2024年AI辅助研发:科技创新的引擎
2024的AI辅助研发的扩展相关信息
人工智能|机器学习——DBSCAN聚类算法(密度聚类)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,簇集的划定完全由样本的聚集程度决定。聚集程度不足以构成簇落的那些样本视为噪声点,因此DBSCAN聚类的方式也可以用于异常点的检测。
深入了解神经网络:构建人工智能的基石
这篇博客将为您解释神经网络的构造,让您能够理解这个令人着迷的领域的基本工作原理。神经网络是人工智能领域的关键技术,它们的构造基于神经元的灵感,并结合了数学、统计和机器学习的原理。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。较好的方法就是预先设定几个可选值,通过切
支撑开源LLM大模型的私有化部署,需要单机多个不同型号GPU混合使用的同学看过来
不同型号GPU混合使用;LLM大模型;多GPU;cuda;cudnn;nvidia-smi;2张rtx3090+2张rtx4090
是真的免费!企业 AI 学习指南:Azure 2024 年机器学习版
例如,训练机器学习模型的一个常见问题是缺乏足够的数据。使用 MLOps 和 Azure 机器学习扩展您的 AI/ML 实践:与 Seth Juarez 和众多嘉宾一起观看由三部分组成的系列,了解如何使用 Azure 为 AI 和 ML 提供支持。快加入我们的企业AIGC大模型落地交流社群,您将与各行
异常检测模型:SparkMLlib库的异常检测模型
1.背景介绍异常检测模型是一种常用的数据分析和预测方法,用于识别数据中的异常点。在许多应用中,异常检测模型可以帮助我们发现数据中的潜在问题,从而提高数据质量和预测准确性。本文将介绍SparkMLlib库中的异常检测模型,包括其背景、核心概念、算法原理、实际应用场景和最佳实践等。1. 背景介绍异常检测
分析开源机器学习框架TensorFlow
TensorFlow是一个开源的机器学习框架,由Google开发和维护。它提供了一个灵活的编程环境,可用于构建和训练各种机器学习模型。
LNS(大规模大邻域搜索)(含AI创作)(背景与VNS相同)
一个好的初始解可以加速算法的收敛,而一个差的初始解可能需要更多的搜索时间才能找到更优的解。:在LNS的搜索过程中,通常会对当前解进行扰动以引入新的变化,并尝试在扰动后的解空间中寻找更优的解。通过使用大型的邻域结构和灵活的搜索策略,LNS能够在相对较短的时间内找到高质量的解,因此在实际应用中具有广泛的
论文已提交,如何添加或修改作者名单?(附信件模板)
不管这篇论文是已经提交在审稿阶段,还是文章已被接受在Proof阶段,再或者是已经在线发表了,都可以尝试联系期刊进行作者名单修改。在这封信中,应详细说明需要进行变更的原因,并请求编辑对这一变更予以批准。科研论文变更作者名单是一件非常严肃的事情,大家投稿之前一定要再三确认好作者名单,避免出现更改作者的情
政安晨:【完全零基础】认知人工智能(五)【超级简单】的【机器学习神经网络】 —— 数据训练
作为这个系列文章的最后一篇,咱们先回顾一下建立神经网络的整体步骤,以实现对机器学习神经网络的整体认知。数据训练部分的目的是通过大量的数据和反向传播算法来调整网络参数,使得网络能够学习到输入数据的特征和模式,从而实现对未知数据的准确预测或分类。在人工智能领域中,机器学习神经网络的数据训练部分是指通过将
