
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
随着深度学习方法增强了图像阈值、过滤和边缘检测等传统技术,计算机视觉在许多不同的应用中迅速扩展。TensorFlow 是 Google 创建的一种广泛使用且功能强大的机器学习工具。它具有用户可配置的 API,可用于在本地 PC 或云中训练和构建复杂的神经网络模型,并在边缘设备中大规模优化和部署。
在本章中,您将了解使用 TensorFlow 的高级计算机视觉概念。本章讨论了计算机视觉和 TensorFlow 的基本概念,为您为本书后面更高级的章节做好准备。我们将看看如何执行图像散列和过滤。然后,我们将学习各种特征提取和图像检索方法。接下来,我们将了解应用程序中的视觉搜索、它的方法以及我们可能面临的挑战。然后,我们将概述高级TensorFlow 软件及其不同的组件和子系统。
我们将在本章中讨论的主题如下:
- 使用图像散列和过滤检测边缘
- 从图像中提取特征
- 使用 Contours 和 HOG 检测器进行对象检测
- TensorFlow、其生态系统和安装概述
技术要求
如果您还没有这样做,请从https://www.anaconda.com安装 Anaconda 。Anaconda 是 Python 的包管理器。您还需要为您将执行的所有计算机视觉工作安装 OpenCV,使用pip install opencv-python. OpenCV 是一个用于计算机视觉工作的内置编程函数库。
使用图像散列和过滤检测边缘
图像哈希是一种用于查找图像之间相似性的方法。散列涉及通过变换将输入图像修改为固定大小的二进制向量。使用不同的转换有不同的图像散列算法:
- 永久哈希(phash):余弦变换
- 差值哈希(dhash):相邻像素之间的差值
经过哈希变换后,图像可以快速与 汉明距离进行比较。以下代码显示了用于应用哈希转换的 Python 代码。汉明距离 0 表示相同的图像(重复),而较大的汉明距离表示图像彼此不同。以下代码段导入 Python 包,例如 PIL、 imagehash和 distance. imagehash 是一个 Python 包,支持各种类型的哈希算法。 PIL 是一个 Python 成像库, distance 是一个 Python 包,用于计算两个散列图像之间的汉明距离:
from PIL import Image
import imagehash
import distance
import scipy.spatial
hash1 = imagehash.phash(Image.open(…/car1.png))
hash2 = imagehash.phash(Image.open(…/car2.png))
print hamming_distance(hash1,hash2)
图像过滤是一种基本的计算机视觉操作,它通过对输入图像的每个像素应用内核或过滤器来修改输入图像。以下是图像过滤所涉及的步骤,从光线进入相机到最终转换的图像:
- 使用拜耳滤光片形成彩色图案
- 创建图像矢量
- 转换图像
- 线性过滤——与内核的卷积
- 混合高斯和拉普拉斯滤波器
- 检测图像中的边缘
使用拜耳滤光片形成彩色图案
拜耳过滤器通过应用去马赛克算法将原始图像转换为经过颜色处理的自然图像。图像传感器由光电二极管组成,它们产生与光的亮度成正比的带电光子。光电二极管本质上是灰度的。拜耳过滤器用于将灰度图像转换为彩色。来自拜耳过滤器的彩色图像经过图像信号处理( ISP) 这涉及对各种参数进行数周的手动调整,以产生人类视觉所需的图像质量。目前正在进行几项研究工作,将手动 ISP 转换为基于 CNN 的处理以生成图像,然后将 CNN 与图像分类或对象检测模型合并以生成一个连贯的神经网络管道,该管道采用 Bayer 彩色图像并使用边界框检测对象. 有关此类工作的详细信息,请参阅 Sivalogeswaran Ratnasingam 2019 年发表的题为Deep Camera: A Fully Convolutional Neural Network for Image Signal Processing的论文。本文的链接如下所示:http: //openaccess.thecvf.com/content_ICCVW_2019/papers/LCI/Ratnasingam_Deep_Camera_A_Fully_Convolutional_Neural_Network_for_Image_Signal_ICCVW_2019_paper.pdf.
下面是一个拜耳过滤器的例子:
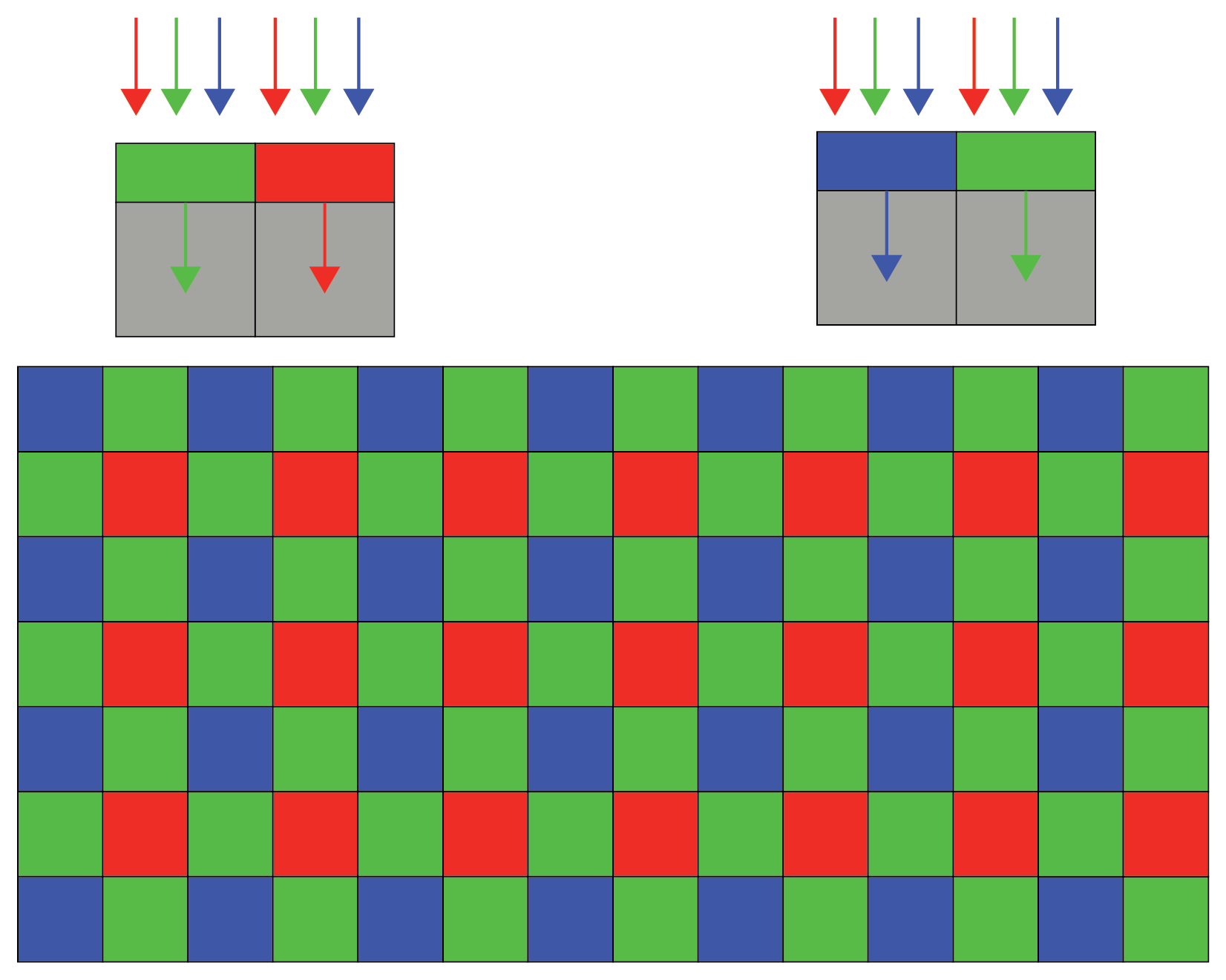
在上图中,我们可以观察到以下内容:
- 拜耳滤波器由预定义模式的红色( R )、绿色( G ) 和蓝色( B ) 通道组成,因此 G 通道的数量是 B 和 R 的两倍。
- G、R 和 B 通道交替分布。 大多数通道组合是 RGGB、GRGB 或 RGBG。
- 每个通道只会让特定的颜色通过,来自不同通道的颜色组合会产生如上图所示的图案。
创建图像矢量
彩色图像是 R、G 和 B 的组合。颜色可以表示为强度值,范围从0到255。因此,每个图像都可以表示为一个三维立方体,x和y轴代表宽度和高度,z轴代表三个颜色通道(R、G、B)代表每种颜色的强度。OpenCV 是一个内置编程函数的库,它是为 Python 和 C++ 编写的,用于图像处理和对象检测。
我们将首先编写以下 Python 代码来导入图像,然后我们将了解如何将图像分解为具有 RGB 的向量的 NumPy 数组。然后,我们将图像转换为灰度,看看当我们从图像中仅提取一个颜色分量时图像的外观:
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
image = Image.open('../car.jpeg'). # enter image path in ..
