
**注意力机制的核心重点就是让网络关注到它更需要关注的地方 **。
当我们使用卷积神经网络去处理图片的时候, 我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注 ,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为重要。注意力机制 就是实现网络自适应注意的一个方式。
一般而言,注意力机制可以****分为通道注意力机制,空间注意力机制,以及二者的结合。
1、SENet
SENet是通道注意力机制的典型实现。 重点是获得输入进来的特征层对应的每一个通道的权值 。通过学习的方式自动获取每个特征通道的重要程度,自动提升有用特征并抑制不重要的特征。
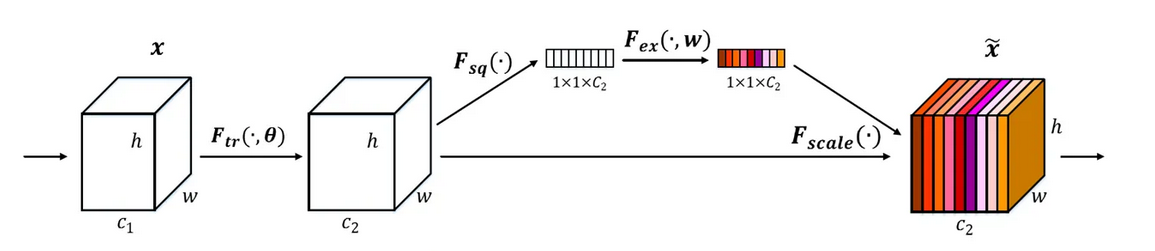
SENet具体实现方式就是:
- 第一步对输入进来的每个特征层,进行全局平均池化得到一个标量,称之为Squeeze 。
- 然后进行两次全连接,第一次全连接神经元个数较少 ,第二次全连接神经元个数和输入特征层相同 。先降维在升维好处是一方面降低了网络计算量,一方面增加了网络的非线性能力。(有的框架使用全连接,有的使用11的卷积。*)
- 在完成两次全连接后,再取一次Sigmoid将权重值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值 (0-1之间)。称之为Excitation。
- 得到的权值可以看作是经过特征选择后每个通道的重要性,将这个权值乘上每个元素对应的通道,得到新的feature map,从而实现提升重要特征,抑制不重要特征这个功能。
PyTorch版本的实现
import torch
import torch.nn as nn
#通道注意力机制
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):#传入输入通道数,缩放比例
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)#平均池化高宽为1
self.fc1 = nn.Sequential(
nn.Linear(channel, channel // reduction,bias=False),#降维
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel,bias=False),#升维
nn.Sigmoid())
self.fc2 = nn.Sequential(
nn.Conv2d(channel , channel // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction , channel , 1, bias=False),
nn.Sigmoid()
)
def forward(self, x):
#b,c,h.w
b, c, _, _ = x.size()#batch \channel\ high\ weight
# b,c,1,1----> b,c
y = self.avg_pool(x).view(b, c)#调整维度、去掉最后两个维度
# b,c- ----> b,c/16 ---- >b,c ----> b,c,1,1
y1 = self.fc1(y).view(b, c, 1, 1)#添加上h,w维度
# b,c,1,1----> b,c
z = self.avg_pool(x) # 平均欧化
# b,c- ----> b,c/16 ---- >b,c
y2 = self.fc2(z) # 降维、升维
