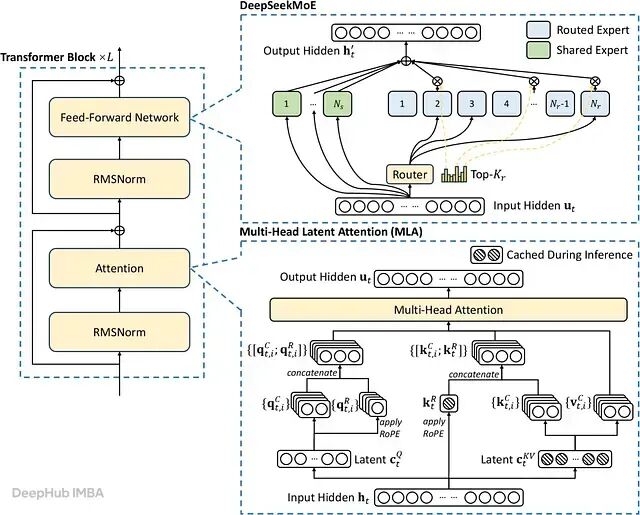
注意力架构变迁总结:稀疏、线性、SSM、混合架构如何摆脱 O(L²) 的代价
本文将介绍四条路线的原理、经过验证的基准测试数据,以及各自目前的生产落地情况。
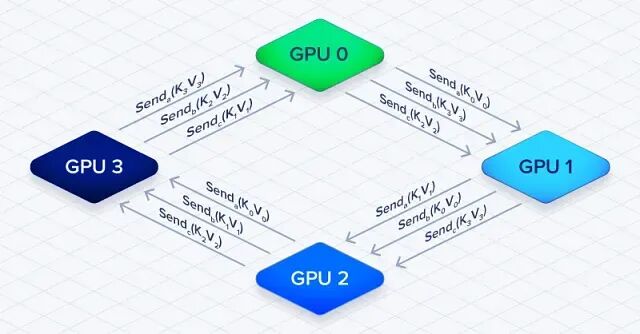
大模型如何训练百万 Token 上下文:上下文并行与 Ring Attention
上下文并行本质上是拿通信开销换内存空间,把输入序列切到多张 GPU 上,突破训练时的内存限制
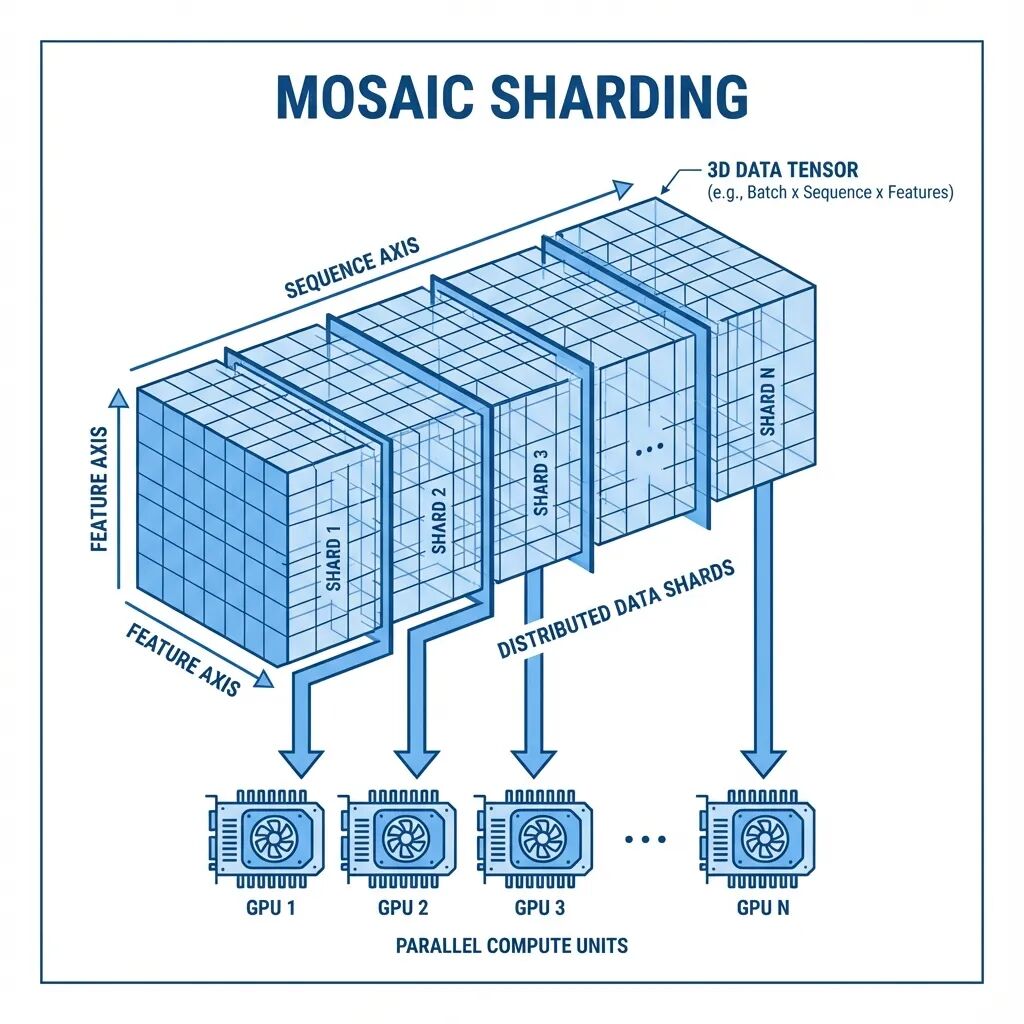
Mosaic:面向超长序列的多GPU注意力分片方案
本文从一个具体问题出发,介绍Mosaic这套多轴注意力分片方案的设计思路。
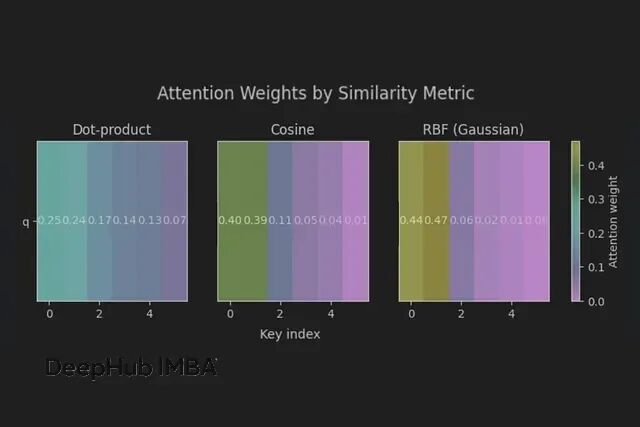
从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力就是一个带温控的概率邻居平均算法。温度设对了(1/sqrt(d)),邻域选对了(相似度+掩码),剩下的就是工程实现了。
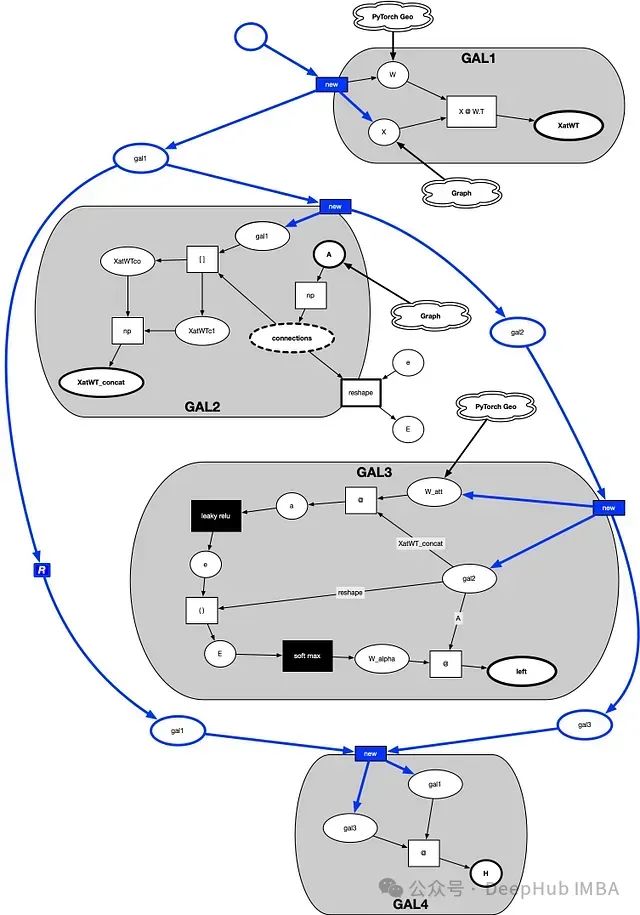
深入解析图神经网络注意力机制:数学原理与可视化实现