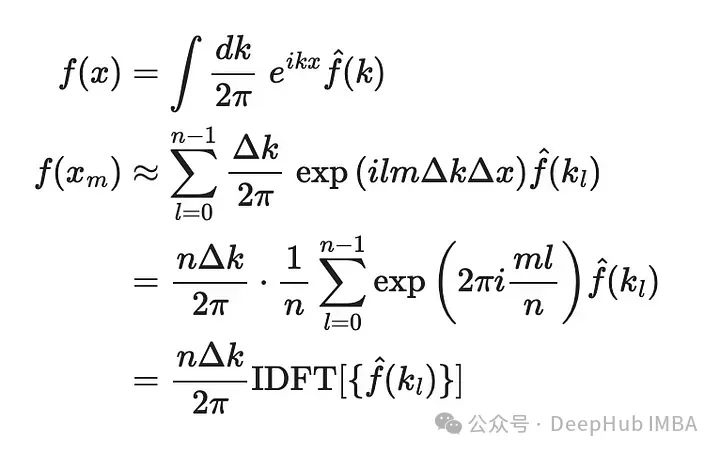
傅里叶变换算法和Python代码实现
本篇文章我们将使用Python来实现一个连续函数的傅立叶变换。
人工智能|机器学习——基于机器学习的舌苔检测
基于机器学习的舌苔检测
Gradio快速搭建机器学习模型的wedui展示用户界面/深度学习网页模型部署
在上面的示例中,我们看到了一个相对简单的函数,但该函数可以是从音乐生成器到税收计算器再到预训练机器学习模型的预测函数的任何函数。✍️提示:在本地开发时,您可以在热重载模式下运行 Gradio 应用程序,只要您对文件进行更改,该模式就会自动重新加载 Gradio 应用程序。现在,世界各地的任何人都可以
大模型训练部署利器--开源分布式计算框架Ray原理介绍
本文介绍了分布式计算框架Ray的原理。
人工智能在测绘行业的应用与挑战
AI技术在测绘行业的应用前景广阔,不仅可以提高数据处理的效率和精度,还能开启新的服务和应用。随着AI技术的不断发展,测绘行业的专业人员需不断学习和适应新技术,同时政府和行业组织需要制定相应的政策和标准,以确保技术的健康发展和正确应用。通过合理的规划和管理,测绘行业可以充分利用AI带来的机遇,同时有效
AI机器学习:让计算机自学成才的神奇技术
本文将为您揭示AI的机器学习技术,让您了解如何让计算机系统通过数据来学习和改进性能,而不需要显式地编程。介绍监督学习、无监督学习和强化学习等不同类型的学习方式,以及它们在实际应用中的巨大潜力。通过本文,您将了解到AI机器学习如何让计算机自学成才,开启智能科技的新篇章。
人工智能、机器学习、深度学习的关系、智能分类的执行流程、IK分词器的使用
人工智能与机器学习人工智能与机器学习谈谈人工智能人工智能),英文缩写为AI。它是研究开发用于模拟延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语
AI辅写疑似度:探索Perplexity与Burstiness的奥秘
适中的Perplexity值和较低的Burstiness值有助于判断AI写作助手生成文本的质量和自然度。本文将深入解析这两个指标,探讨它们在AI写作助手疑似度评估中的角色,并解答“AI辅写疑似度多少不通过”的问题。在AI写作助手的疑似度检测中,不同的工具和平台可能会设定不同的疑似度阈值。因此,了解不
从新能源汽车行业自动驾驶技术去看AI的发展未来趋势
自动驾驶汽车关键技术主要包括与以及与等。这是AI在汽车行业中应用最广泛的领域之一。自动驾驶技术利用AI算法和传感器来感知环境、识别障碍物,并进行自主决策和驾驶操作。通过实现车辆的自动驾驶,可以提高行车安全性、减少交通事故的发生,同时降低驾驶员的工作负担。,在21世纪已有数十年的历史,但自动驾驶行业在
开源计算机视觉库opencv-python详解
OpenCV-Python是一个非常强大的工具,它为计算机视觉任务提供了一个丰富的函数库。通过结合深度学习和其他机器学习技术,OpenCV-Python可以用于解决复杂的问题,如图像识别、物体检测、人脸识别等。随着技术的发展,OpenCV-Python也在不断更新和改进,以支持更多的功能和算法。Op