return x * y1.expand_as(x)#来扩展张量中某维数据的尺寸,将输入tensor的维度扩展为与指定tensor相同的size
任意的原始网络结构,都可以通过这个Squeeze-Excitation的方式进行feature recalibration,如下图。
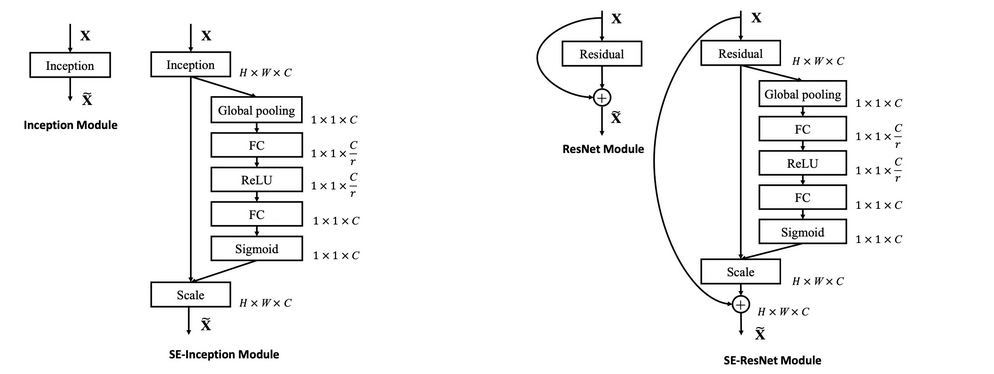
添加到其它网络结构的具体实现是:
Global Average Pooling ---> FC----> ReLU ----> FC ----> Sigmoid
第一层的FC会把通道降下来,然后第二层FC再把通道升上去,得到和通道数相同的C个权重,每个权重用于给对应的一个通道进行加权。上图中的r就是缩减系数,实验确定选取16,可以得到较好的性能并且计算量相对较小。 SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小,训练模型达到更好的结果 。
2、ECANet
ECANet对SENet模块进行了一些改进,实证分析表明降维会对通道关注度的预测产生副作用,而且对所有通道的相关性进行捕获是低效且不必要的,而**卷积具有良好的跨通道信息获取能力 。所以提出了一种不降维的局部跨信道交互策略 和 自适应选择一维卷积核大小的方法 **,从而实现了性能上的提优。
ECA模块去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征图上通过一个1D卷积进行学习。 1D卷积的卷积核大小,会影响注意力机制每个权重计算要考虑的通道数量。左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。
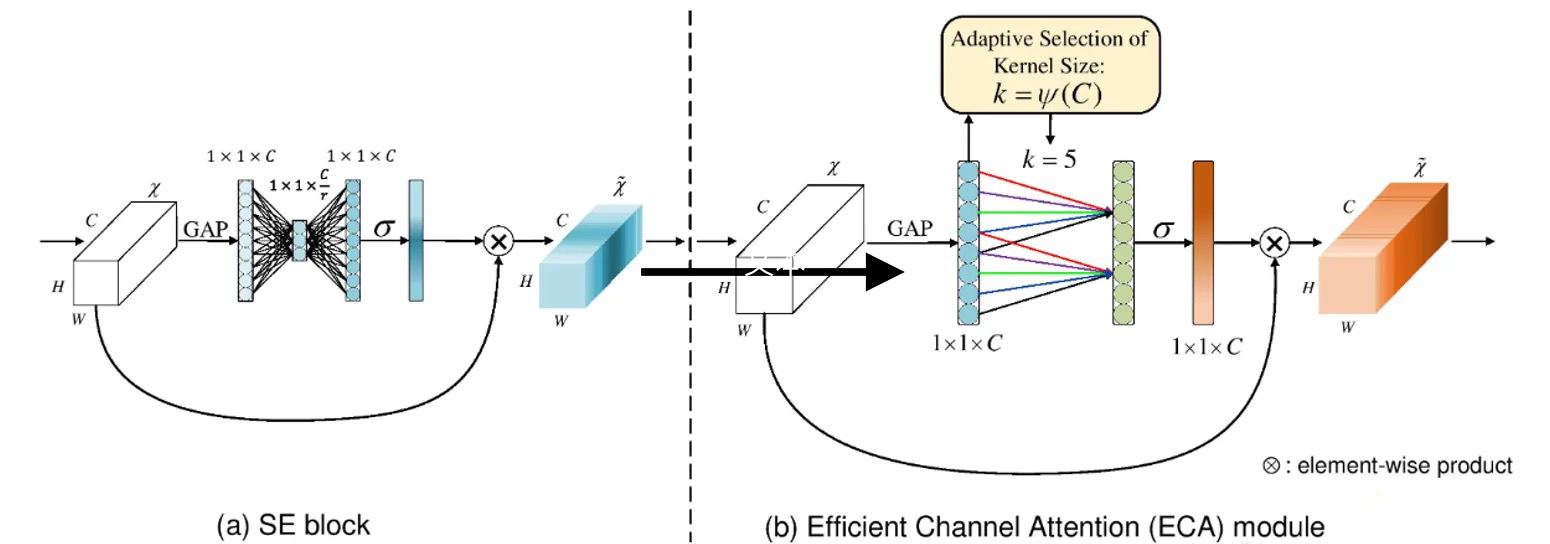
PyTorch版本的实现
class ECAlayer(nn.Module):
def __init__(self, channel, gamma=2,bias=1):
super(ECAlayer, self).__init__()
# x: input features with shape [b, c, h, w]
self.channel=channel
self.gamma=gamma
self.bias=bias
k_size=int(abs((math.log(self.channel , 2)+self.bias)/self.gamma))#(log底数2,c + 1) / 2 ---->(log 2,512 + 1)/2 = 5
k_size= k_size if k_size%2 else k_size+1 #按照输入通道数自适应的计算卷积核大小
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x) # 基于全局空间信息的特征描述符
# b,c,1,1
# 变换维度,使张量可以进入卷积层
y = self.conv(y.squeeze(-1).transpose(-1, -2))#压缩一个维度后,在转换维度
#b,c,1,1 ----》 b,c,1 ----》 b,1,c 可以理解为输入卷积的batch,只有一个通道所以维度是1,c理解为序列卷积的特征个数
y = y.transpose(-1, -2).unsqueeze(-1)
#b,1,c ----》 b,c,1 ----》 b,c,1,1
# 多尺度信息融合
y = self.sigmoid(y)
return x * y.expand_as(x)
3、CBAMNet