本文旨在通过可视化方法和数学推导,揭示图神经网络自注意力层的内部运作机制。我们将采用"位置-转移图"的概念框架,结合NumPy编程实现,一步步拆解自注意力层的计算过程,使读者能够直观理解注意力权重是如何生成并应用于图结构数据的。
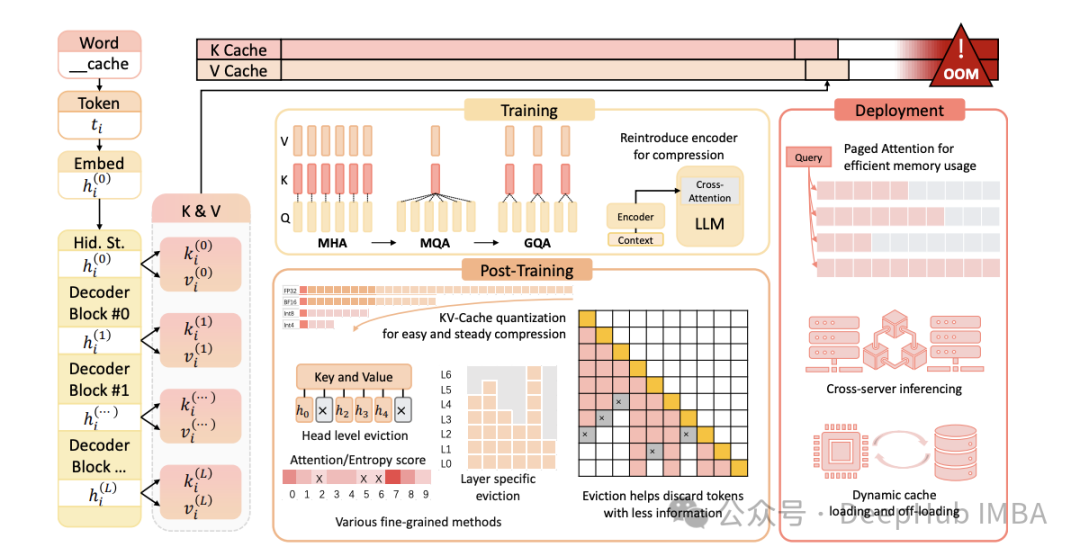
LLM高效推理:KV缓存与分页注意力机制深度解析
随着大型语言模型(LLM)规模和复杂性的持续增长,高效推理的重要性日益凸显。KV(键值)缓存与分页注意力是两种优化LLM推理的关键技术。本文将深入剖析这些概念,阐述其重要性,并探讨它们在仅解码器(decoder-only)模型中的工作原理。

基于结构化状态空间对偶性的贝叶斯注意力机制设计与实现
本文介绍了一种贝叶斯风格的注意力机制,用于序列预测。我们将详细阐述如何使用马尔可夫链蒙特卡罗法(MCMC)训练该模型。
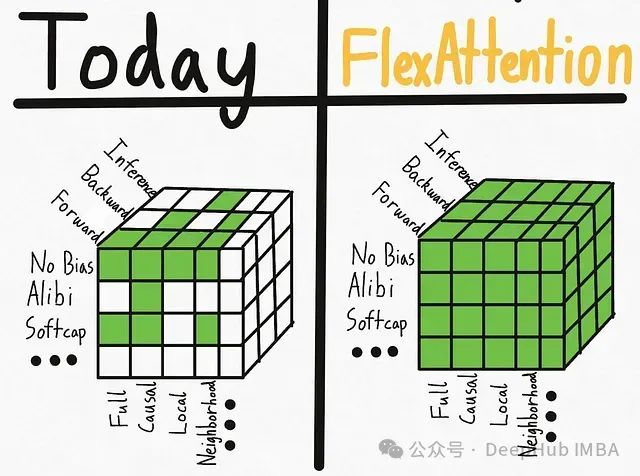
PyTorch FlexAttention技术实践:基于BlockMask实现因果注意力与变长序列处理
本文介绍了如何利用torch 2.5及以上版本中新引入的FlexAttention和BlockMask功能来实现因果注意力机制与填充输入的处理。