plt.imshow(image)
image_arr = np.asarray(image) # convert image to numpy array
image_arr.shape
前面的代码将返回以下输出:
Output:
(296, 465, 4)
gray = cv2.cvtColor(image_arr, cv2.COLOR_BGR2GRAY)
plt.imshow(gray, cmap=‘gray')
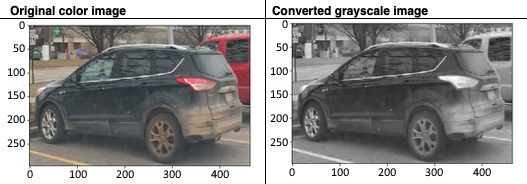
下图显示了基于上述变换的彩色图像和对应的灰度图像:
以下是我们将用于将图像转换为 R、G 和 B 颜色分量的 Python 代码:
plt.imshow(image_arr[:,:,0]) # 红色通道
plt.imshow(image_arr[:,:,1]) # 绿色通道
plt.imshow(image_arr[:,:,2]) # 蓝色通道
下图显示了仅提取一个通道(R、G 或 B)后汽车的变换图像:

上图可以表示为具有以下轴的 3D 体积:
- x轴,表示宽度。
- y轴,表示高度。
- 每个颜色通道代表图像的深度。
我们来看下图。它将汽车图像在不同x和y坐标处的R、G和B像素值显示为 3D 体积;值越高表示图像越亮:

转换图像
图像变换涉及图像的平移、旋转、放大或剪切。如果 ( x, y) 是图像像素的坐标,则新像素的变换后图像坐标 ( u, v) 可以表示为:

- 平移:平移常数值的一些示例是c11= 1、c12= 0 和c13= 10;c21= 0、c22= 1 和c23= 10。所得方程变为u= x+ 10 和v= y+ 10:

- 旋转:旋转常数值的一些示例是c11= 1、c12=0.5 和c13= 0;c21= -0.5、c22= 1 和c23= 0。
结果方程变为u= x+ 0.5y和v= -0.5 x+ y:
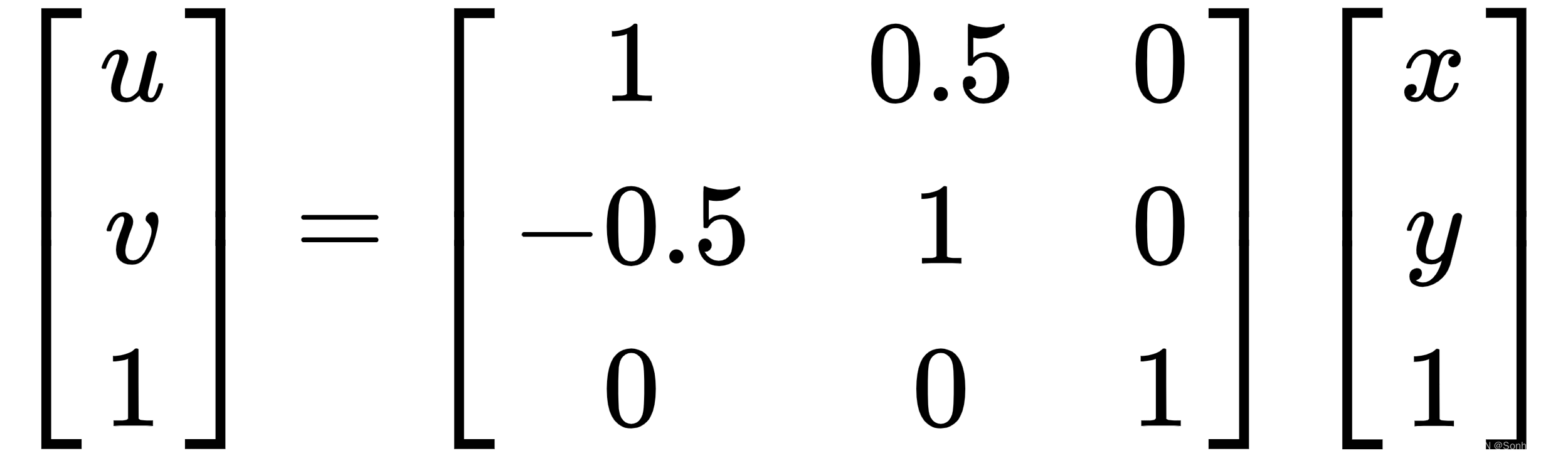
- 旋转 + 平移:旋转和平移组合常数值的一些示例为c11= 1、c12=0.5 和c13= 10;c21= -0.5、c22= 1 和c23= 10。所得方程变为u= x+ 0.5 y+ 10 和v= -0.5 x+ y+10:

- 剪切:剪切常数值的一些示例为c11= 10、c12=0 和c13= 0;c21= 0、c22= 10 和c23= 0。所得方程变为u= 10x和v= 10 y:

