
空间注意力可以看作是一种自适应的空间区域选择机制,空间注意力网络是一种深度学习架构,它通过在卷积神经网络(CNN)中引入注意力机制来增强模型对输入数据的特定空间区域的敏感度。这种机制使得网络能够自适应地聚焦于输入数据中最重要的部分,从而提高模型的性能和泛化能力。
一、空间注意力机制的原理
空间注意力机制的核心思想是让网络自己学习到哪些空间区域对于当前任务是重要的。空间注意力是先对通道进行全局平均或最大池化后,在空间层面求得注意力,我们可以通过一个可学习的权重矩阵来实现,该矩阵能够对输入特征图的每个像素位置分配一个权重。权重的计算通常基于输入特征图的某种变换,例如通过一个小型卷积层来提取特征,然后通过激活函数将权重归一化到0和1之间。
网络主结构: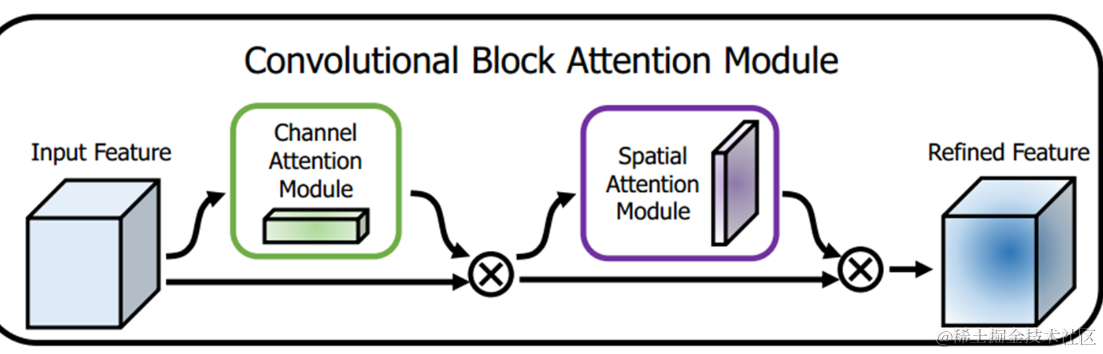
空间注意力机制使用SAM模块,在Darknet中,新添加的sam_layer层就是用于SAM模块,该层在darknet.h中的定义为sam. 其原理图如下:
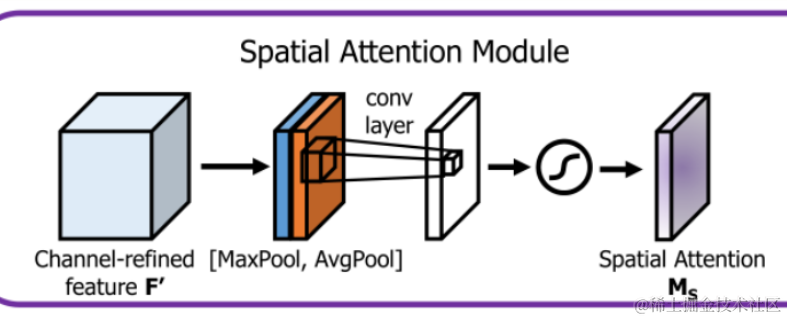
二、代码原理
首先,需要定义了一个
SpatialAttentionModule
类,它是一个包含空间注意力机制的模块。这个模块接收输入特征图
x
,然后通过以下步骤处理它:
- 平均池化:使用
torch.mean对输入特征图在通道维度dim=1上进行平均池化,得到形状为[b, 1, series, modal]的张量,其中b是批次大小,c是通道数,series和modal分别是序列长度和模态数。 - 注意力卷积:通过一个小型的卷积层
self.att_fc,该卷积层使用Conv2d定义,卷积核大小为(3, 1),步长为(1, 1),填充为(1, 0)。这个卷积层的作用是在时序轴上提取特征,同时保持模态轴不变。 - 激活函数:将卷积层的输出通过
Sigmoid激活函数,得到一个范围在0到1之间的注意力权重张量。 - 加权输出:将原始输入特征图与注意力权重相乘,得到加权后的特征图,这个操作允许网络在不同的空间位置应用不同的重要性。
接下来,我们定义了
SpatialAttentionNeuralNetwork
类,这是一个完整的空间注意力神经网络:
- 初始化:接收训练样本的形状
train_shape和类别数category。使用nn.Sequential定义了一系列卷积层、空间注意力模块、批量归一化层和ReLU激活函数。 - 自适应平均池化:使用
nn.AdaptiveAvgPool2d对特征图进行自适应平均池化,将特征图的大小调整为(1, train_shape[-1])。 - 全连接层:定义了一个全连接层
self.fc,将池化后的特征图展平并通过这个全连接层,输出类别数category的预测结果。 - 前向传播:在
forward方法中,首先通过定义的层进行特征提取,然后通过自适应平均池化和全连接层得到最终的输出。
三、代码实现
1.导入必要的库
import torch.nn as nn
import torch
导入PyTorch库,特别是
torch.nn
模块,它包含了构建神经网络所需的各种层和功能。
2.定义空间注意力模块
classSpatialAttentionModule(nn.Module):def__init__(self):super().__init__()
self.att_fc = nn.Sequential(
nn.Conv2d(1,1,(3,1),(1,1),(1,0)),
nn.Sigmoid())
这里定义了一个名为
SpatialAttentionModule
的类,它继承自
nn.Module
,是PyTorch中所有网络模块的基类。在初始化函数中,我们创建了一个序列模型
self.att_fc
,它包含一个卷积层和一个Sigmoid激活函数。卷积层的作用是提取空间特征,而Sigmoid函数将卷积层的输出转换为0到1之间的权重,这些权重将用于对输入特征图进行加权。
3.前向传播函数
defforward(self, x):
att = torch.mean(x, dim=1, keepdim=True)# [b, c, series, modal] -> [b, 1, series, modal]
