
Python自动人工智能训练数据增强工具 | DALI介绍(含代码)

文章目录
深度学习模型需要数百 GB 的数据才能很好地概括未见过的样本。 数据扩充有助于增加数据集中示例的可变性。
当数据增强的选择依赖于设置模型训练的工程师的领域知识、技能和直觉时,传统的数据增强方法可以追溯到统计学习。
出现了自动增强以减少对手动数据预处理的依赖。 它结合了应用自动调整和根据概率分布随机选择增强的想法。
事实证明,使用自动数据增强方法(例如 AutoAugment 和 RandAugment)可以通过使模型在训练中看到的样本多样化来提高模型的准确性。 自动增强使数据预处理更加复杂,因为批次中的每个样本都可以使用不同的随机增强进行处理。
在这篇文章中,我们介绍了如何实现和使用 GPU 加速的 NVIDIA DALI自动增强工具来优化训练数据。
自动数据增强方法
自动增强基于标准图像变换,如旋转、剪切、模糊或亮度调整。 大多数操作接受一个称为幅度的控制参数。 量级越大,说明操作对图像的影响越大。
传统上,增强策略是由工程师手写的固定操作序列。 自动增强策略与传统策略的区别在于增强和参数的选择不是固定的,而是概率性的。
AutoAugment 使用强化学习从数据中学习最佳概率增强策略,将目标模型的泛化视为奖励信号。 使用 AutoAugment,我们发现了图像数据集的新策略,如 ImageNet、CIFAR-10 和 SVHN,超过了最先进的精度。
AutoAugment 策略是一组增强对。 每个增强都用应用或跳过操作的幅度和概率进行参数化。 运行策略时,随机选择并应用其中一对,独立于每个样本。
学习策略意味着寻找最好的增强对、它们的大小和概率。 目标模型必须在策略搜索过程中多次重新训练。 这使得策略搜索的计算成本变得巨大。
为避免计算成本高昂的搜索步骤,您可以重用在类似任务中找到的现有策略。 或者,您可以使用旨在使搜索步骤最少的其他自动数据扩充方法。
RandAugment 将策略搜索步骤减少到仅调整两个数字:N 和 M。N 是要在序列中应用的随机选择操作的数量,M 是所有操作共享的大小。 尽管 RandAugment 很简单,但我们发现这种数据增强方法在与相同的增强集一起使用时优于 AutoAugment 发现的策略。
TrivialAgument 通过删除两个超参数建立在 RandAugment 之上。 我们建议为每个样本应用一个随机选择的单一增强。 TrivialAugment 和 RandAugment 之间的区别在于幅度不是固定的,而是随机均匀采样的。
结果表明,在训练期间随机抽样增强对于模型泛化可能比广泛搜索仔细调整的策略更重要。
从 1.24 版开始,DALI 附带了 AutoAugment、RandAugment 和 TrivialAugment 的即用型实现。 在本文中,我们将向您展示如何使用所有这些最先进的实现,并讨论 DALI 中作为其实现支柱的新条件执行功能。
DALI 和条件执行
现代 GPU 架构显着加快了深度学习模型的训练速度。 然而,为了实现最大的端到端性能,模型使用的批量数据必须快速预处理以避免 CPU 瓶颈。
NVIDIA DALI 通过异步执行、预取、专用加载器、一组丰富的面向批处理的增强以及与 PyTorch、TensorFlow、PaddlePaddle 和 MXNet 等流行的 DL 框架的集成克服了这一预处理瓶颈。
为了创建数据处理管道,我们在 Python 函数中组合了所需的操作,并使用
@pipeline_def
修饰该函数。 出于性能原因,该函数仅定义 DALI 的执行计划,然后由 DALI 执行程序异步运行。
以下代码示例显示了一个管道定义,用于加载、解码图像并将随机噪声增强应用到图像。
from nvidia.dali import pipeline_def, fn, types
@pipeline_def(batch_size=8, num_threads=4, device_id=0)defpipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
image = fn.decoders.image(encoded, device="mixed")
prob = fn.random.uniform(range=[0,0.15])
distorted = fn.noise.salt_and_pepper(image, prob=prob)return distorted

管道的代码是面向样本的,而输出是一批图像。 指定运算符时无需处理批处理,因为 DALI 在内部进行管理。
然而,直到现在,还无法表达对批次中的样本子集起作用的操作。 这阻止了 DALI 自动增强的实现,因为它会为每个样本随机选择不同的操作。
DALI 中引入的条件执行使您能够使用常规 Python 语义为批次中的每个样本选择单独的操作:if 语句。 以下代码示例随机应用两个扩充之一。
@pipeline_def(batch_size=4, num_threads=4, device_id=0,
enable_conditionals=True)defpipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
image = fn.decoders.image(encoded, device="mixed")
change_stauration = fn.random.coin_flip(dtype=types.BOOL)if change_stauration:
distorted = fn.saturation(image, saturation=2)else:
edges = fn.laplacian(image, window_size=5)
distorted = fn.cast_like(0.5* image +0.5* edges, image)return distorted
在下图中,我们根据 fn.random.coin_flip 结果增加了一些样本的饱和度,并在其他样本中使用拉普拉斯算子检测了边缘。 DALI 将 if-else 语句翻译成一个执行计划,根据 if 条件将批处理分成两个批处理。 这样,部分批次将分别并行处理,而落入同一 if-else 分支的样本仍然受益于批处理的 CUDA 内核。

您可以轻松地扩展该示例以使用从任意集合中随机选择的扩充。 在下面的代码示例中,我们定义了三个扩充并实现了一个选择运算符,它根据随机选择的整数选择正确的一个。
defedges(image):
edges = fn.laplacian(image, window_size=5)return fn.cast_like(0.5* image +0.5* edges, image)defrotation(image):
angle = fn.random.uniform(range=[-45,45])return fn.rotate(image, angle=angle, fill_value=0)defsalt_and_pepper(image):return fn.noise.salt_and_pepper(image, prob=0.15)defselect(image, operation_idx, operations, i=0):if i >=len(operations):return image
if operation_idx == i:return operations[i](image)return select(image, operation_idx, operations, i +1)
在下面的代码示例中,我们选择了一个随机整数,并在 DALI 管道内使用 select 运算符运行了相应的操作。
@pipeline_def(batch_size=6, num_threads=4, device_id=0,
enable_conditionals=True)defpipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
image = fn.decoders.image(encoded, device="mixed")
operations =[edges, rotation, salt_and_pepper]
operation_idx = fn.random.uniform(values=list(range(len(operations))))
distorted = select(image, operation_idx, operations)return distorte
结果,我们得到了一批图像,其中每个图像都通过一个随机选择的操作进行了变换:边缘检测、旋转和椒盐噪声失真。

在上图中,管道对每个图像应用随机选择的增强:旋转、边缘检测或椒盐失真。
使用 DALI 自动增强
通过按样本选择运算符,您可以实现自动扩充。 为了便于使用,NVIDIA 在 DALI 中引入了 auto_aug 模块,其中包含流行自动增强的即用型实现:auto_aug.auto_augment、auto_aug.rand_augment 和 auto_aug.trivial_augment。 它们可以开箱即用,也可以通过调整增强幅度或构建用户定义的 DALI 原语增强来定制。
DALI 中的 auto_aug.augmentations 模块提供了一组由自动增强过程共享的默认操作:
- auto_contrast
- brightness
- color
- contrast
- equalize
- invert
- posterize
- rotate
- sharpness
- shear_x
- shear_y
- solarize
- solarize_add
- translate_x
- translate_y
以下代码示例显示如何运行 RandAugment。
import nvidia.dali.auto_aug.rand_augment as ra
@pipeline_def(batch_size=6, num_threads=4, device_id=0,
enable_conditionals=True)defpipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
shape = fn.peek_image_shape(encoded)
image = fn.decoders.image(encoded, device="mixed")
distorted = ra.rand_augment(image, n=3, m=15, shape=shape, fill_value=0)return distorted
rand_augment 运算符接受解码后的图像、图像的形状、要在序列中应用的随机增强数 (n=3) 以及这些操作应具有的幅度(m=15,超出可自定义的 [0, 30] 范围 ).