图像转换在计算机视觉中特别有助于从同一图像中获取不同的图像。这有助于计算机开发一个对平移、旋转和剪切具有鲁棒性的神经网络模型。例如,如果我们在训练阶段仅在卷积神经网络( CNN ) 中输入汽车前部的图像,则模型将无法在测试阶段检测到旋转 90 度的汽车图像。
接下来,我们将讨论卷积操作的机制以及如何应用过滤器来转换图像。
线性过滤——与内核的卷积
计算机视觉中的卷积是两个数组(一个是图像,另一个是小数组)的线性代数运算,以产生形状与原始图像数组不同的滤波图像数组。卷积是累积的和关联的。它可以用数学表示如下:
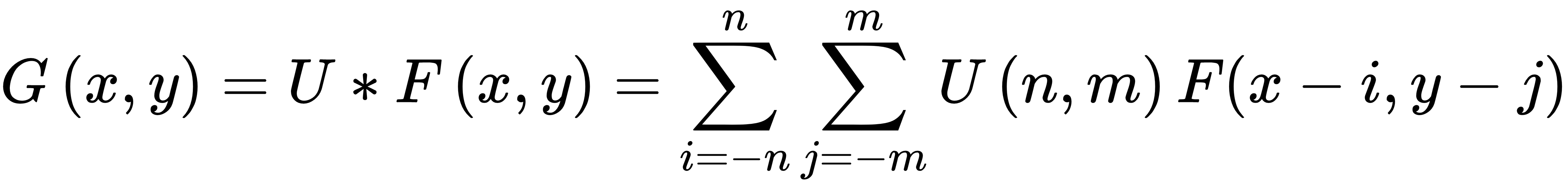
上述公式解释如下:
- F(x,y)是原始图像。
- G(x,y)是过滤后的图像。
- U是图像内核。
根据内核类型,U输出图像会有所不同。转换的Python代码如下:
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
image = Image.open('…/carshort.png')
plt.imshow(image)
image_arr = np.asarray (image) # 将图像转换为 numpy 数组
image_arr.shape
gray = cv2.cvtColor(image_arr, cv2.COLOR_BGR2GRAY)
plt.imshow(gray, cmap='gray')
kernel = np.array([[-1,-1, -1],
[2,2,2],
[-1,-1,-1]])
blurimg = cv2.filter2D(gray,-1,kernel)
plt.imshow(blurimg, cmap='gray')
上述代码的图像输出如下:
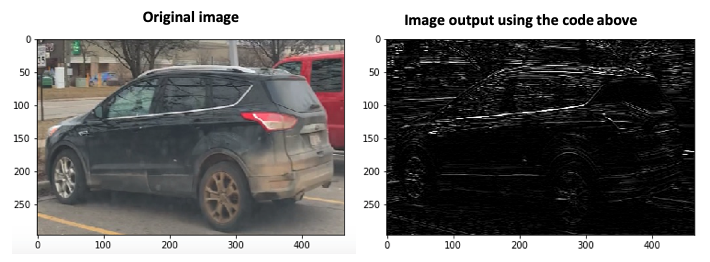
左边是输入图像,右边是通过对图像应用水平内核获得的图像。水平内核仅检测水平边缘,可以通过水平线的白色条纹看到。有关水平内核的详细信息,请参见图像渐变部分。
上述代码导入了机器学习和计算机视觉工作所需的Python库,例如用于处理数组的 NumPy、用于 openCV 计算机视觉工作的 cv2、用于处理Python代码中的图像的 PIL 以及用于绘制结果的M atplotlib。然后它使用 PIL 导入图像并使用 OpenCV缩放功能将其转换为灰度。它使用 NumPy 数组创建用于边缘过滤的内核,使用内核模糊图像,然后使用函数显示它。BGr2GRAYimshow()
过滤操作分为三个不同的类:
- 图像平滑
- 图像渐变
- 图像锐化
图像平滑
在图像平滑中,通过应用低通滤波器来去除图像中的高频噪声,例如:
