Multimodal Sentiment Analysis论文汇总
多模态情绪分析论文汇总
LlamaIndex使用指南
LlamaIndex是一个方便的工具,它充当自定义数据和大型语言模型(llm)(如GPT-4)之间的桥梁,大型语言模型模型功能强大,能够理解类似人类的文本
tensorflow安装步骤(CPU版本,Anaconda环境下,Windows10)
本文主要讲述了在Anaconda环境下,CPU版本tensorflow2.3.0的安装步骤,Windows10系统中Anaconda的安装步骤可以阅读此篇博客:用Anaconda安装TensorFlow(Windows10)本文分为两大部分:一、TensorFlow2.3.0安装步骤二、对Tenso
手部数据太难找?最全手部开源数据集分享
本期将给大家介绍22个与手部检测、手势识别、手部图像分割等任务相关的公开数据集,包含第一人称、第三人称视角,可用于人机交互、手语翻译、3D建模等场景。
VideoPose3D:基于视频的3D人体关键点检测
VideoPose3D,一个基于视频的3D人体关键点检测模型
MedNeRF:用于从单个X射线重建3D感知CT投影的医学神经辐射场
计算机断层扫描(CT)是一种有效的医学成像方式,广泛应用于临床医学领域,用于各种病理的诊断。多探测器CT成像技术的进步实现了额外的功能,包括生成薄层多平面横截面身体成像和3D重建。然而,这涉及患者暴露于相当剂量的电离辐射。过量的电离辐射会对身体产生决定性的有害影响。本文提出了一种深度学习模型,该模
人工智能ChatGPT如何下载?
ChatGPT 是一个基于人工智能技术的自然语言处理模型,其可以通过学习大量的文本数据,自主生成符合语法、通顺、流畅的文本。ChatGPT 可以被广泛应用于智能客服、聊天机器人、自动摘要、机器翻译等领域,可以大幅提高人们的生产效率,使人与计算机之间的交互更加无缝,这使得 ChatGPT 的应用面非常
Adding Conditional Control to Text-to-Image Diffusion Models
代码 URL:https://github.com/lllyasviel/ControlNet。
人工智能专业毕业设计最新最全选题精华汇总-持续更新中
本文为人工智能专业学生提供了最新、最全的毕业设计选题推荐。人工智能作为当今科技领域的热门专业之一,其毕业设计选题的选择对学生的学术发展和职业前景至关重要。我们精心汇总了各个子领域的选题,包括机器学习、深度学习、自然语言处理、计算机视觉等,以满足学生们对不同研究方向的需求。这些选题既包括了理论研究和算
Ubuntu 22.04 安装Nvidia显卡驱动、CUDA、cudnn
GPU做深度学习比CPU要快很多倍,用Ubuntu跑也有一定的优势,但是安装Nvidia驱动有很多坑Ubuntu版本:22.04.3 LTS分区:/boot分配 1G ,剩下都分给根目录显卡:GTX 1050 Ti坑1:用Ubuntu自带的 Additional Drivers可能会出问题,应该从官
Pyinstaller打包报错小结
1.Pyinstaller打包exe文件,执行后提示缺失yaml,csv,dll等资源文件。2.打包后运行提示 WARNING: file already exists but should not: C:\Users\ADMINI~1\AppData\Local\Temp_MEI130922\to
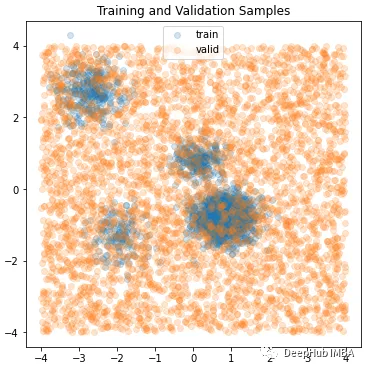
使用pytorch实现高斯混合模型分类器
本文是一个利用Pytorch构建高斯混合模型分类器的尝试。我们将从头开始构建高斯混合模型(GMM)。这样可以对高斯混合模型有一个最基本的理解,本文不会涉及数学,因为我们在以前的文章中进行过很详细的介绍。
深度学习:GPT1、GPT2、GPT-3
保存之前阶段训练的参数,在上述结构的基础上,去掉softmax层,然后加上一层全连接层与特定任务的softmax,然后用有标签的数据集训练,在这期间,半监督学习的参数可以选择处于冻结状态,然后只更新新的全连接层参数。GPT-1主要针对的是生成型NLP任务,如文本生成、机器翻译、对话系统等。GPT-2

使用Pytorch Geometric 进行链接预测代码示例
PyTorch Geometric (PyG)是构建图神经网络模型和实验各种图卷积的主要工具。在本文中我们将通过链接预测来对其进行介绍。
Stable-Baselines 3 部分源代码解读 3 ppo.py
阅读PPO相关的源码,了解一下标准库是如何建立PPO算法以及各种tricks的,以便于自己的复现。在Pycharm里面一直跳转,可以看到PPO类是最终继承于基类,也就是这个py文件的内容。所以阅读源码就先从这里开始。: )
【深度学习】GPT系列模型:语言理解能力的革新
大力出奇迹的语言模型!