上图中的增强分为两类:几何和颜色变换。
在某些应用程序中,您可能必须限制使用的扩充集。 例如,如果数据集由数字图片组成,将数字“9”旋转 180 度会使关联标签无效。 以下代码示例使用一组有限的扩充运行 rand_augment。
from nvidia.dali.auto_aug import augmentations as a
augmentations =[
a.shear_x.augmentation((0,0.3), randomly_negate=True),
a.shear_y.augmentation((0,0.3), randomly_negate=True),
a.translate_x.augmentation((0,0.45), randomly_negate=True),
a.translate_y.augmentation((0,0.45), randomly_negate=True),
a.rotate.augmentation((0,30), randomly_negate=True),]
每个增强都可以用幅度如何映射到转换强度来参数化。 例如,a.rotate.augmentation((0, 30)) 指定您要将图像旋转不超过 30 度的角度。 randomly_negate=True 指定角度应随机取反,以便您随机顺时针或逆时针旋转图像。
以下代码示例以类似于 RandAugment 的方式应用扩充。
@pipeline_def(batch_size=8, num_threads=4, device_id=0,
enable_conditionals=True)defpipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
shape = fn.peek_image_shape(encoded)
image = fn.decoders.image(encoded, device="mixed")
distorted = ra.apply_rand_augment(augmentations, image, n=3, m=15, shape=shape, fill_value=0)return distorted
前两个管道定义之间的唯一区别是您使用了更通用的 apply_rand_augment 运算符,该运算符接受附加参数,即扩充列表。
接下来,将自定义扩充添加到集合中。 以抠图为例。 它使用 DALI fn.erase 函数用归零矩形随机覆盖图像的一部分。 用
@augmentation