- 均值滤波器
- 中值滤波器
- 高斯滤波器
这会使图像模糊,并通过应用一个像素来执行,该像素的最终值不会改变符号并且值不会有明显差异。
图像过滤通常是通过在图像上滑动框式过滤器来完成的。盒式过滤器由 n x m 除以 ( nm* ) 的内核表示,其中n是行数,m是列数。对于 3 x 3 内核,这看起来如下:
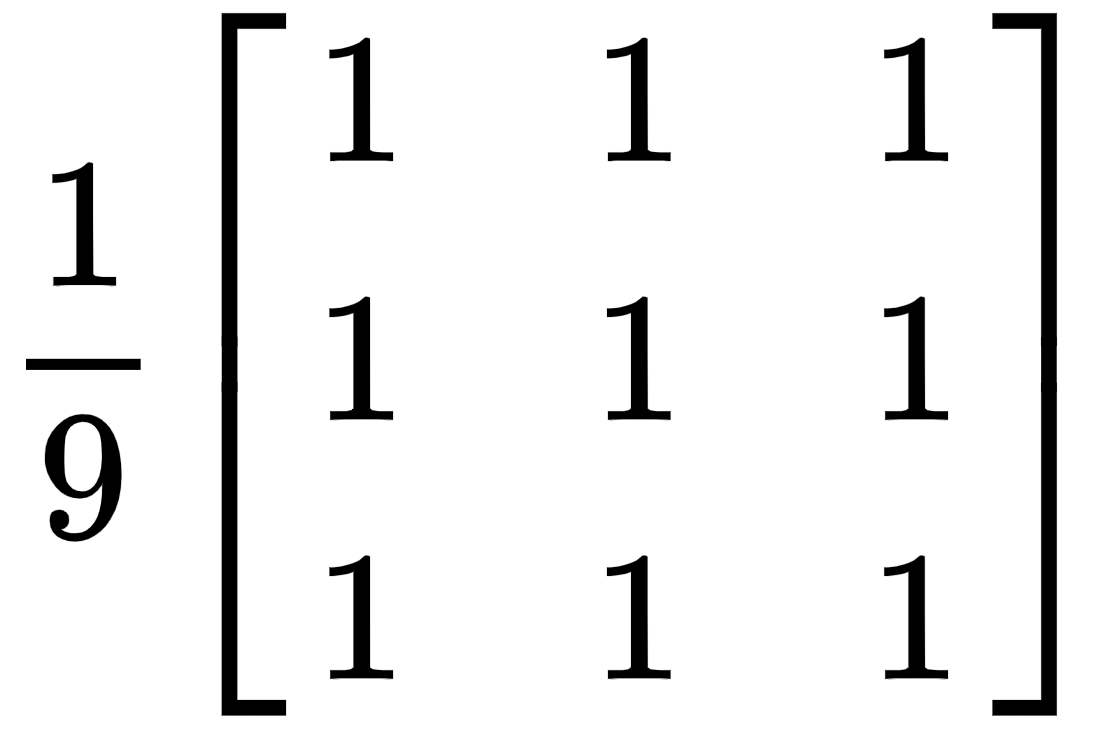
假设这个内核应用于前面描述的 RGB 图像。作为参考,此处显示了 3 x 3 图像值:

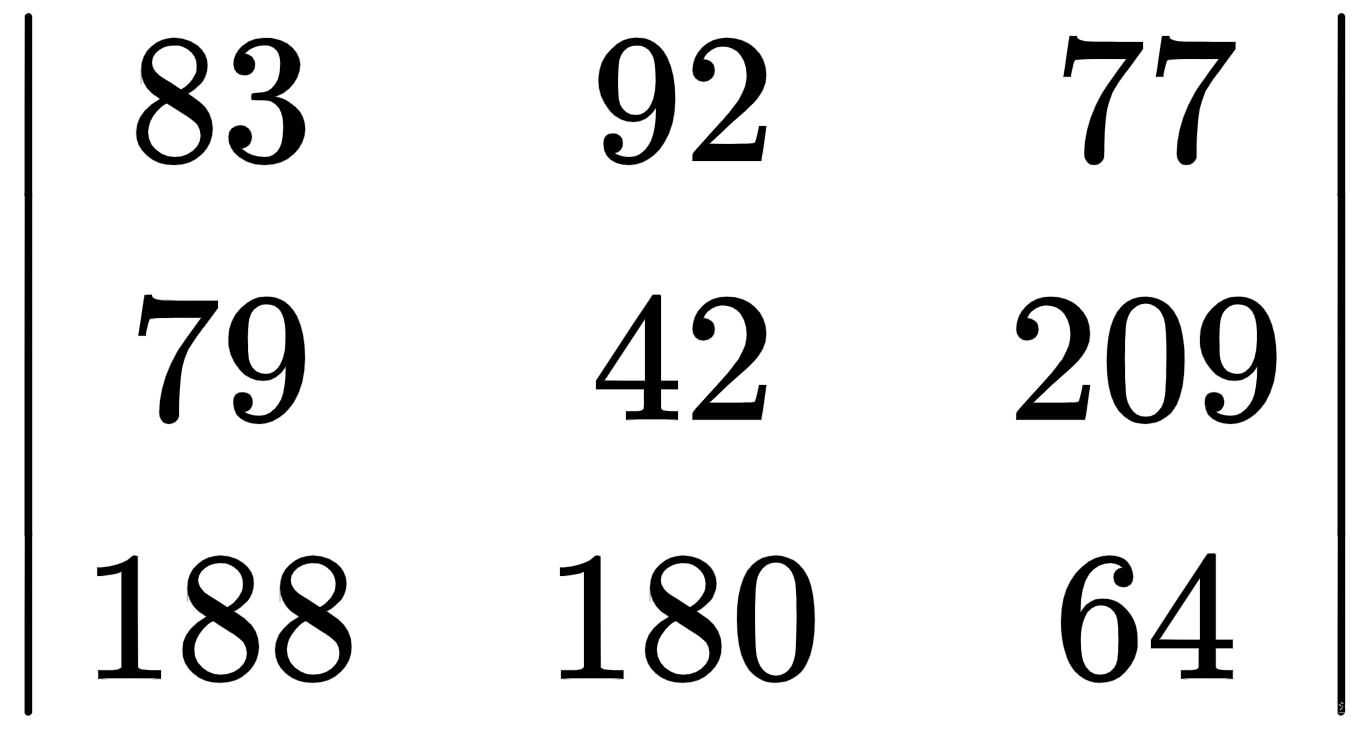
均值滤波器
均值滤波器对图像进行框核卷积运算后,对图像进行平均滤波。矩阵乘法后的结果数组如下:

平均值是42并替换166图像中的中心强度值,如您在以下数组中所见。图像的剩余值将以类似的方式进行转换:
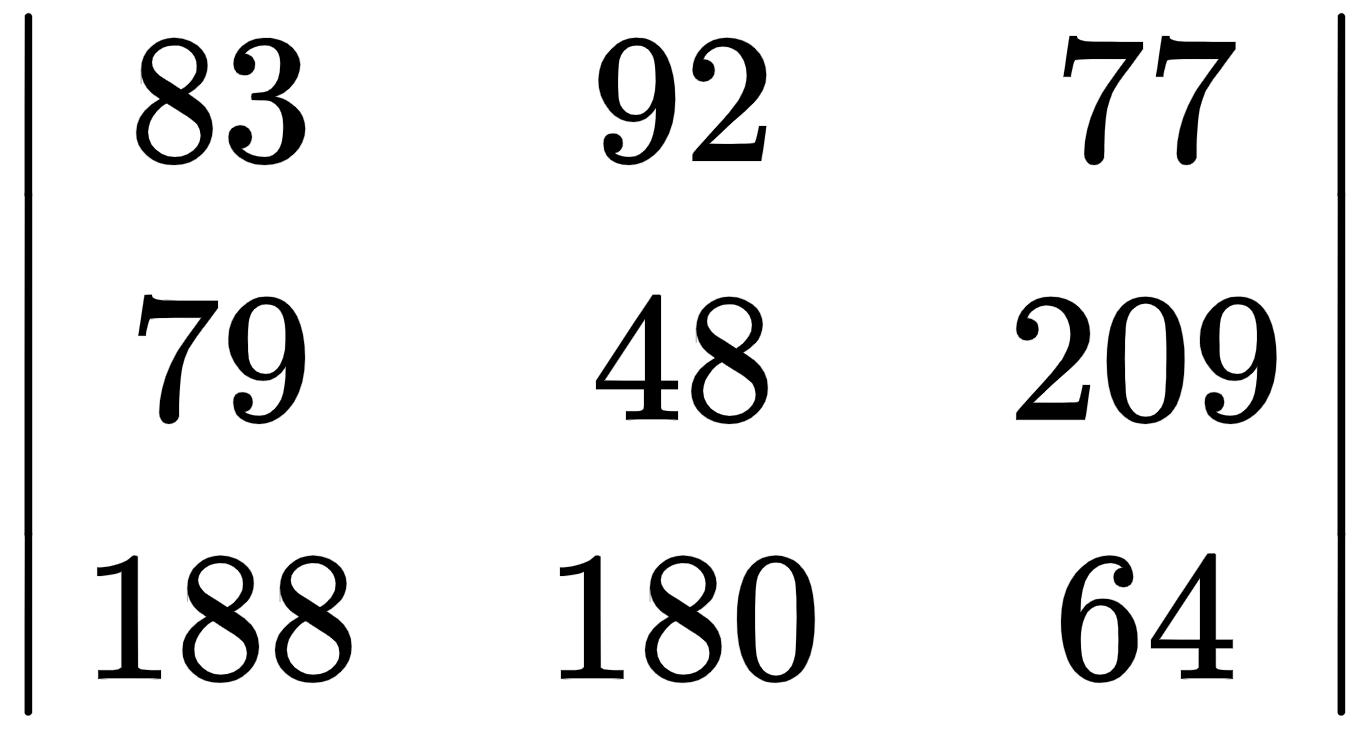
中值滤波器
中值滤波器对图像进行框核卷积运算后,用中值过滤图像值。矩阵乘法后的结果数组如下:

中值是48并替换166图像中的中心强度值,如下面的数组所示。图像的剩余值将以类似的方式进行转换:
高斯滤波器
高斯核由以下等式表示:
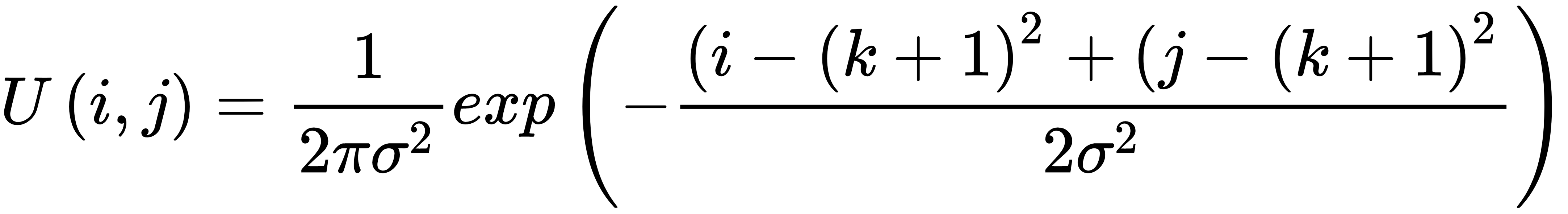
 是分布的标准差,k是核大小。
是分布的标准差,k是核大小。
对于 的标准差 ( )1和 3 x 3 内核 ( k= 3),高斯内核如下所示:

在这个例子中,当应用高斯核时,图像变换如下:

因此,在这种情况下,中心强度值为54。将此值与中值和均值滤波器值进行比较。
使用 OpenCV 进行图像过滤
通过将过滤器应用于真实图像,可以更好地理解前面描述的图像过滤概念。OpenCV 提供了一种方法来做到这一点。
以下代码段中列出了重要的代码。导入图像后,我们可以添加噪点。没有噪声,图像过滤效果不能很好的可视化。之后,我们需要保存图像。这对于均值和高斯滤波器不是必需的,但是如果我们不使用中值滤波器保存图像并再次将其导入,Python 会显示错误。
请注意,我们使用plt.imsave的是保存图像,而不是 OpenCV。使用直接保存imwrite将导致黑色图像,因为图像需要在保存之前标准化为 255 比例。plt.imsave没有那个限制。
在此之后,我们使用blur、medianBlur和GaussianBlur使用均值、中值和高斯滤波器转换图像:
img = cv2.imread('car.jpeg')
imgnoise = random_noise(img, mode='s&p',amount=0.3)