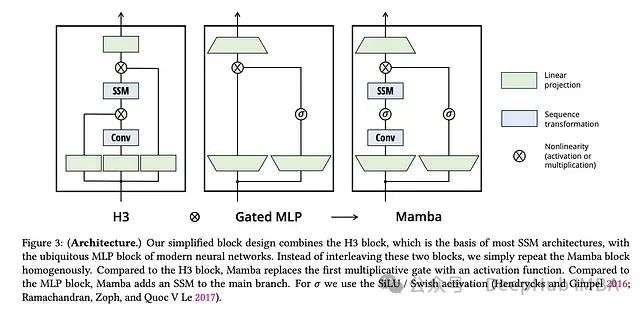
线性化注意力综述:突破Softmax二次复杂度瓶颈的高效计算方案
大型语言模型在各个领域都展现出了卓越的性能,但其核心组件之一——softmax注意力机制在计算资源消耗方面存在显著局限性。本文将深入探讨如何通过替代方案实现线性时间复杂度,从而突破这一计算瓶颈。
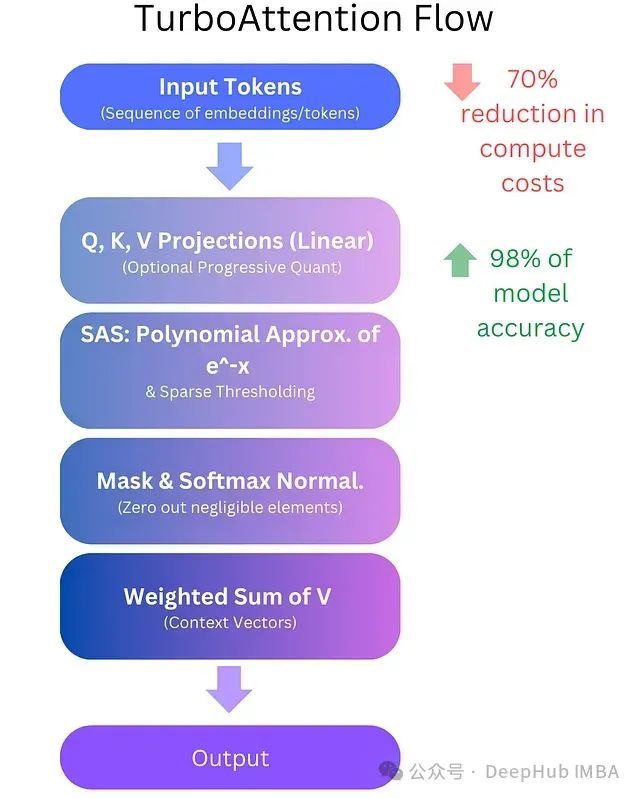
TurboAttention:基于多项式近似和渐进式量化的高效注意力机制优化方案,降低LLM计算成本70%
**TurboAttention**提出了一种全新的LLM信息处理方法。该方法通过一系列优化手段替代了传统的二次复杂度注意力机制,包括稀疏多项式软最大值近似和高效量化技术。
Spatial Attention Neural Network空间注意力网络介绍
这里定义了一个名为的类,它继承自nn.Module,是PyTorch中所有网络模块的基类。在初始化函数中,我们创建了一个序列模型,它包含一个卷积层和一个Sigmoid激活函数。卷积层的作用是提取空间特征,而Sigmoid函数将卷积层的输出转换为0到1之间的权重,这些权重将用于对输入特征图进行加权。类
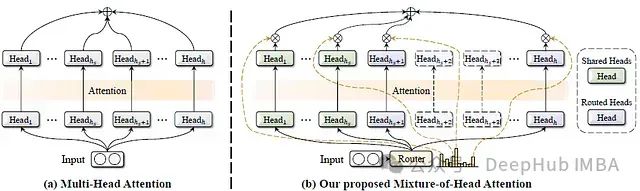
