对抗学习的超声图像乳腺肿瘤分割与分类
条件GAN (cGAN) + Atrous卷积(AC) +带权重块的通道注意力(CAW)