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于**SENet只关注通道的注意力机制 可以取得更好的效果。其实现示意图如下所示,对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理 **。下图是通道注意力机制和空间注意力机制 的具体实现方式:
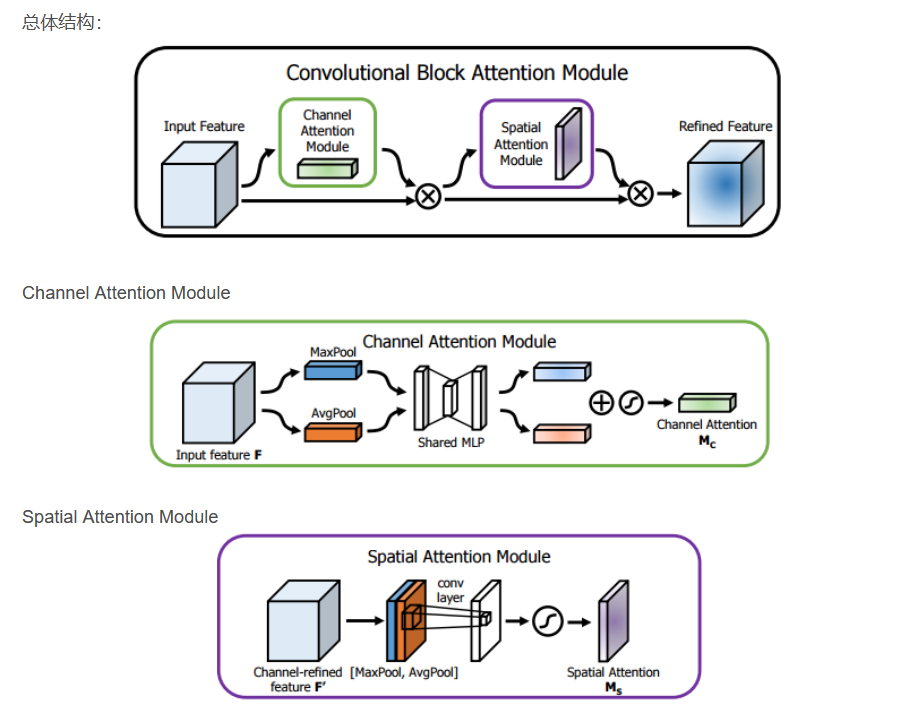
通道注意力机制:通道注意力机制的实现可以分为两个部分,对输入进来的单个特征层,分别进行 全局平均池化 和 全局最大池化 。之后对平均池化和最大池化结果,利用共享的全连接层进行处理,再对处理后的结果相加,然后经过sigmoid激活操作,获得输入特征层每一个通道的权值 (0-1之间)。最后将这个权值乘上原输入特征层,生成空间注意力模块需要的输入特征。
空间注意力机制:将通道注意力模块输出的特征图作为本模块的输入,在每一个特征点的通道上取最大值和平均值 。之后将这两个结果基于channel进行堆叠,经过一个卷积操作降维为1个通道,然后经过sigmoid激活操作,获得输入特征层每一个特征点的权值 (0-1之间)。最后将这个权值乘上原输入特征层。
PyTorch版本的实现
#CBMA 通道注意力机制和空间注意力机制的结合
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)#平均池化高宽为1
self.max_pool = nn.AdaptiveMaxPool2d(1)#最大池化高宽为1
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 平均池化---》1*1卷积层降维----》激活函数----》卷积层升维
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
# 最大池化---》1*1卷积层降维----》激活函数----》卷积层升维
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out # 加和操作
return self.sigmoid(out)#sigmoid激活操作
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = kernel_size//2
#经过一个卷积层,输入维度是2,输出维度是1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()#sigmoid激活操作
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True) # 在通道的维度上,取所有特征点的平均值 b,1,h,w
max_out, _ = torch.max(x, dim=1, keepdim=True)# 在通道的维度上,取所有特征点的最大值 b,1,h,w
x = torch.cat([avg_out, max_out], dim=1)#在第一维度上拼接,变为 b,2,h,w
x = self.conv1(x) # 转换为维度,变为 b,1,h,w
return self.sigmoid(x)#sigmoid激活操作
class cbamblock(nn.Module):
def __init__(self, channel, ratio=16, kernel_size=7):
super(cbamblock, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)#将这个权值乘上原输入特征层