MoH:融合混合专家机制的高效多头注意力模型及其在视觉语言任务中的应用
这篇论文提出了一种名为混合头注意力(Mixture-of-Head attention, MoH)的新架构,旨在提高注意力机制的效率,同时保持或超越先前的准确性水平。

三种Transformer模型中的注意力机制介绍及Pytorch实现:从自注意力到因果自注意力
本文深入探讨Transformer模型中三种关键的注意力机制:自注意力、交叉注意力和因果自注意力。我们不仅会讨论理论概念,还将使用Python和PyTorch从零开始实现这些注意力机制。
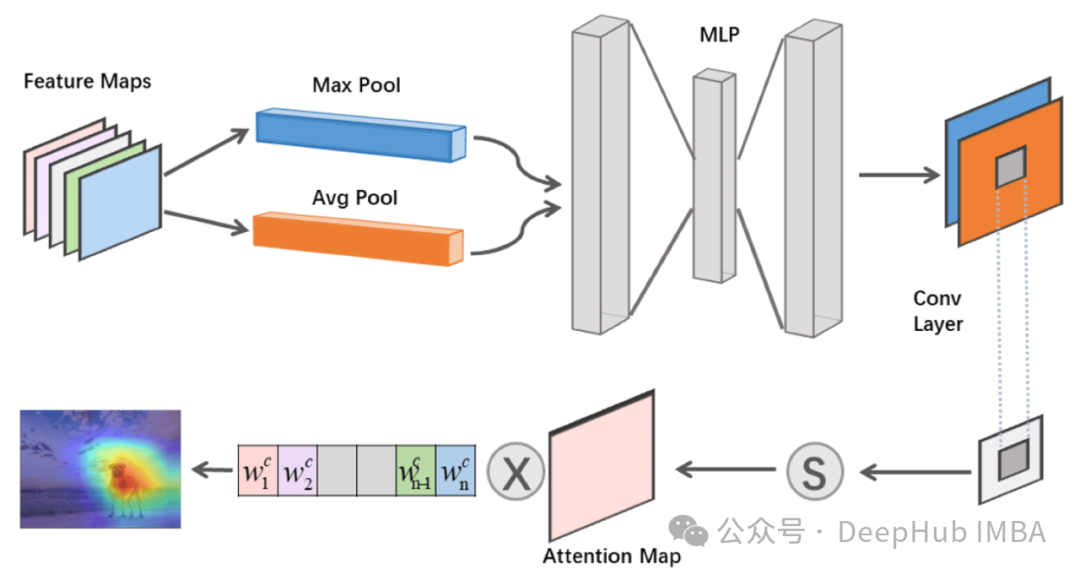
CNN中的注意力机制综合指南:从理论到Pytorch代码实现
本文将全面介绍CNN中的注意力机制,从基本概念到实际实现,为读者提供深入的理解和实践指导。
《Attention Is All You Need》解读
是一篇由Ashish Vaswani等人在2017年发表的论文,它在自然语言处理领域引入了一种新的架构——Transformer。这个架构现在被广泛应用于各种任务,如机器翻译、文本摘要、问答系统等。Transformer模型的核心是“自注意力”(self-attention)机制,这一机制能够有效捕

