

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
前言
随着金融数据的不断增长和复杂化,传统的统计方法和机器学习技术面临着挑战。深度学习算法通过多层神经网络的构建,以及大规模数据的训练和优化,可以从数据中提取更加丰富、高级的特征表示,从而提供更准确、更稳定的预测和决策能力。
在金融领域,深度学习算法已经被广泛应用于多个关键任务。首先,风险评估是金融机构必须面对的重要问题之一。深度学习算法可以通过学习大规模的历史数据,识别隐藏在数据中的潜在风险因素,并预测未来的风险情况。其次,欺诈检测是金融行业必不可少的任务。深度学习算法可以通过对交易模式和用户行为的建模,发现异常模式和欺诈行为,提高金融机构对欺诈的识别和预防能力。
此外,深度学习算法在金融交易方面也发挥着重要作用。通过对市场数据、历史交易数据和其他相关信息进行建模和预测,深度学习算法可以帮助交易员做出更明智的交易决策,并提高交易策略的效果和收益。
然而,深度学习算法在金融领域的应用也面临着一些挑战和限制。首先,数据的质量和可靠性对算法的性能至关重要。其次,算法的可解释性和可信度也是金融监管和风控部门关注的重点。因此,在深度学习算法的发展和应用过程中,仍然需要进一步探索和研究,以确保其在金融领域的可靠性和稳定性。
本文将简要介绍使用长短期记忆网络(LSTM)模型来处理时间序列预测问题,使用茅台股票数据继续案例演示,以便读者能在代码基础上结合自己的数据集和应用场景进行拓展。
长短期记忆网络
长短期记忆网络 (Long Short-Term Memory, LSTM)是一种递归神经网络 (RNN) 的类型,专门用于处理序列预测问题。与传统的RNN不同,LSTM可以有效地捕捉时间序列数据中的长期依赖关系,因此在金融领域非常有用。
这些网络包含能够在长序列中存储信息的记忆单元,使其能够克服传统RNN中的梯度消失问题。LSTM能够记住和利用过去的信息,使其适用于分析金融时间序列数据,如股票价格或经济指标。
应用案例:LSTM在金融领域有多种应用,例如股票价格预测、算法交易、投资组合优化和欺诈检测。它们还可以分析经济指标以预测市场趋势,帮助投资者做出更明智的决策。
这里是一个使用Python实现LSTM的示例代码:
from keras.models import Sequential
from keras.layers import LSTM, Dense
# define the model
model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, feature_dim)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit the model to the training data
model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))
上面代码是简化了,需要带入数据变量才能运行。下面我们将使用茅台股票数据进行详细的操作演示,仅供大家参考学习。
实战案例
1.实验环境
Python3.9
代码编辑工具:jupyter notebook
2.读取数据
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
# 读取茅台股票数据并将date日期作为索引
data = pd.read_csv('maotai_stock.csv',index_col='date')
data
3.准备训练数据