x = x * self.spatialattention(x)#将这个权值乘上原输入特征层
return x
4、Coordinate Attention
全局池化方法通常用于通道注意编码空间信息的全局编码,但由于它将全局空间信息压缩到通道描述符中,导致难以保存位置信息。Coordinate Attention通过精确的位置信息对通道关系和长期依赖性进行编码,它不仅仅能捕获跨通道的信息,还能捕获方向感知和位置感知的信息,这能帮助模型更加精准地定位和识别感兴趣的目标。论文解读:
CVPR2021| 继SE,CBAM后的一种新的注意力机制Coordinate Attention - 知乎
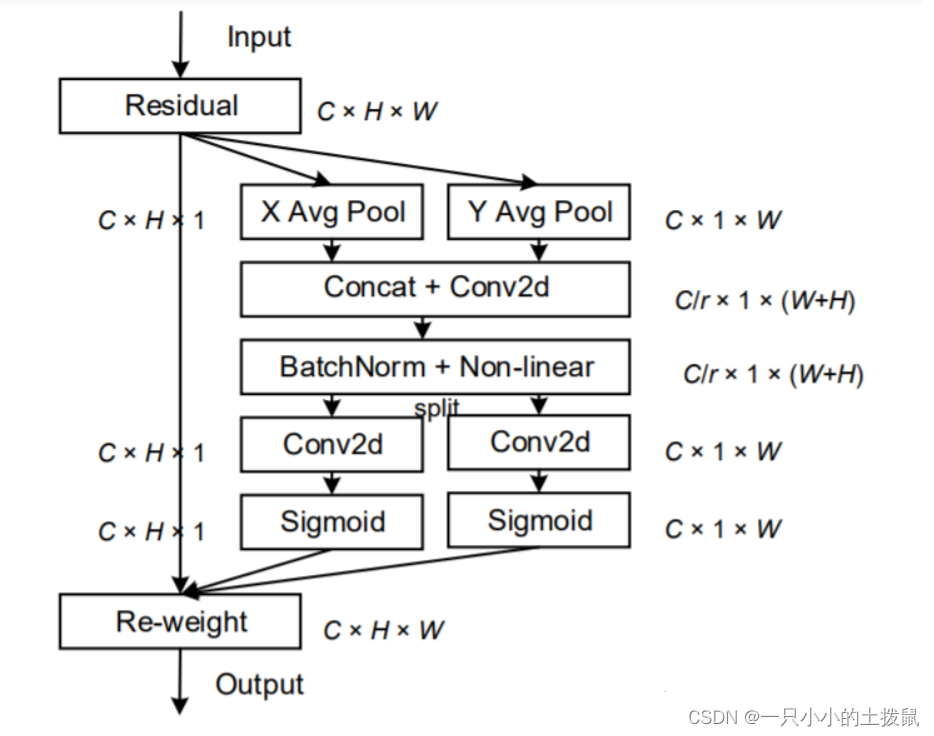
Coordinate Attention是通过在水平方向和垂直方向上进行平均池化,缓解2D全局池化造成的位置信息丢失,再进行transform对空间信息编码,最后把空间信息通过在通道上加权的方式融合。 具体操作分为 **Coordinate信息嵌入 **和 **Coordinate Attention生成 **2个步骤。
- 对输入进来的 input features (C,H,W),分别在水平方向和垂直方向进行1D平均池化操作,得到两个单独的 1D向量(C,H,1)(C,1,W)。
- 在空间维度上Concat连接两个attention map的维度(C,1,H+W),方便下面进行卷积操作,并通过一个1x1Conv层来压缩通道,减少计算量。(C/r ,1,H+W)
- 再是通过BN和Non-linear来编码垂直方向和水平方向的空间信息。(C/r ,1,H+W)
- 接下来split,在第三维度上拆分成维度为H和W的两个attention map,再各自通过1x1卷积层得到和input feature maps一样的通道数。(C,H,1)(C,1,W)
- 再sigmoid归一化加权。 最后将两个 attention map 都乘上input feature maps,以强调注意区域的表示。(C,H,W)
PyTorch版本的实现
#Coordinate Attention协调注意力机制
import torch
from torch import nn
class CABlock(nn.Module):
def __init__(self, channel, h,w, reduction=16):
super(CABlock, self).__init__()
self.h = h
self.w = w
self.avg_pool_x = nn.AdaptiveAvgPool2d((h, 1))
self.avg_pool_y = nn.AdaptiveAvgPool2d((1, w))
self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel // reduction, kernel_size=1, stride=1,
bias=False)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(channel // reduction)
self.F_h = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,
bias=False)
self.F_w = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,
bias=False)
self.sigmoid_h = nn.Sigmoid()
self.sigmoid_w = nn.Sigmoid()