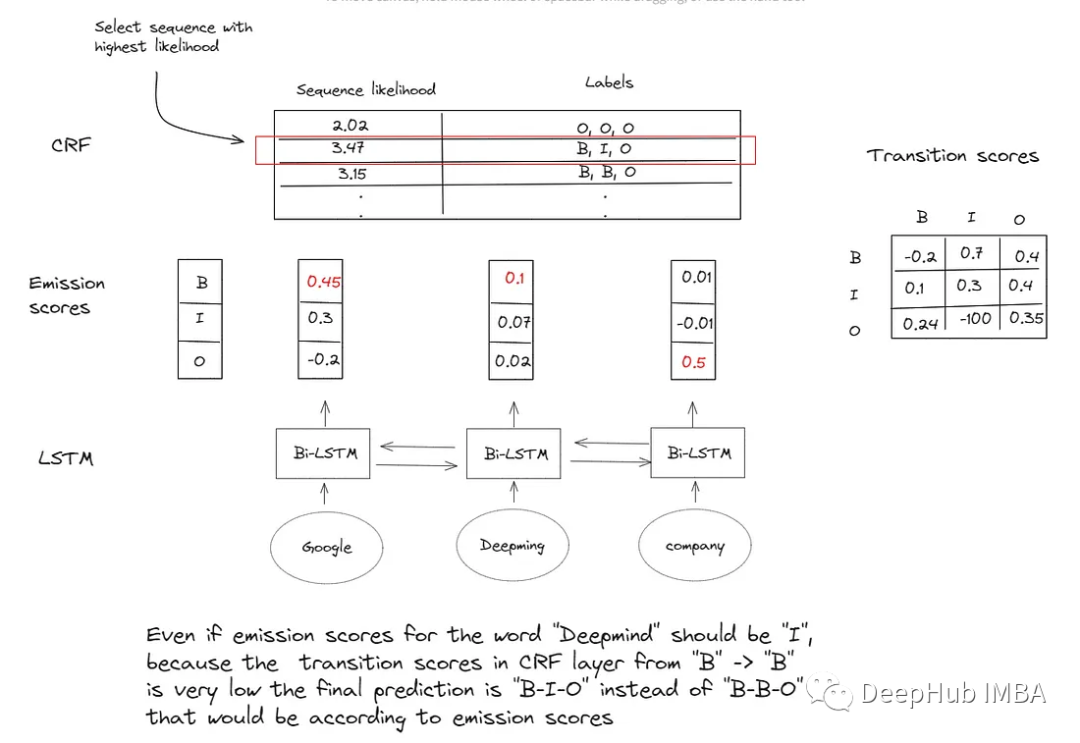
LSTM-CRF模型详解和Pytorch代码实现
本文中crf的实现并不是最有效的实现,也缺乏批处理功能,但是它相对容易阅读和理解,因为本文的目的是让我们了解crf的内部工作,所以它非常适合我们。
图像分割中常用数据集及处理思路(含代码)
一些分割常用的道路数据集,以及一个普遍适合的读入数据代码
【组会整理及心得】BiFormer、SICNet、IceNet
BRA、TSAM、海洋领域应用
【NLP相关】NLP领域经典论文汇总(附代码实现)
随着chat-gpt的爆火,越来越多的小伙伴们对NLP这个领域开始感兴趣。NLP设计多个领域,文本分类、文本摘要、机器翻译、信息抽取等等,本文对NLP领域的相关文献进行了梳理,筛选出一些必读文献和其他领域的基础文献,方便入门的小伙伴们学习。