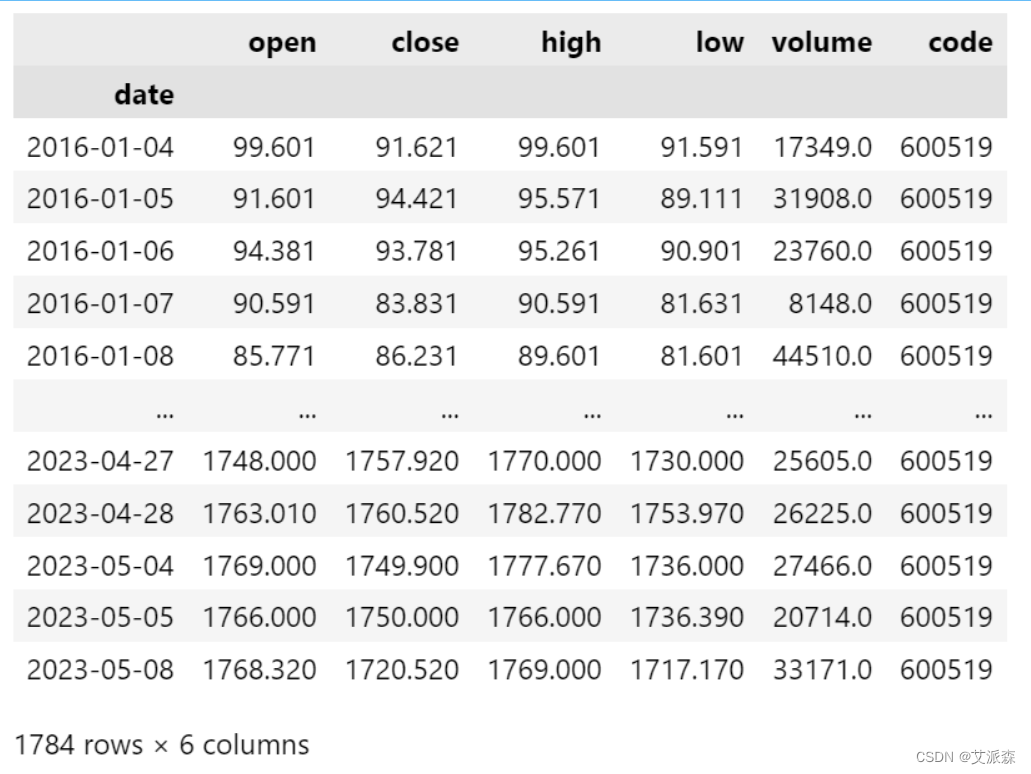
首先从原始数据集中提取出2022年之前的收盘价作为训练数据
# 提取训练数据
new_data = data['close'] # 我们预测的是收盘价,所以单独提取出close收盘价数据
train_data = new_data[:'2022'] # 将2022年之前的收盘价数据作为训练数据
train_prices = train_data.values.reshape(-1, 1)
train_prices
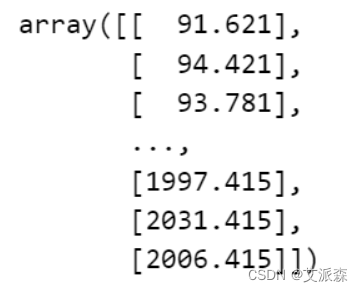
接着对训练数据做归一化处理
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
train_scaled = scaler.fit_transform(train_prices)
train_scaled
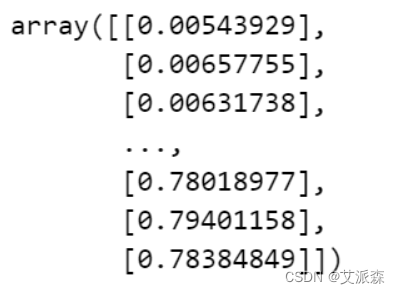
最后创建我们的训练数据集
# 创建训练数据集
X_train = []
y_train = []
timesteps = 30 # 时间步长,可根据需求进行调整
for i in range(timesteps, len(train_scaled)):
X_train.append(train_scaled[i - timesteps:i, 0])
y_train.append(train_scaled[i, 0])
# 讲训练数据转为数组形式
X_train, y_train = np.array(X_train), np.array(y_train)
# 调整输入数据的维度
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_train
4.训练模型
构建LSTM模型并编译拟合
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X_train.shape[1], 1)))
model.add(LSTM(50))
model.add(Dense(1))
# 编译模型
model.compile(loss='mean_squared_error', optimizer='adam')
# 拟合模型
model.fit(X_train, y_train, epochs=50, batch_size=32)

5.模型预测
模型训练好后,我们需要准备测试数据进行模型测试
# 提取测试数据
test_data = new_data['2022':] # 将2022年之后的数据作为测试数据
test_prices = test_data.values.reshape(-1, 1)
# 数据归一化
test_scaled = scaler.transform(test_prices)
# 创建测试数据集
X_test = []
y_test = []
for i in range(timesteps, len(test_scaled)):
X_test.append(test_scaled[i - timesteps:i, 0])
y_test.append(test_scaled[i, 0])
# 将测试数据转为数组形式
X_test, y_test = np.array(X_test), np.array(y_test)
# 调整输入数据的维度
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