plt.imsave("car2.jpg", imgnoise)
imgnew = cv2.imread('car2.jpg')
meanimg = cv2.blur(imgnew,(3,3))
medianimg = cv2.medianBlur(imgnew,3)
gaussianimg = cv2.GaussianBlur(imgnew,(3,3),0)
下图显示了使用 绘制的结果图像matplotlib pyplot:
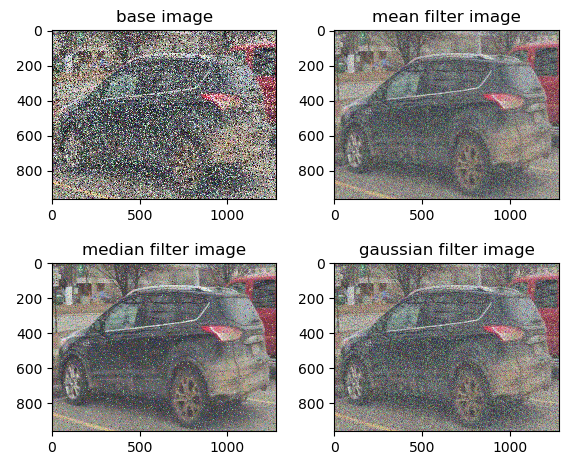
请注意,在这三种情况下,过滤器都会去除图像中的噪声。在此示例中,中值滤波器似乎是三种方法中去除图像噪声最有效的方法。
图像渐变
图像梯度计算给定方向上像素强度的变化。像素强度的变化是通过对带有内核的图像执行卷积运算来获得的,如下所示:
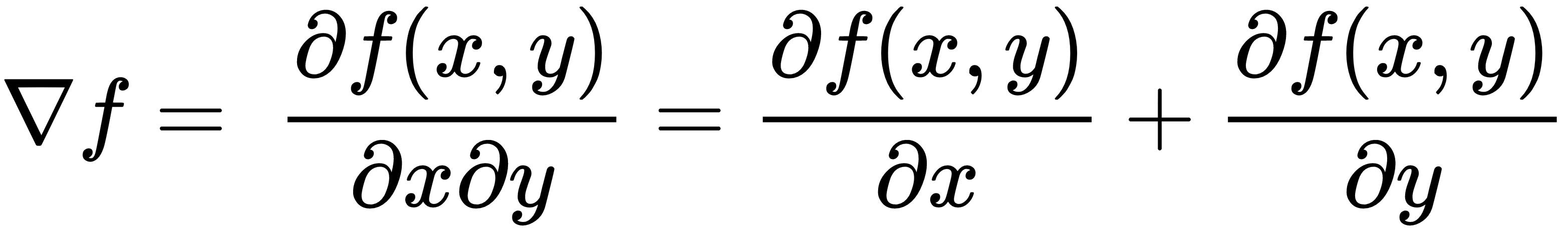
内核的选择使得两个极端行或列具有相反的符号(正和负),因此在图像像素上相乘和求和时会产生差分算子。让我们看一下下面的例子:
- 水平内核:
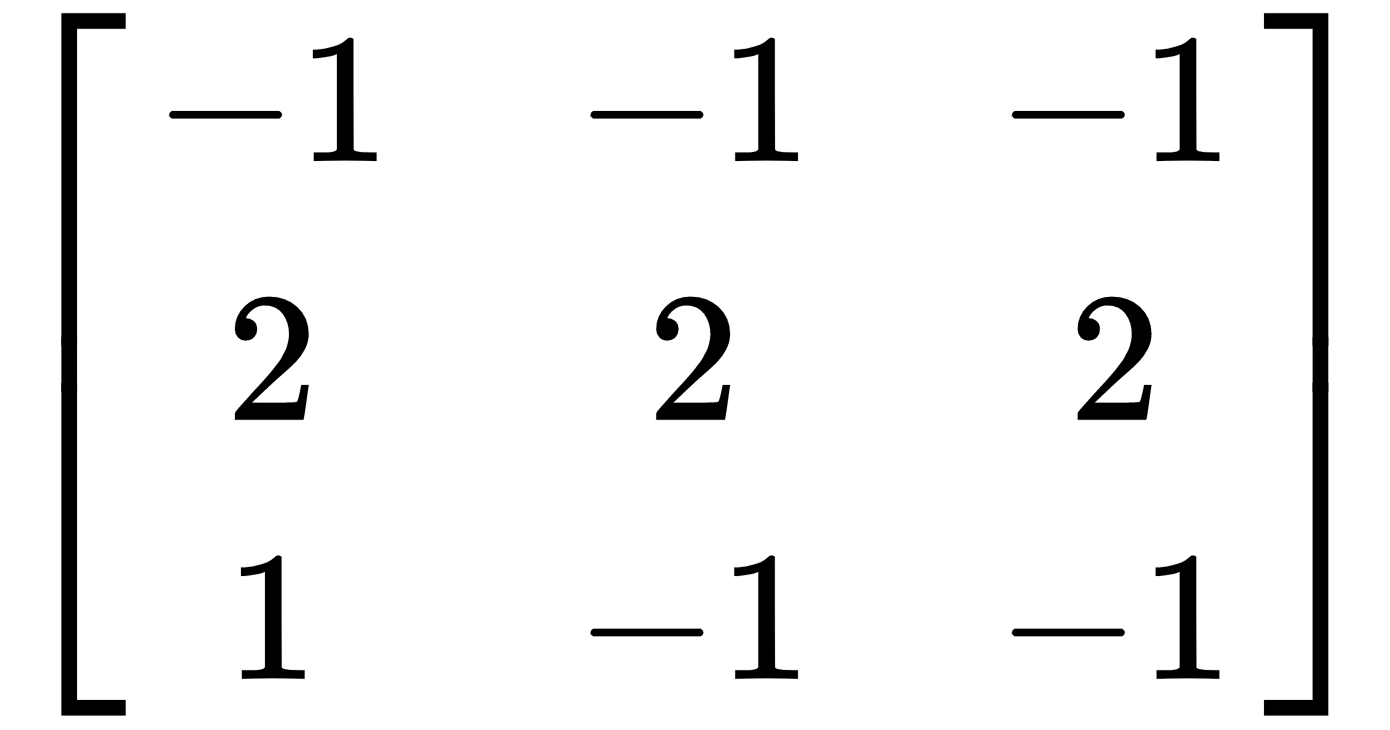
- 垂直内核:
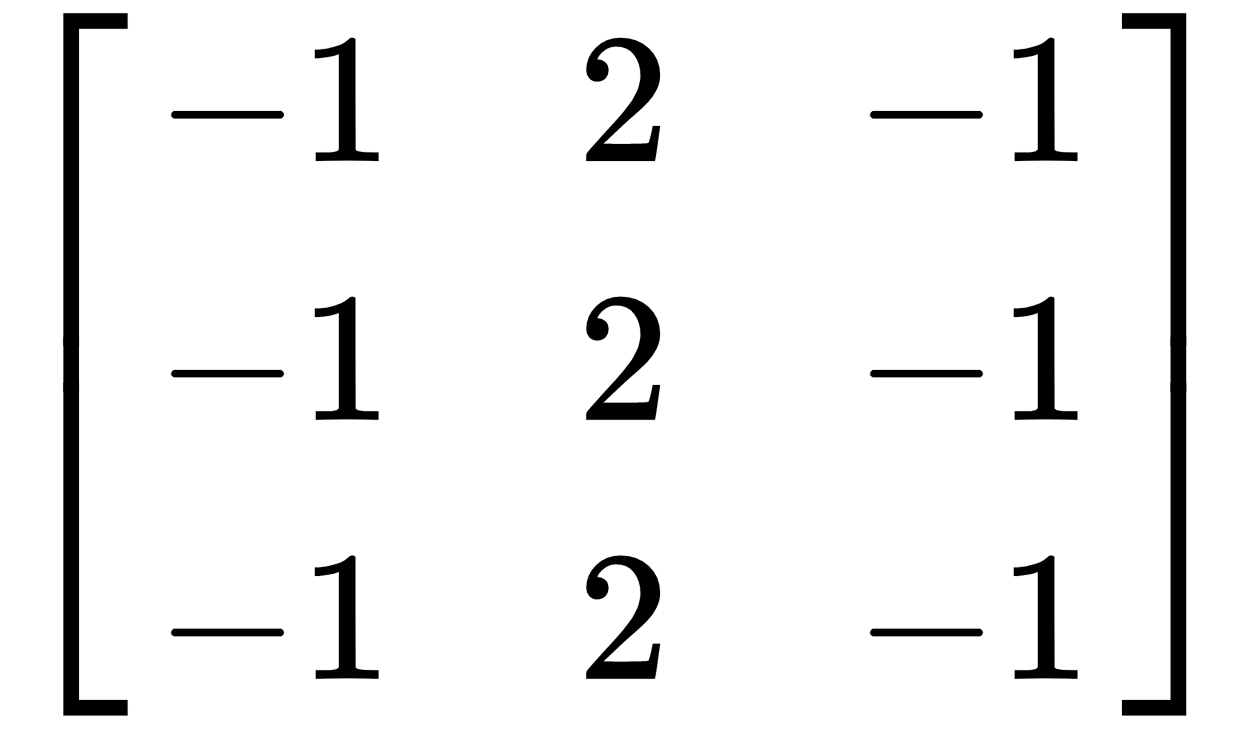
这里描述的图像梯度是计算机视觉的一个基本概念:
- 可以在x和y方向上计算图像梯度。
- 通过使用图像梯度,确定边缘和角落。
- 边缘和角落包含了大量关于图像形状或特征的信息。
- 因此,图像梯度是一种将低阶像素信息转换为高阶图像特征的机制,用于卷积运算进行图像分类。
图像锐化
在图像锐化中,通过应用高通滤波器(差分算子)去除图像中的低频噪声,从而使线条结构和边缘变得更加明显。图像锐化也称为拉普拉斯运算,由二阶导数表示,如下所示:
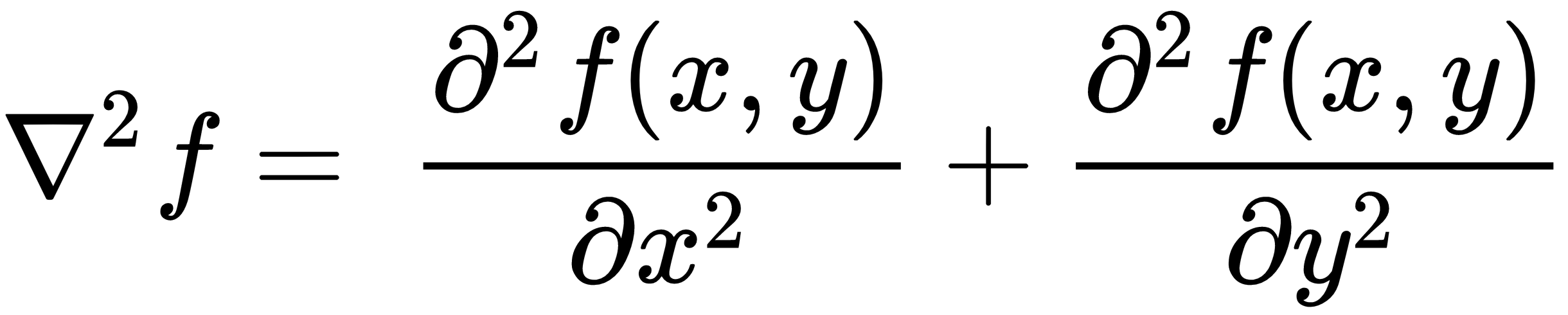
由于差分算子,相对于内核中点的四个相邻单元始终具有相反的符号。因此,如果内核的中点为正,则四个相邻单元格为负,反之亦然。让我们看一下下面的例子:
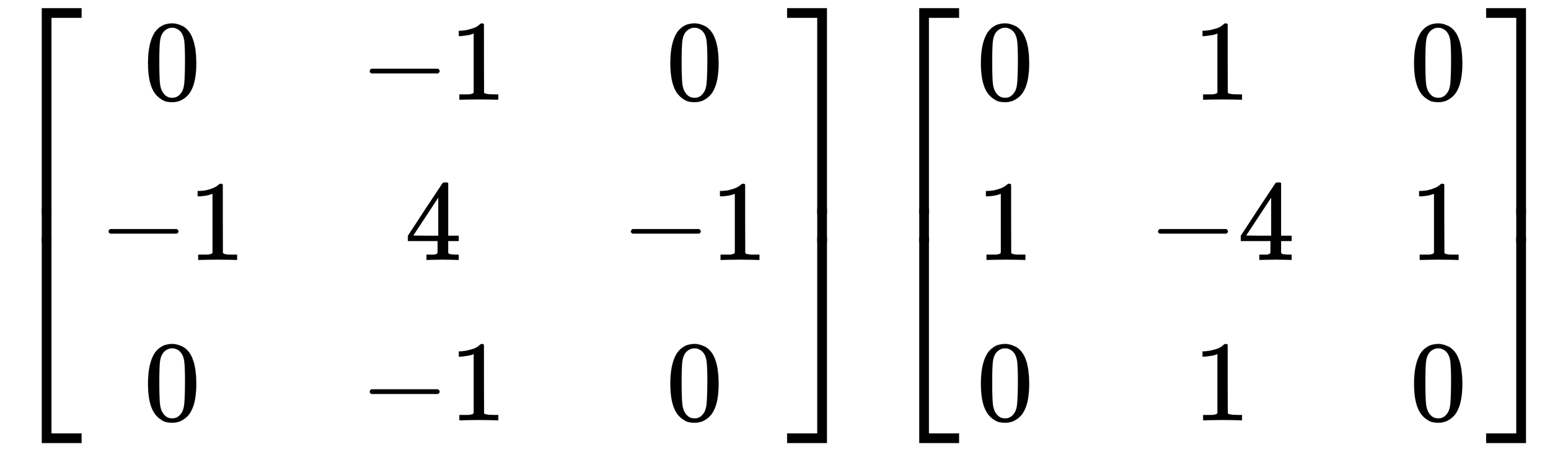
请注意,二阶导数优于一阶导数的优点是二阶导数将始终经过零交叉。因此,可以通过查看一阶梯度的零交叉点(0值)而不是梯度的大小(可以在图像之间以及在给定图像内变化)来确定边缘。
混合高斯和拉普拉斯运算
到目前为止,您已经了解了高斯运算使图像模糊,而拉普拉斯运算使图像锐化。但是为什么我们需要每个操作,每个操作在什么情况下使用呢?