def forward(self, x):
#b,c,h,w
x_h = self.avg_pool_x(x).permute(0, 1, 3, 2)
#b,c,1,h
x_w = self.avg_pool_y(x)
#b,c,1,w
x_cat_conv_relu = self.relu(self.conv_1x1(torch.cat((x_h, x_w), 3)))#在第三维度上进行拼接后,卷积
#b,c,1,h+w
x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([self.h, self.w], 3)#拆分卷积后的维度
#b,c,1,h b,c,1,w
s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))#分别进行sigmoid激活操作
s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
#b,c,h,1 b,c,1,w
out = x * s_h.expand_as(x) * s_w.expand_as(x)
return out
5、AAnet
self attention是 注意力机制 中的一种,也是transformer中的重要组成部分,利用输入样本自身的关系构建注意力模型。 自 注意力机制 要解决的问题是:当神经网络的输入是多个大小不一样的向量,并且可能因为不同向量之间有一定的关系,而在训练时却无法充分发挥这些关系,导致模型训练结果较差。
self-attention 最终得到的是:给定当前输入样本( 为了更好地理解,把输入进行拆解),产生一个输出,假设这个输出能看到所有输入的样本信息,那么这个输出是序列中所有样本的加权和,根据不同权重选择自己的注意力点。本质上,对于每个输入向量,Self-Attention产生一个向量,该向量在其邻近向量上加权求和,其中权重由单词之间的关系或连通性决定。
**注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。 **
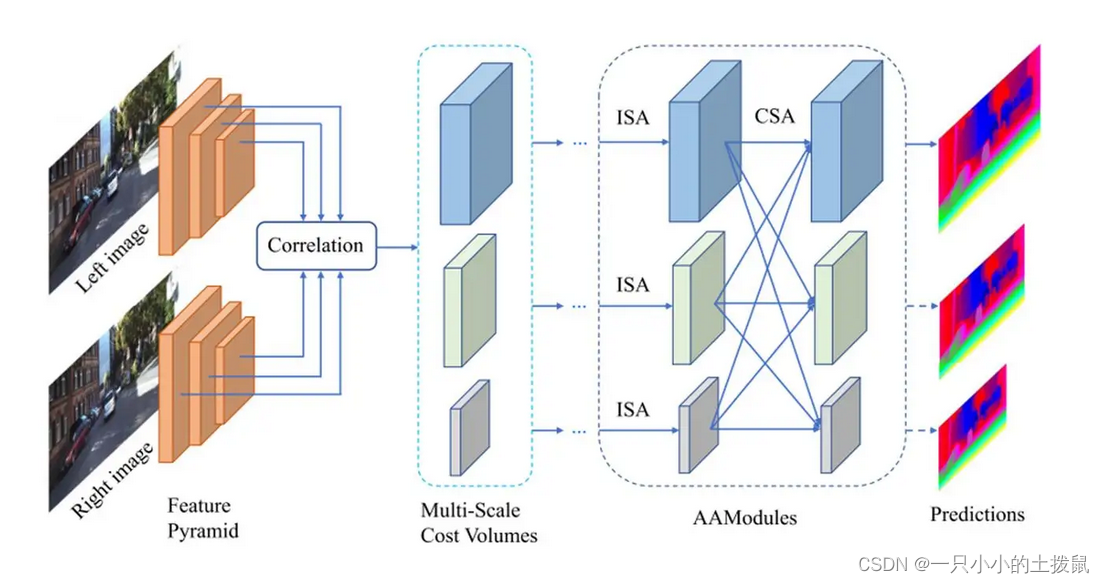
AANet,它由两个模块组成:同尺度聚合模块(ISA)和跨尺度聚合模块(CSA)。AANet可用来代替基于匹配代价体(cost volume)的3D卷积,在加快推理速度的同时保持较高的准确率。 对于AANet而言,其网络结构大致可以分成三部分。第一部分是特征提取,即利用CNN卷积得到不同尺度的特征。
第二部分是“代价聚合”,包括“匹配代价计算”(Multi-Scale Cost Volumes)和“多尺度代价融合”(AAModules)。
第三部分是深度图优化部分
PyTorch版本的实现(参考)
代码:https://github.com/leaderj1001/Attention-Augmented-Conv2d
论文:https://arxiv.org/pdf/1904.09925.pdf
论文解读:AANet - 知乎
class AugmentedConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dk, dv, Nh, shape=0, relative=False, stride=1):
super(AugmentedConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.dk = dk
self.dv = dv
self.Nh = Nh
self.shape = shape