装饰器包装 fn.erase ,它描述了如何将幅度映射到剪切矩形中。 cutout_size 是一个大小在 0.01 到 0.4 范围内的元组,而不是普通大小。
from nvidia.dali.auto_aug.core import augmentation
defcutout_shape(size):# returns the shape of the rectanglereturn[size, size]@augmentation(mag_range=(0.01,0.4), mag_to_param=cutout_shape)defcutout(image, cutout_size, fill_value=None):
anchor = fn.random.uniform(range=[0,1], shape=(2,))return fn.erase(image, anchor=anchor, shape=cutout_size, normalized=True, centered_anchor=True, fill_value=fill_value)
augmentations +=[cutout]
要进行更改,请运行自定义的几何增强集,例如 TrivialAugment,即使用随机大小。 对代码的改动很小; 您从 aut_aug 模块导入并调用 trivial_augment 而不是 rand_augment 。
import nvidia.dali.auto_aug.trivial_augment as ta
@pipeline_def(batch_size=8, num_threads=4, device_id=0,
enable_conditionals=True)defpipeline():
encoded, _ = fn.readers.file(file_root=data_path, random_shuffle=True)
shape = fn.peek_image_shape(encoded)
image = fn.decoders.image(encoded, device="mixed")
distorted = ta.apply_trivial_augment(augmentations, image, shape=shape, fill_value=0)return distorted

使用 DALI 的自动增强性能
现在,将 DALI 和 AutoAugment 插入模型训练并比较吞吐量,以 EfficientNet-b0 为例,改编自 NIVDIA 深度学习示例。 AutoAugment 是 EfficientNet 系列模型预处理阶段的标准部分。