图像由特征、特征和其他非特征对象组成。图像识别就是从图像中提取特征并消除非特征对象。我们将图像识别为特定对象,例如汽车,因为与非特征相比,它的特征更加突出。高斯滤波是从特征中抑制非特征的方法,使图像模糊。
多次应用它会使图像更加模糊,并抑制特征和非特征。但由于特征更强,它们可以通过应用拉普拉斯梯度来提取。这就是为什么我们用 sigma 的高斯核卷积两次或更多次,然后应用拉普拉斯运算来清楚地显示特征的原因。这是大多数卷积操作中用于对象检测的常用技术。
下图显示了输入的 3 x 3 图像部分、核值、卷积运算后的输出值以及得到的图像:
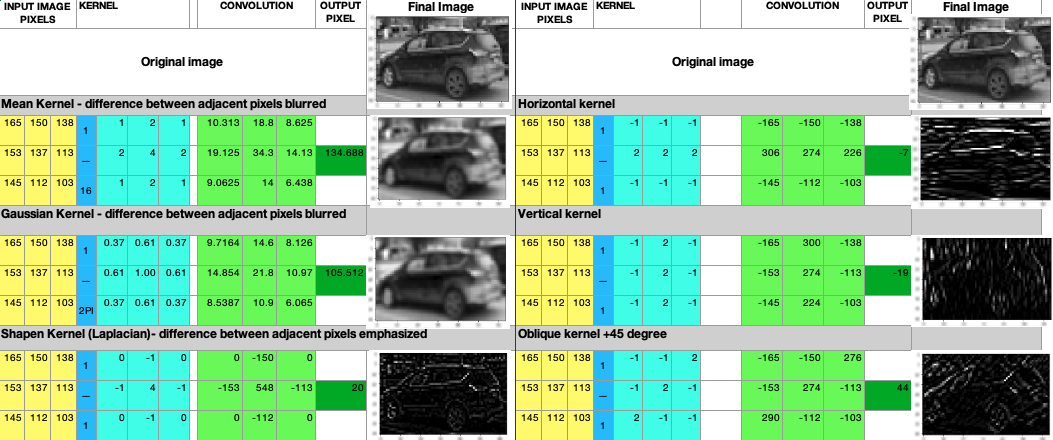
上图显示了各种高斯和倾斜核以及如何通过应用核来转换图像的 3 x 3 部分。下图是上图的延续:
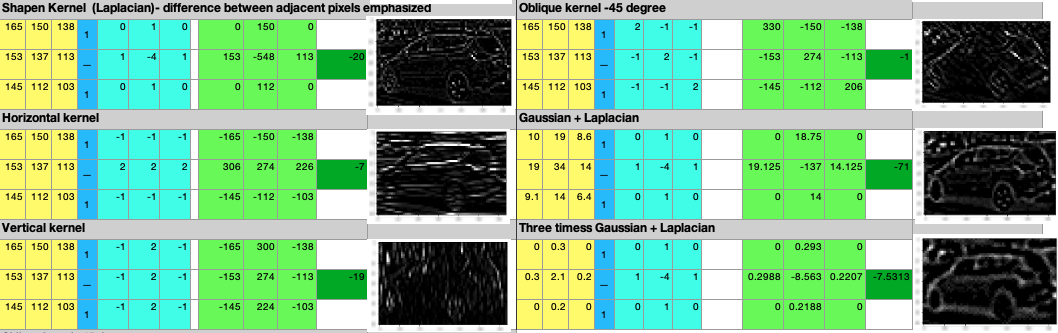
前面的表示清楚地显示了图像如何根据卷积操作的类型变得更加模糊或锐利。随着我们更多地了解如何使用 CNN 在 CNN 的各个阶段优化内核选择,对卷积操作的这种理解至关重要。
检测图像中的边缘
边缘检测是计算机视觉中根据亮度和图像强度的变化来寻找图像特征的最基本的处理方式。亮度的变化是由深度、方向、照明或角落的不连续性引起的。边缘检测方法可以基于一阶或二阶:
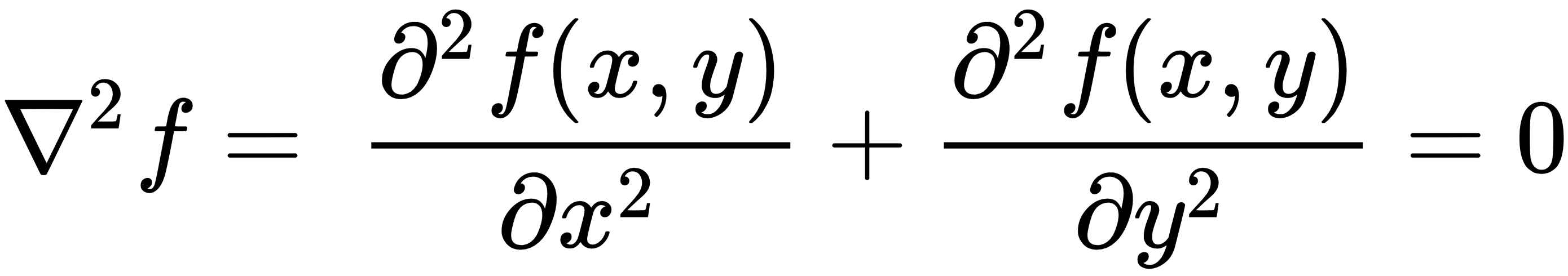
下图以图形方式说明了边缘检测机制:
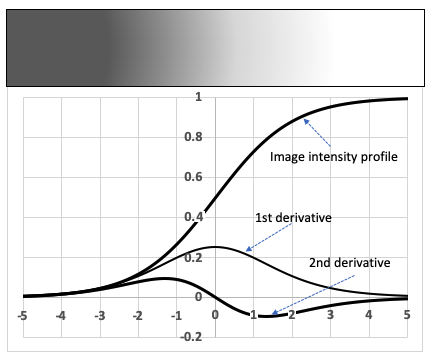
在这里,您可以看到图像的强度在中间点附近由暗变为亮,因此图像的边缘位于中间点。一阶导数(强度梯度)在中间点先升后降,所以可以通过查看一阶导数的最大值来计算边缘检测。但是,一阶导数法的问题是,根据输入函数的不同,最大值会发生变化,因此无法预先确定最大值的阈值。然而,如图所示,二阶导数总是通过边缘处的零点。
Sobel和Canny是一阶边缘检测方法,而二阶方法是拉普拉斯边缘检测器。
Sobel 边缘检测器
Sobel 算子通过计算图像强度函数的梯度(在下面的代码中)来检测Sobelx边缘Sobely。梯度是通过对图像应用内核来计算的。在以下代码中,内核大小 ( ksize) 为5. 在此之后,通过取梯度 (sobely /sobelx )的比率计算Sobel 梯度( SobelG ):
Sobelx=cv2.Sobel(gray,cv2.CV_64F,1,0,ksize=5)
Sobely=cv2.Sobel(gray,cv2.CV_64F,0,1,ksize=5)
mag,direction = cv2.cartToPolar(sobelx, sobely,angleInDegrees = True)
sobelG = np.hypot(sobelx,sobely)
Canny 边缘检测器
Canny 边缘检测器使用二维高斯滤波器去除噪声,然后应用具有非极大值抑制的 Sobel 边缘检测来挑选出任意像素点x和y 梯度之间的最大比值,最后应用边缘阈值处理检测是否有边缘。以下代码显示了灰度图像上的 Canny 边缘检测。min和max值是比较图像梯度以确定边缘的阈值:
Canny = cv2.Canny(gray,minVal=100,maxVal=200)
下图是应用Sobel-x, Sobel-y, 和 Canny 边缘检测器后的汽车图像:

正如我们所看到的,Canny 在检测汽车方面的表现比 Sobel 好得多。这是因为 Canny 使用二维高斯滤波器去除噪声,然后应用带有非极大值抑制的 Sobel 边缘检测来挑选出任意像素点x和y梯度之间的最大比值,最后应用边缘阈值处理检测是否有边缘。
从图像中提取特征
一旦我们知道如何检测边缘,下一个任务就是检测特征。许多边结合形成特征。特征提取是识别图像中的视觉模式并提取与未知对象图像匹配的任何可区分的局部特征的过程。在进行特征提取之前,了解图像直方图很重要。图像直方图是图像颜色强度的分布。
如果直方图相似,则图像特征与测试图像匹配。以下是用于创建汽车图像直方图的Python代码:
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
image = Image.open('../car.png')
plt.imshow(image)
image_arr = np. asarray(image) # 将图像转换为 numpy 数组
image_arr.shape
color = ('blue', 'green', 'red')
for i,histcolor in enumerate(color):
carhistogram = cv2.calcHist([image_arr],[i],None,[256],[0,256])
plt.plot(carhistogram,color=histcolor)
plt.xlim([0,256])
上述 Python 代码首先导入必要的 Python 库,例如 cv2 (OpenCV)、NumPy(用于数组计算)、PIL(用于导入图像)和M atplotlib(用于绘制图形)。之后,它将图像转换为数组并循环遍历每种颜色并绘制每种颜色(R、G 和 B)的直方图。
下图显示了汽车图像的直方图输出。x轴代表从0(黑色)到256(白色)的颜色强度值, y轴代表出现频率:
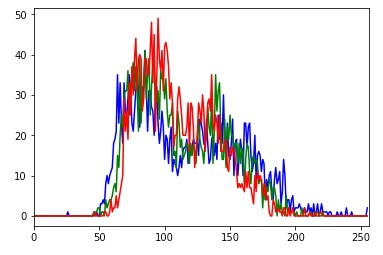
直方图显示 R、G 和 B 的颜色强度峰值在 左右100,第二个峰值在 左右150。这意味着汽车的平均颜色是灰色。0强度值为 的频率200(在图像的最右侧看到)表明汽车绝对不是白色的。类似地,0强度值为 的频率50表明图像不是完全黑色的。
使用 OpenCV 进行图像匹配
图像匹配是一种匹配两个不同图像以找到共同特征的技术。图像匹配技术有许多实际应用,例如匹配指纹、匹配您的地毯颜色与您的地板或墙壁颜色、匹配照片以找到同一个人的两个图像,或者比较制造缺陷以将它们分组到相似的类别以便更快地分析。本节提供 OpenCV 中可用的图像匹配技术的高级概述。这里描述了两种常用的方法:BruteForce ( BFMatcher ) 和Fast Library for Approximate Nearest Neighbors ( FLANN)。在本书的后面,我们还将讨论其他类型的匹配技术,例如第 2 章中的直方图匹配和局部二进制模式,使用局部二进制模式的内容识别,以及第 6 章,使用迁移学习的视觉搜索中的视觉搜索。
在 BFMatcher 中,将测试图像与目标图像的每个部分之间的汉明距离进行比较,以获得最佳匹配。另一方面,FLANN 速度更快,但只会找到近似的最近邻居——因此,它会找到好的匹配,但不一定是最好的匹配。KNN工具假设相似的事物彼此相邻。它根据目标和源之间的距离找到第一个近似最近的邻居。
请注意,在下图中,BFMatcher 找到了更相似的图像。该图是前面代码(preface_SIFT.ipynb)返回的输出。我们来看一下:
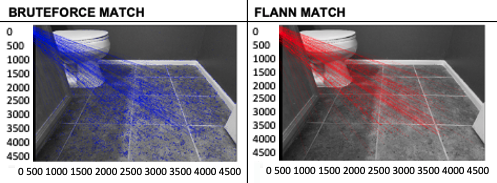
上图展示了我们如何应用 BFMatcher 和 FLANN 的 KNN 匹配器将单个瓷砖匹配到整个浴室地板。很明显,与 FLANN 匹配器(红线)相比,BFMatcher(蓝线)找到了更多的瓦片点。
前面描述的图像匹配技术也可用于查找两点之间的相对距离 - 一个点可以是参考点,例如拍摄图像的汽车,另一个可以是路上的另一辆车。然后使用该距离来开发防撞系统。
使用 Contours 和 HOG 检测器进行对象检测
轮廓是图像中具有相似形状的封闭区域。在本节中,我们将使用轮廓对图像中的简单对象进行分类和检测。我们将使用的图像由苹果和橙子组成,我们将使用 Contour 和 Canny 边缘检测方法来检测对象并将图像类名称写在边界框上。
轮廓检测
我们首先需要导入图像,然后使用 Canny 边缘检测器找到图像中的边缘。这非常有效,因为我们的对象的形状是带有圆边的圆形。以下是所需的详细代码:
threshold =100
canny_output = cv2.Canny(img, threshold, threshold * 2)
contours, hierarchy = cv2.findContours(canny_output, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
如上代码所示,在 Canny 边缘检测之后,我们应用了 OpenCVfindContours()方法。这个方法有三个参数:
- 图像,在我们的例子中是 Canny 边缘检测器的输出。