注意力机制中三种掩码技术详解和Pytorch实现
在这篇文章中,我们将探索在注意力机制中使用的各种类型的掩码,并在PyTorch中实现它们。
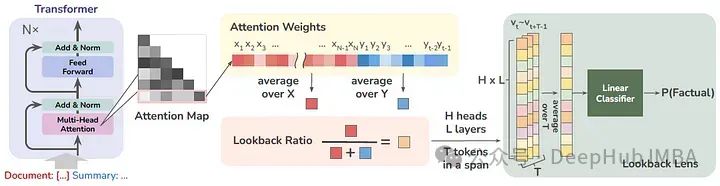
Lookback Lens:用注意力图检测和减轻llm的幻觉
这篇论文的作者提出了一个简单的幻觉检测模型,其输入特征由上下文的注意力权重与新生成的令牌(每个注意头)的比例给出。

长序列中Transformers的高级注意力机制总结
本文的重点是深入研究长序列种应用的高级注意力机制的数学复杂性和理论基础
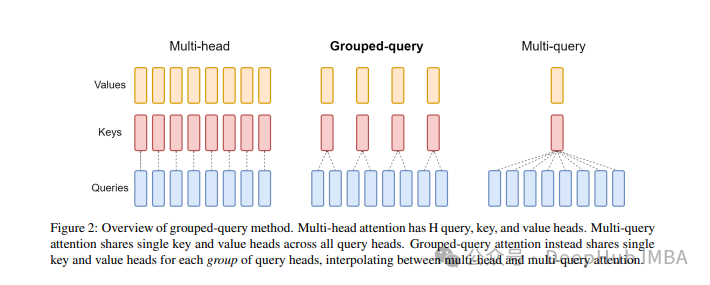
大模型中常用的注意力机制GQA详解以及Pytorch代码实现
分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法,它的目标是在保持 MQA 速度的同时实现 MHA 的质量。
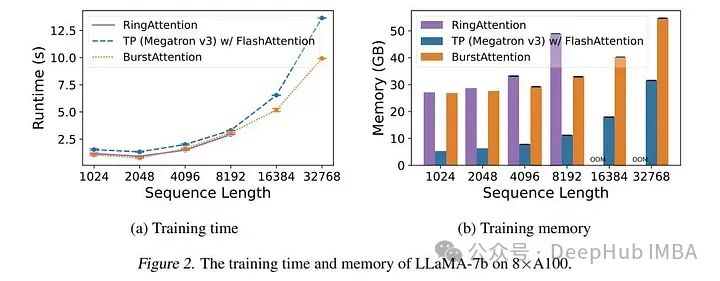
BurstAttention:可对非常长的序列进行高效的分布式注意力计算
而最新的研究BurstAttention可以将2者结合,作为RingAttention和FlashAttention之间的桥梁。
- 1
- 2