att = self.att_fc(att)# [b, 1, series, modal]
out = x * att
return out
forward
函数定义了模块如何处理输入数据
x
。首先,使用
torch.mean
函数沿通道维度对输入数据进行平均,得到形状为
[b, 1, series, modal]
的张量,其中
b
是批次大小,
1
是新的通道数,
series
和
modal
分别是序列长度和模态数。然后,将这个平均张量传递给
self.att_fc
,得到注意力权重。最后,将输入数据与注意力权重相乘,实现加权。
4.定义空间注意力神经网络
classSpatialAttentionNeuralNetwork(nn.Module):def__init__(self, train_shape, category):super(SpatialAttentionNeuralNetwork, self).__init__()
SpatialAttentionNeuralNetwork
类同样继承自
nn.Module
。在初始化函数中,接收两个参数:
train_shape
表示训练数据的形状,
category
表示类别的数量。
5.构建网络层
self.layer = nn.Sequential(# 定义网络层)
这里使用
nn.Sequential
来构建网络的层级结构。每个元素都是一个网络层,它们将按照顺序被添加到序列中。
6.添加卷积层和空间注意力模块
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
SpatialAttentionModule(),
nn.BatchNorm2d(num_features),
nn.ReLU(),
在序列中,我们添加了多个卷积层,每个卷积层后面紧跟一个空间注意力模块,然后是批量归一化层
BatchNorm2d
和ReLU激活函数。这样的结构可以帮助网络在不同层次上学习到空间特征,并在训练过程中稳定和加速收敛。
7.自适应平均池化层
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
这里添加了一个自适应平均池化层,它可以根据输入特征图的大小自动调整池化窗口的大小,使得无论输入特征图的大小如何,输出的特征图都能具有统一的维度。
8.全连接层
self.fc = nn.Linear(in_features, out_features)
定义了一个全连接层,它将自适应平均池化后的一维特征向量映射到类别数
category
的输出空间。
9.网络的前向传播
defforward(self, x):
x = self.layer(x)
x = self.ada_pool(x)
x = x.view(x.size(0),-1)
x = self.fc(x)return x
在
forward
函数中,首先将输入数据
x
通过
self.layer
进行特征提取,然后通过自适应平均池化层
self.ada_pool
进行池化,接着将池化后的张量展平为一维向量,最后通过全连接层
self.fc
得到最终的分类结果。
四、总结思考
空间注意力网络的核心优势在于其能够自适应地识别并强化输入数据中的关键信息。这种能力使得网络在处理复杂数据时,能够更加精准地捕捉到对任务至关重要的特征。以下是我对空间注意力网络的一些实际思考:
- 实际应用中的灵活性:空间注意力模块的设计允许它被轻松集成到现有的神经网络架构中,无论是用于图像识别还是视频分析,都能提供额外的性能提升。
- 性能与效率的平衡:虽然注意力机制增加了模型的复杂性,但通过精心设计,可以确保这种复杂性不会过度消耗计算资源,实现性能与效率的平衡。
- 对数据的敏感性:空间注意力网络对输入数据的敏感性是其最大的卖点。它能够自动学习到哪些特征是重要的,这在医学图像分析等领域尤其有用,因为这些领域的数据通常包含大量冗余信息。
- 模型设计的迭代:在设计空间注意力网络时,需要不断迭代和优化。例如,可以通过实验不同的卷积核大小、步长或填充来找到最佳的网络配置。
通过这些思考,可以看出空间注意力网络是一个充满潜力的研究方向,它在实际应用中展现出了强大的能力,但同时也需要我们在设计和实现时进行深思熟虑。
版权归原作者 是Dream呀 所有, 如有侵权,请联系我们删除。