- 检索方法,有很多选项。我们使用的是一种外部方法,因为我们有兴趣在对象周围绘制一个边界框。
- 轮廓近似法。
检测边界框
该方法主要包括了解图像及其各种类别的特征以及开发对图像类别进行分类的方法。
请注意,OpenCV 方法不涉及任何训练。boundingRect对于每个轮廓,我们使用 OpenCV属性定义一个边界框。
我们将使用两个重要特征来选择边界框:
- 感兴趣区域的大小:我们将消除所有尺寸小于 的轮廓20。
请注意,这20不是通用数字,它仅适用于该图像。对于较大的图像,该值可以更大。
- 感兴趣区域的颜色:在每个边界框内,我们需要定义感兴趣区域的宽度,25%以75%确保我们不考虑圆外矩形的空白区域。这对于最小化变化很重要。接下来,我们使用 定义平均颜色CV2.mean。
我们将通过查看围绕它的三个橙色图像来确定颜色的平均阈值和最大阈值。以下代码使用OpenCV的内置方法来绘制边界框cv2.boundingRect。然后它根据宽度和高度选择绘制一个感兴趣区域( ROI ) 并找到该区域内的平均颜色:
count=0
font = cv2.FONT_HERSHEY_SIMPLEX
for c in contours:
x,y,w,h = cv2.boundingRect(c)
if (w >20 and h >20):
count = count+1
ROI = img[y+int(h/4):y+int(3*h/4), x+int(h/4):x+int(3*h/4)]
ROI_meancolor = cv2.mean(ROI)
print(count,ROI_meancolor)
if (ROI_meancolor[0] > 30 and ROI_meancolor[0] < 40 and ROI_meancolor[1] > 70 and ROI_meancolor[1] < 105
and ROI_meancolor[2] > 150 and ROI_meancolor[2] < 200):
cv2.putText(img, 'orange', (x-2, y-2), font, 0.8, (255,255,255), 2, cv2.LINE_AA)
cv2.rectangle(img,(x,y),(x+w,y+h),(255,255,255),3)
cv2.imshow('Contours', img)
else:
cv2.putText(img, 'apple', (x-2, y-2), font, 0.8, (0,0,255), 2, cv2.LINE_AA)
cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),3)
cv2.imshow('Contours', img)
在上面的代码中,请注意两个if语句——基于尺寸(w,h)和基于颜色(ROI_meancolor[0,1,2]):
- 基于大小的语句消除了所有小于 的等高线20。
- ROI_meancolor [0,1,2]表示平均颜色的 RGB 值。
在这里,第三、第四和第八行代表橙色,并且该语句if将颜色限制为在组件之间、组件之间、组件之间30以及组件之间。40B70105G150200R
输出如下。在我们的示例中3,4、 和8是橙色:
1 (52.949200000000005, 66.38640000000001, 136.2072, 0.0)
2 (43.677693761814744, 50.94659735349717, 128.70510396975425, 0.0)
3 (34.418282548476455, 93.26246537396122, 183.0893351800554, 0.0)
4 (32.792241946088104, 78.3931623931624, 158.78238001314926, 0.0)
5 (51.00493827160494, 55.09925925925926, 124.42765432098766, 0.0)
6 (66.8863771564545, 74.85960737656157, 165.39678762641284, 0.0)
7 (67.8125, 87.031875, 165.140625, 0.0)
8 (36.25, 100.72916666666666, 188.67746913580245, 0.0)
请注意,OpenCV 将图像处理为BGRnot RGB。
HOG探测器
定向梯度直方图( HOG ) 是一个有用的特征,可用于确定图像的局部图像强度。该技术可用于在图像中查找对象。本地化的图像梯度信息可用于寻找相似的图像。在此示例中,我们将使用scikit-image导入 HOG 并使用它来绘制图像的 HOG。您可能必须安装 scikit-image,如果尚未安装,请使用pip install scikit-image:
from skimage.feature import hog
from skimage import data, exposure
fruit, hog_image = hog(img, orientations=8, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True, multichannel=True)
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
cv2.imshow('HOG_image', hog_image_rescaled)
上述代码在我们的示例图像上的结果如下图所示:

在上图中,我们可以观察到以下内容:
- 左侧显示一个边界框,而右侧显示图像中每个对象的 HOG 梯度。
- 请注意,每个苹果和橙子都被正确检测到,有一个包围水果的边界框没有任何重叠。
- HOG 描述符显示一个矩形边界框,其中渐变显示圆形图案。
- 橙子和苹果之间的渐变呈现出类似的模式,唯一的区别是大小。
轮廓检测方法的局限性
上一小节中显示的示例在对象检测方面看起来非常好。我们不需要进行任何训练,只需稍微调整一些参数,我们就能够正确检测到橙子和苹果。但是,我们将添加以下变体,看看我们的检测器是否仍然能够正确检测到对象:
- 我们将添加苹果和橙子以外的对象。
- 我们将添加另一个形状与苹果和橙子相似的对象。
- 我们将改变光的强度和反射。
如果我们执行上一小节中的相同代码,它将检测每个对象,就好像它是一个苹果一样。这是因为选择的宽度和高度参数过于宽泛,包括所有对象以及 RGB 值,这些值在此图像中的显示与以前不同。为了正确检测对象,我们将对if大小和颜色的语句进行以下更改,如以下代码所示:
if (w >60 and w < 100 and h >60 and h <120):
if (ROI_meancolor[0] > 10 and ROI_meancolor[0] < 40 and ROI_meancolor[1] > 65 and ROI_meancolor[1] < 105
请注意,前面的更改对if语句施加了以前没有的约束。
RGB 颜色如下:
1 (29.87429111531191, 92.01890359168242, 182.84026465028356, 0.0) 82 93
2 (34.00568181818182, 49.73605371900827, 115.44163223140497, 0.0) 72 89
3 (39.162326388888886, 62.77256944444444, 148.98133680555554, 0.0) 88 96
4 (32.284938271604936, 53.324444444444445, 141.16493827160494, 0.0) 89 90
5 (12.990362811791384, 67.3078231292517, 142.0997732426304, 0.0) 84 84
6 (38.15, 56.9972, 119.3528, 0.0) 82 100
7 (47.102716049382714, 80.29333333333334, 166.3264197530864, 0.0) 86 90
8 (45.76502082093992, 68.75133848899465, 160.64901844140394, 0.0) 78 82
9 (23.54432132963989, 98.59972299168975, 191.97368421052633, 0.0) 67 76
前面代码在我们更改的图像上的结果如下所示:

在上图中可以看到遥控器、叉子、刀和塑料份杯。请注意苹果、橙子和塑料杯的 HOG 特征是如何相似的,这与预期的一样,因为它们都是圆形的:
- 塑料杯周围没有边界框,因为它没有被检测到。
- 与苹果和橙子相比,叉子和刀具有非常不同的角 HOG 形状。
- 遥控器为矩形 HOG 形状。
这个简单的例子表明,这种对象检测方法不适用于较大的图像数据集,我们需要调整参数以考虑各种光照、形状、大小和方向条件。这就是为什么我们将在本书的其余部分讨论 CNN。一旦我们使用这种方法在不同的条件下训练图像,它就会在新的一组条件下正确地检测到对象,而不管对象的形状如何。然而,尽管上述方法有局限性,我们还是学会了如何使用颜色和大小将一张图像与另一张图像分开。
ROI_meancolor是一种强大的方法,用于检测边界框中对象的平均颜色。例如,您可以使用它根据边界框内的球衣颜色、青苹果与红苹果或任何类型的基于颜色的分离方法来区分球员与一支球队与另一支球队。
TensorFlow、其生态系统和安装概述
在前面的部分中,我们介绍了计算机视觉技术的基础知识,例如图像转换、图像过滤、使用内核的卷积、边缘检测、直方图和特征匹配。这种理解及其各种应用应该为深度学习的高级概念奠定坚实的基础,这将在本书后面介绍。
计算机视觉中的深度学习是通过许多中间(隐藏)层的卷积运算,对许多不同的图像特征(如边缘、颜色、边界、形状等)进行累积学习,以获得对图像类型的完整理解。深度学习增强了计算机视觉技术,因为它堆叠了有关神经元行为方式的多层计算。这是通过组合各种输入以产生基于数学函数和计算机视觉方法(例如边缘检测)的输出来完成的。
TensorFlow 是一个端到端( E2E ) 机器学习平台,其中图像和数据被转换为张量以由神经网络处理。 例如,大小为 的图像224 x 224可以表示为 rank 的张量4,128, 224, 224, 3其中128是神经网络的批大小,224是高度和宽度,3是颜色通道(R、G 和 B)。
如果您的代码基于 TensorFlow 1.0,那么将其转换为 2.0 版本可能是最大的挑战之一。 按照https://www.tensorflow.org/guide/migrate中的说明转换到 2.0 版。大多数情况下,当您使用终端在 TensorFlow 中执行 Python 代码时, 转换问题会发生在低级 API中。
Keras 是 TensorFlow 的高级 API。 以下三行代码是安装 Keras 的起点:
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow import keras
如果您不使用最后一行,那么您可能必须from tensorflow.keras对所有功能使用导入。
TensorFlow 用于tf.data从简单的代码构建复杂的输入管道,从而简化和加速数据输入过程。您将在第 6 章,使用迁移学习进行视觉搜索。
在 Keras 中,模型的层以所谓的顺序堆叠在一起。这是由 引入的model=tf.keras.Sequential(),每一层都是使用model.add语句添加的。首先,我们需要使用编译模型model.compile,然后我们可以开始使用该model.train函数进行训练。
TensorFlow 模型保存为检查点和保存的模型。检查点捕获模型使用的参数、过滤器和权重的值。 检查点与源代码相关联。另一方面,保存的模型可以部署到生产环境中,不需要源代码。
TensorFlow 提供针对多个 GPU 的分布式训练。TensorFlow 模型输出可以使用 Keras API 或 TensorFlow 图进行可视化。
TensorFlow 与 PyTorch
PyTorch 是另一个类似于 TensorFlow 的深度学习库。它基于 Torch,由 Facebook 开发。TensorFlow 创建静态图,PyTorch 创建动态图。在 TensorFlow 中,必须首先定义整个计算图,然后运行模型,而在 PyTorch 中,可以与模型构建并行定义图。
TensorFlow 安装
要在您的 PC 上安装 TensorFlow 2.0,请在终端中键入以下命令。确保在每个命令后按Enter :
pip install --upgrade pip
pip install tensorflow
上述命令将在终端中下载并解压除 TensorFlow 之外的以下包:
- Keras(一种用Python编写的高级神经网络 API ,能够在 TensorFlow 之上运行)
- protobuf(结构化数据的序列化协议)
- TensorBoard(TensorFlow 的数据可视化工具)
- PyGPU(用于图像处理的Python功能,用于提高性能的 GPU 计算)
- cctools(Android 的原生 IDE)
- c-ares(库函数)
- clang(C、C++、Objective-C、OpenCL 和 OpenCV 的编译器前端)
- llvm(用于生成前端和后端二进制代码的编译器架构)
- theano(用于管理多维数组的Python库)
- grpcio(用于实现远程过程调用的PythongRPC包)
- libgpuarray(一个通用的 n 维 GPU 数组,可以被Python中的所有包使用)
- termcolor( Python中的颜色格式输出)
- absl(用于构建Python应用程序的Python库代码集合)
- mock(用虚拟环境代替真实物体来辅助测试)
- gast(用于处理Python抽象语法的库)
在安装过程中,当询问时按y表示是:
Downloading and Extracting Packages
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
如果一切安装正确,您将看到前面的消息。
安装后,根据您的 PC 是否只有 CPU 或 CPU 和 GPU 输入以下任一命令来检查 TensorFlow 版本。请注意,对于所有计算机视觉工作,首选 GPU 来加速图像的计算。用于Python 3.6 或更高版本pip3以及Python 2.7 :pip
pip3 show tensorflow
pip3 show tensorflow-gpu
pip show tensorflow
输出应显示以下内容:
Name: tensorflow
Version: 2.0.0rc0
Summary: TensorFlow is an open source machine learning framework for everyone.
Home-page: https://www.tensorflow.org/
Author: Google Inc.
Author-email: [email protected]
License: Apache 2.0
Location: /home/.../anaconda3/lib/python3.7/site-packages
Requires: gast, google-pasta, tf-estimator-nightly, wrapt, tb-nightly, protobuf, termcolor, opt-einsum, keras-applications, numpy, grpcio, keras-preprocessing, astor, absl-py, wheel, six
Required-by: gcn
有时,您可能会注意到,即使在安装了 TensorFlow 之后,Anaconda 环境也无法识别出安装了 TensorFlow。在这种情况下,最好在终端中使用以下命令卸载 TensorFlow,然后重新安装:
python3 -m pip uninstall protobuf
python3 -m pip uninstall tensorflow-gpu
概括
在本章中,我们学习了图像过滤如何通过卷积操作修改输入图像,以产生检测被称为边缘的特征的一部分的输出。这是计算机视觉的基础。正如您将在接下来的章节中学习的那样,图像过滤的后续应用会将边缘转换为更高级别的模式,例如特征。
我们还学习了如何计算图像直方图,使用 SIFT 执行图像匹配,以及使用轮廓和 HOG 检测器绘制边界框。我们学习了如何使用 OpenCV 的边界框颜色和大小方法将一个类与另一个类分开。本章最后介绍了 TensorFlow,这将为本书的其余章节奠定基础。
在下一章中,我们将学习一种不同类型的计算机视觉技术,称为模式识别,我们将使用它对具有模式的图像内容进行分类。
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。