self.relative = relative
self.stride = stride
self.padding = (self.kernel_size - 1) // 2
assert self.Nh != 0, "integer division or modulo by zero, Nh >= 1"
assert self.dk % self.Nh == 0, "dk should be divided by Nh. (example: out_channels: 20, dk: 40, Nh: 4)"
assert self.dv % self.Nh == 0, "dv should be divided by Nh. (example: out_channels: 20, dv: 4, Nh: 4)"
assert stride in [1, 2], str(stride) + " Up to 2 strides are allowed."
self.conv_out = nn.Conv2d(self.in_channels, self.out_channels - self.dv, self.kernel_size, stride=stride, padding=self.padding)
self.qkv_conv = nn.Conv2d(self.in_channels, 2 * self.dk + self.dv, kernel_size=self.kernel_size, stride=stride, padding=self.padding)
self.attn_out = nn.Conv2d(self.dv, self.dv, kernel_size=1, stride=1)
if self.relative:
self.key_rel_w = nn.Parameter(torch.randn((2 * self.shape - 1, dk // Nh), requires_grad=True))
self.key_rel_h = nn.Parameter(torch.randn((2 * self.shape - 1, dk // Nh), requires_grad=True))
def forward(self, x):
# Input x (batch_size, channels, height, width)
# batch, _, height, width = x.size()
# conv_out (batch_size, out_channels, height, width)
conv_out = self.conv_out(x)
batch, _, height, width = conv_out.size()
# flat_q, flat_k, flat_v (batch_size, Nh, height * width, dvh or dkh)
# dvh = dv / Nh, dkh = dk / Nh
# q, k, v (batch_size, Nh, height, width, dv or dk)
flat_q, flat_k, flat_v, q, k, v = self.compute_flat_qkv(x, self.dk, self.dv, self.Nh)
logits = torch.matmul(flat_q.transpose(2, 3), flat_k)
if self.relative:
h_rel_logits, w_rel_logits = self.relative_logits(q)
logits += h_rel_logits