在链接示例中,AutoAugment 策略使用 PyTorch 数据加载器实现并在 CPU 上运行,而模型训练在 GPU 上进行。 当 DALI 管道取代运行在 CPU 上的数据加载器时,吞吐量会增加。 DALI 示例中提供了 EfficientNet 和 DALI 的源代码。
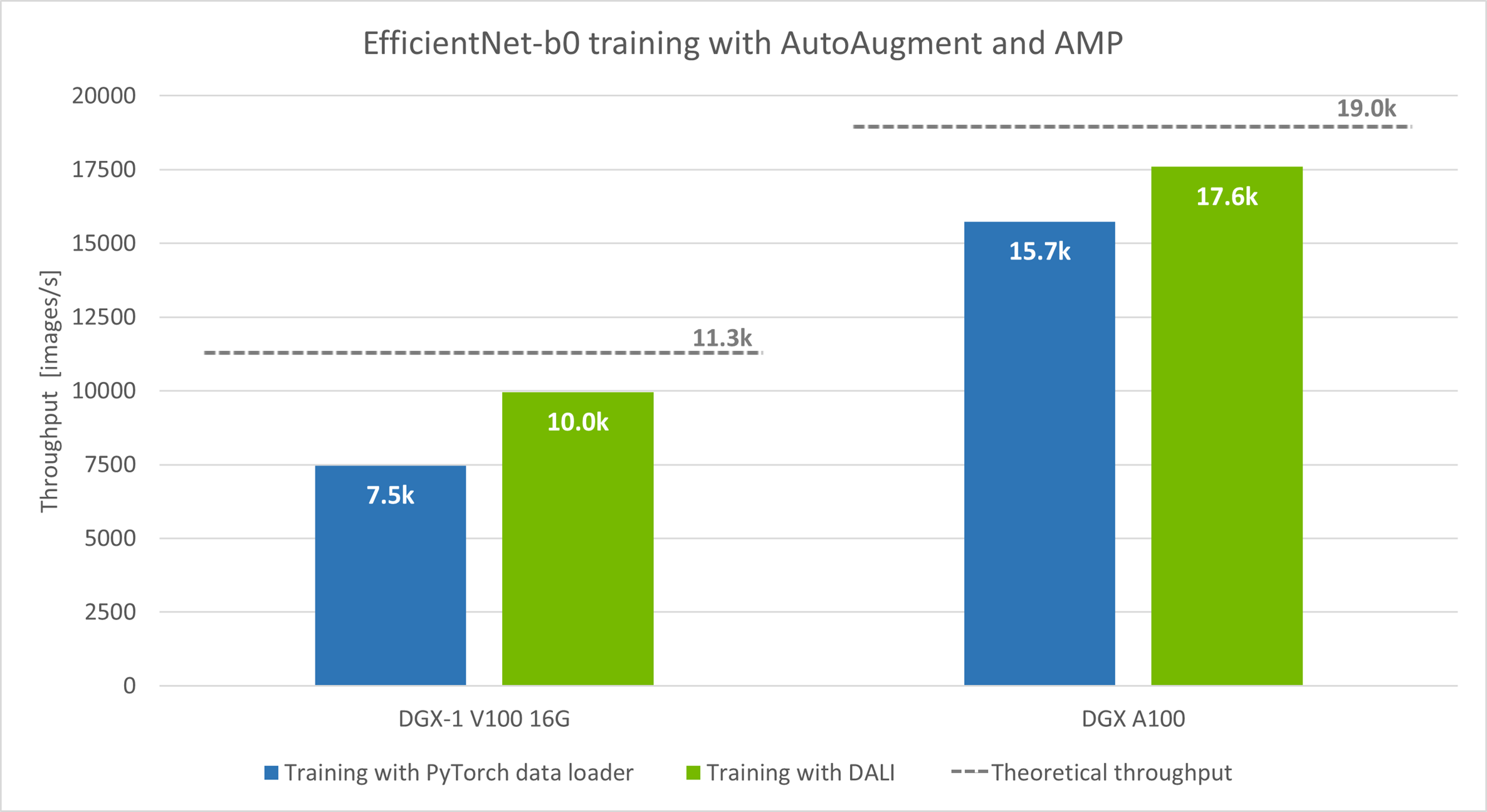
该模型以自动混合精度模式 (AMP) 运行,批量大小:DGX-1 V100 为 128,DGX A100 为 256。
我们使用两种硬件设置运行实验:DGX-1 V100 16 GB 和 DGX A100。 我们测量了每秒处理的图像数量(越多越好)。 在这两种情况下,速度都提高了:DGX-1 V100 提高了 33%,DGX A100 提高了 12%。
图中虚线表示的理论吞吐量是仅通过改进数据预处理可以预期的训练速度的上限。 为了衡量理论极限,我们使用在每次迭代中重复的单批合成数据而不是真实数据来运行训练。 这让我们看看在不需要预处理的情况下模型处理批次的速度有多快。
综合案例和 CPU 数据加载器案例之间的显着性能差距表明存在预处理瓶颈。 要验证假设,请查看训练期间的 GPU 利用率。
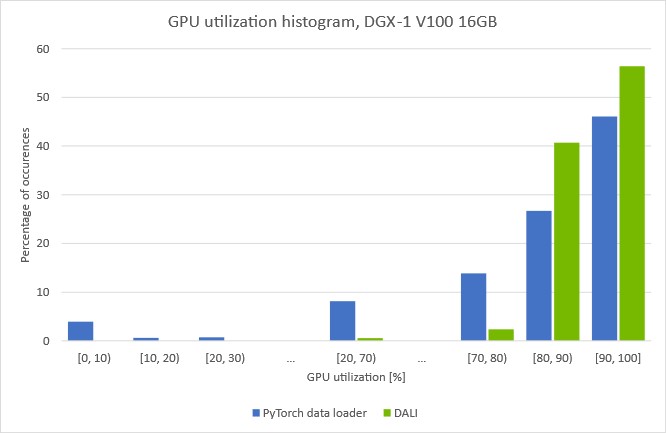
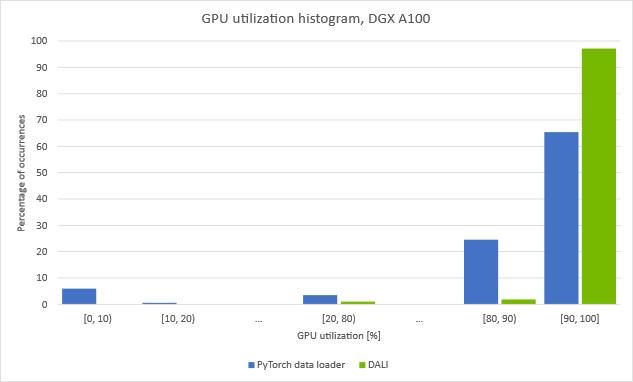
这些图显示了我们在给定 GPU 利用率上花费了多少时间。 您可以看到,当使用在 CPU 上运行的数据加载器对数据进行预处理时,GPU 利用率会反复下降。 值得注意的是,在大约 5% 的时间里,利用率下降到 10% 以下。 这表明训练有规律地停止,等待下一批从数据加载器到达。
如果使用 DALI 将加载和自动增强步骤移至 GPU,则 [0, 10] 条消失并且整体 GPU 利用率增加。 图 6 中显示的使用 DALI 的训练吞吐量增加证实我们设法克服了之前的预处理瓶颈。
有关如何发现和解决数据加载瓶颈的更多信息,请参阅案例研究:带有 DALI 的 ResNet-50。
尝试使用 DALI 进行自动增强
您可以下载最新版本的预构建和测试 DALI pip 包。 您会发现 DALI 已集成为 NVIDIA NGC 容器的一部分,适用于 TensorFlow、PyTorch、PaddlePaddle 和由 Apache MXNet 提供支持的 NVIDIA 优化深度学习框架。 DALI Triton 后端是 NVIDIA Triton 推理服务器容器的一部分。
有关新 DALI 功能和增强功能的更多信息,请参阅 DALI 用户指南示例和最新的 DALI 发行说明。
版权归原作者 扫地的小何尚 所有, 如有侵权,请联系我们删除。