深度学习模型中的池化层
池化层(Pooling Layer)是卷积神经网络(CNN)中常用的一种操作,用于减少特征图的空间尺寸(即高度和宽度),从而减小模型的计算量和参数数量,同时保持重要的特征信息。池化层的主要作用包括降维、防止过拟合、提高计算效率以及增强特征的平移不变性。
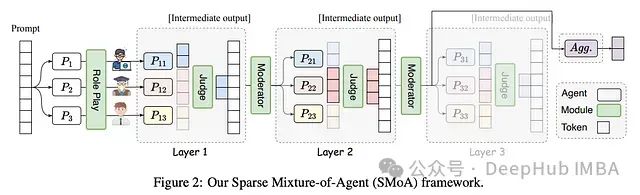
SMoA: 基于稀疏混合架构的大语言模型协同优化框架
通过引入稀疏化和角色多样性,SMoA为大语言模型多代理系统的发展开辟了新的方向。
通义千问AI PPT初体验:一句话、万字文档、长文本一键生成PPT!
通义千问AI PPT初体验:一句话、万字文档、长文本一键生成PPT!
开源模型应用落地-Qwen2-VL-7B-Instruct-vLLM-OpenAI API Client调用
使用OpenAI API接入方式调用Qwen2-VL-7B-Instruct模型进行推理
Audio Spectrogram Transformer (AST)工作介绍
Audio Spectrogram Transformer (AST),是一种基于 Transformer 模型的音频分类方法。AST 利用了 Transformer 模型在捕获全局特征方面的优势,将音频信号转换为频谱图进行处理。本文是对 AST 及其相关研究工作的详细介绍。
Ubuntu20.04版本的NVIDIA显卡驱动程序安装(宝宝级攻略)
我在学习深度学习时,在Ubuntu系统下安装NVIDIA显卡驱动踩过了一些坑,浪费了很多的时间,现在想出一个宝宝级的攻略,希望能够帮助大家节约时间,规避一些毒教程的糟粕。
【人工智能】掌握深度学习中的时间序列预测:深入解析RNN与LSTM的工作原理与应用
深度学习中的循环神经网络(RNN)和长短时记忆网络(LSTM)在处理时间序列数据方面具有重要作用。它们能够通过记忆前序信息,捕捉序列数据中的长期依赖性,广泛应用于金融市场预测、自然语言处理、语音识别等领域。本文将深入探讨RNN和LSTM的架构及其对序列数据进行预测的原理与优势,使用数学公式描述其内部
开源模型应用落地-Qwen2.5-7B-Instruct与vllm实现离线推理-使用Lora权重(三)
使用vLLM框架集成Lora权重,以实现高效的推理过程。
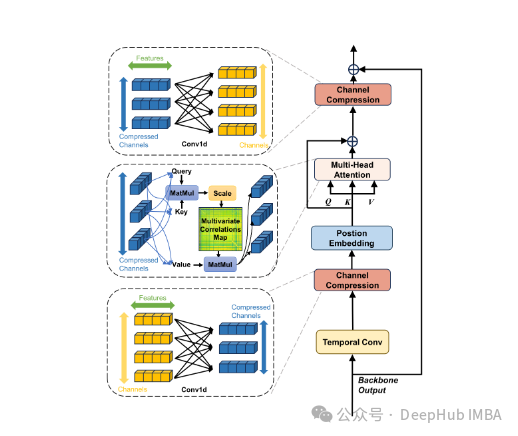
TSMamba:基于Mamba架构的高效时间序列预测基础模型
TSMamba通过其创新的架构设计和训练策略,成功解决了传统时间序列预测模型面临的多个关键问题。
序列到序列学习(Seq2seq)
(3)在选候选句子的时候,长句子往往预测的概率会更小一点,为了平衡选择的概率,有机会能尝到有机会能选到长一点的句子,通常是取一个log再取l的阿尔法次饭分之1去调整长句子的概率。这个向量空间是通过训练数据学习到的,向量的维度通常远小于词汇表的大小,生成的向量是密集的,维度通常远小于。(3)编码器通过
【深度学习实战】构建AI模型,实现手写数字自动识别
近年来,人工智能(AI)大模型在计算机科学领域引起了广泛的兴趣和关注。这些模型以其庞大的参数规模和卓越的性能,在各种领域展现了巨大的潜力。本文介绍如何构建一个AI模型,实现一个简单的手写数字识别任务。手写数字识别是一种利用计算机自动辨认人手写在纸张上的阿拉伯数字的技术。 这一技术属于光学字符识别
深度学习环境anaconda+pytorch+pycharm(终端)配置 (跟着我超简单)一步到位,python3.9
配置anaconda+pytorch+pycharm(终端)gpu版本,一篇带你解决深度学习环境配置烦恼
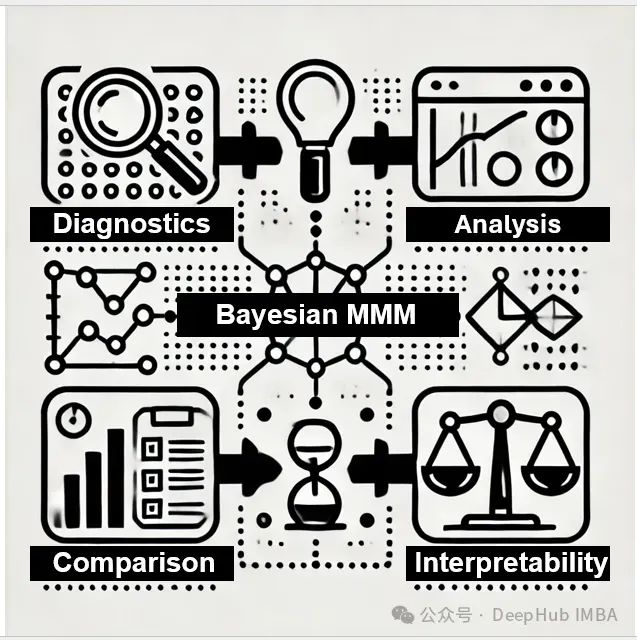
基于MCMC的贝叶斯营销组合模型评估方法论: 系统化诊断、校准及选择的理论框架
贝叶斯营销组合建模(Bayesian Marketing Mix Modeling,MMM)作为一种先进的营销效果评估方法,其核心在于通过贝叶斯框架对营销投资的影响进行量化分析。
开源模型应用落地-baichuan2模型小试-入门篇(三)
在linux环境下,使用transformer设置模型参数/System Prompt/历史对话
万字长文解读深度学习——循环神经网络RNN、LSTM、GRU、Bi-RNN
面试资料收集者之万字长文解读深度学习——循环神经网络RNN、LSTM、GRU、Bi-RNN
Tokenformer:基于参数标记化的高效可扩展Transformer架构
本文是对发表于arXiv的论文 “TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS” 的深入解读与扩展分析。主要探讨了一种革新性的Transformer架构设计方案,该方案通过参数标记化实现了模型的
开源模型应用落地-glm模型小试-glm-4-9b-chat-压力测试(六)
通过压力测试,评估模型在高负载或极端条件下的表现。

深度学习工程实践:PyTorch Lightning与Ignite框架的技术特性对比分析
在深度学习框架的选择上,PyTorch Lightning和Ignite代表了两种不同的技术路线。本文将从技术实现的角度,深入分析这两个框架在实际应用中的差异,为开发者提供客观的技术参考。
开源模型应用落地-qwen模型小试-入门篇(四)
使用gradio,构建Qwen-1_8B-Chat测试界面
海康威视 Vision Master 深度学习模块
Vision Master 深度学习模块