X_test
使用模型对测试数据继续预测
# 使用模型进行预测
predicted_prices = model.predict(X_test)
predicted_prices
6.预测结果可视化
最后使用matplotlib将模型预测的结果与测试数据进行可视化对比,直观展现模型的预测效果。
# 预测结果可视化
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
# 反归一化训练集和测试集的价格数据
train_prices_scaled = scaler.inverse_transform(train_scaled)
test_prices_scaled = scaler.inverse_transform(test_scaled)
# 反归一化预测结果
predicted_prices_scaled = scaler.inverse_transform(predicted_prices)
# 创建日期索引
test_dates = pd.to_datetime(test_data.index[timesteps:])
plt.figure(figsize=(15, 7))
plt.plot(test_dates, test_prices_scaled[timesteps:], label='茅台股票收盘价-测试数据')
plt.plot(test_dates, predicted_prices_scaled, label='LSTM预测收盘价格')
plt.legend()
plt.show()
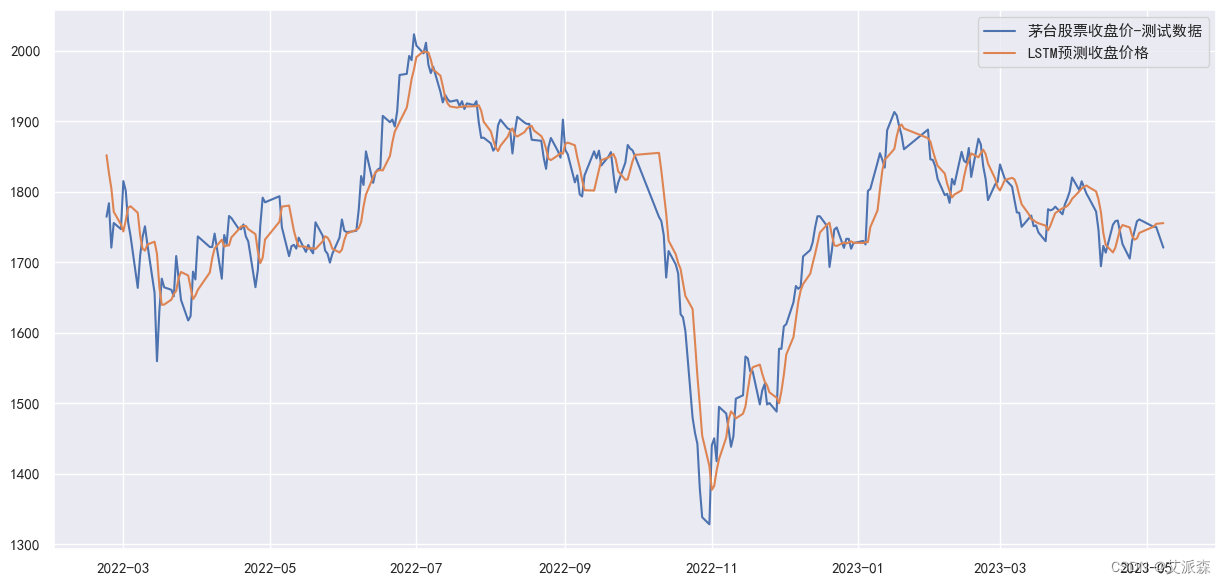
从可视化结果可以看出,蓝色线是真实数据,橙色线是模型预测数据,整体趋势相差不大,说明模型效果还不错。
文末福利
《产业链金融平台设计与实现》免费送书3人!

内容简介:
本书从产业链金融的起源讲起,结合实际案例讲解产业链金融平台的前台设计、技术中台设计、数据平台设计、风控设计及信息安全的核心要点,既体现了传统行业的业务创新、数字转型的探索过程,又介绍了当前主流银行的开放性建设成果。读者不但能全方位地了解产业链金融平台的建设过程,还能针对自己感兴趣的方面进行深入学习。 本书共6章,第1章介绍了产业链金融的发展、变革历程,以及对传统企业的核心价值;第2章介绍了系统核心功能的设计及在线签约、实名认证等技术的原理;第3章介绍了结合容器云技术、微服务技术与DevOps技术构建技术中台的过程,以及对接开放银行、央行征信的过程;第4章介绍了开源大数据平台的建设及数据仓库的设计思路;第5章基于Python的机器学习库介绍了智能风控的开发过程;第6章介绍了在产业链金融平台建设过程中如何规避信息安全的法律风险。 本书内容全面,且围绕开源技术展开介绍,实用性极强,特别适合建设产业链金融平台的传统企业架构师、开发人员及产品人员阅读,也适合对开源的技术中台、大数据平台及信用风控感兴趣的开发人员阅读。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-06-11 20:00:00
- ** 京东自营店购买链接**:https://item.jd.com/13797946.html
**名单公布时间:2023-06-11 21:00:00 **
本文转载自: https://blog.csdn.net/m0_64336780/article/details/131090710
版权归原作者 艾派森 所有, 如有侵权,请联系我们删除。
版权归原作者 艾派森 所有, 如有侵权,请联系我们删除。