logits += w_rel_logits
weights = F.softmax(logits, dim=-1)
# attn_out (batch, Nh, height * width, dvh)
attn_out = torch.matmul(weights, flat_v.transpose(2, 3))
attn_out = torch.reshape(attn_out, (batch, self.Nh, self.dv // self.Nh, height, width))
# combine_heads_2d (batch, out_channels, height, width)
attn_out = self.combine_heads_2d(attn_out)
attn_out = self.attn_out(attn_out)
return torch.cat((conv_out, attn_out), dim=1)
6、注意力机制的应用
**注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面 **,可以放在主干网络,也可以放在加强特征提取网络。但是放置在主干会导致网络的预训练权重无法使用。例如将注意力模块用在Resnet网络,如果加在block里面,会改变ResNet的网络结构,不能用预训练参数,加在最后一层卷积和第一层卷积不改变网络,可以用预训练参数。如果不使用预训练参数,则可以将SE模块加入到残差单元:
# 网络的第一层加入注意力机制
self.ca = cbamblock(self.in_channel)
# 网络的卷积层的最后一层加入注意力机制
self.ca1 = cbamblock(self.in_channel)
#forword部分
x = self.ca(x) # 注意力机制层
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.ca1(x)# 注意力机制层
#将SE模块用在Resnet网络,
#只需要将SE模块加入到残差单元(应用在残差学习那一部分)
#在残差单元上,添加通道注意力机制层
self.ca = ECAlayer(out_channel * self.expansion)
#forword部分
out = self.ca(out) # 在残差单元上添加注意力机制层
参考文献:
神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_Bubbliiiing的博客-CSDN博客_pytorch 注意力机制代码
注意力机制在CNN中使用总结_AI浩的博客-CSDN博客_注意力机制加在什么位置
网络中的注意力机制-CNN attention_IT捕快的博客-CSDN博客_如何在网络中加入注意力机制
SEnet(Squeeze-and-Excitation Network) 在特征通道之间加入注意力机制
CBAM(Convolutional Block Attention Module) 在特征通道和特征空间两个维度上加入注意力机制
AA-Net(Attention-Augmented-Conv2d Network) 在空间和特征子空间中同时加入注意机制
ECA-Net(Efficient Channel Attention Network) 在局部特征通道之间加入注意力机制
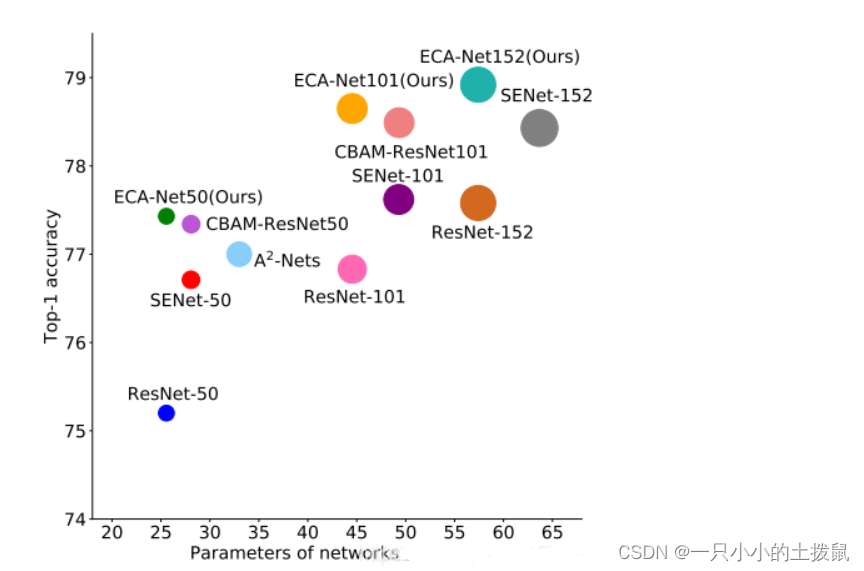
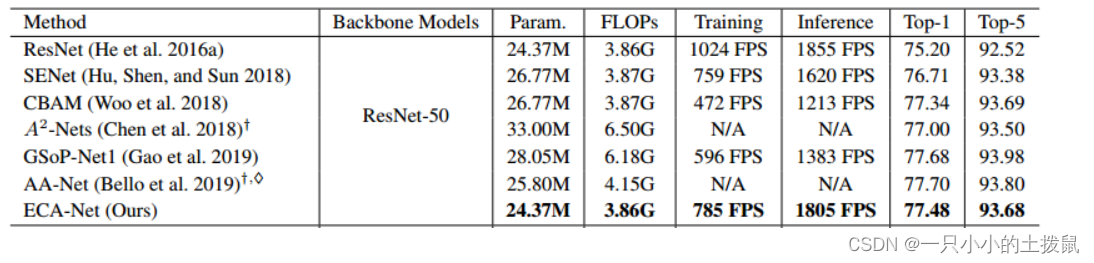
效果对比:
版权归原作者 一只小小的土拨鼠 所有, 如有侵权,请联系我们删除。